bloomfilter专题

BloomFilter原理和使用
文章目录 BloomFilter原理和使用BloomFilter原理适用场景基础性质False-Positive推导 Bloom Filter之python包pybloomfilter pybloomfilter代码实例 BloomFilter原理和使用 BloomFilter原理 适用场景 在很多场景下,会遇到流式元素的处理,最主要的是集合判断与去重问题。例如我们会判断一

自己手写一个BloomFilter
1.什么是BloomFilter 布隆过滤器 布隆过滤器用于判断一个元素是否在一个集合中,它有一定的误判率,不存在的元素,一定不存在。存在的不一定真的存在, 它使用的是数组,它的空间效率是一般算法的1/8左右 2.BloomFilter 的核心思想是什么? 布隆过滤器的核心思想: add 操作: 计算k个hash函数的值,把对应的结果映射到位数组上,将相应的位数

使用Google BloomFilter 对爬虫url集进行去重
生成 url 文件 #!/usr/bin/env bashfile='./bigFile.txt'urlPre='https://blog.csdn.net/u010979642/'[ $1 ] && count=$1 || count=10for num in $(seq 1 ${count})do# 随机生成 count 以内的随机数randomNum=$(($RANDOM%${cou

Hadoop的Reduce Join+BloomFilter实现表链接
[b][color=green][size=large]散仙,在上篇文章中了,测了使用半链接的方式,来实现的表join,注意中间存储小表的key,是用HashSet实现的,也就是把数据存在内存里,在map侧,进行key过滤后,然后再Reduce侧,实现join,但如果数据量非常大的情况下,HashSet来存放海量的key可能就会出现OOM的情况,这时候,我们就可以采用另一种join方式,也就是今天
BloomFilter与redis联合去重的python的代码
我们在爬大型网站的时候,需要处理上千万乃至上亿的url的去重。如果采用python的自带set,或者redis的set,那就需要占用很大的内存。如果存入将url存入数据库去重,那速度又会变慢。这种量级以上的去重,一般是采用BloomFilter,但是如果机器down机了,那BloomFilter在内存的数据中的数据,就没了。我们知道redis的数据既可以存在内存中,也可以存在硬盘中。如果能将B
BloomFilter和BitMap的介绍与使用
文章目录 一、BloomFilter1、是什么?2、BloomFilter的使用 二、Bitmap1、是什么?2、Bitmap的使用 三、总结1、区别2、遇到问题:OOM command not allowed when used memory > 'maxmemory'. 一、BloomFilter 1、是什么? BloomFilter是一种概率型数据结构,用于判断一个元素

ceph存储 BloomFilter大规模数据处理利器
Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。 一. 实例 为了说明Bloom Filter存在的重要意义,举一个实例: 假设要你写一个网络蜘蛛(web crawler)。由于网络间的链接错综复杂,蜘蛛在网络间爬行很可能会形成“环”。为了避免形成“
【bloom filter】对HBase中Bloomfilter类型的设置及使用的理解
转载:http://zjushch.iteye.com/blog/1530143 1.Bloomfilter的原理? 可参考 http://hi.baidu.com/yizhizaitaobi/blog/item/cc1290a0a0cd69974610646f.html 2.Bloomfilter在HBase中的作用? HBase利用Bloomfilter来提高随机读(Get)的
Redis HBase Es HyperLogLog与BloomFilter笔记
什么是布隆过滤器? 它实际上是一个很长的二进制向量和一系列随机映射函数。把一个目标元素通过多个hash函数的计算,将多个随机计算出的结果映射到二进制向量的位中,依次来间接标记一个元素是否存在于一个集合中。布隆过滤器可以做什么? 布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。布隆过滤器特点 如果布隆过滤器显示一个
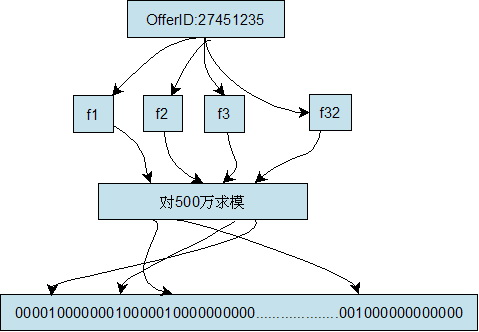
BloomFilter 简介及在 Hadoop reduce side join 中的应用
1、BloomFilter能解决什么问题? 以少量的内存空间判断一个元素是否属于这个集合, 代价是有一定的错误率 2、工作原理 1. 初始化一个数组, 所有位标为0, A={x1, x2, x3,…,xm} (x1, x2, x3,…,xm 初始为0) 2. 将已知集合S中的每一个数组, 按以下方式映射到A中
Hbase中的BloomFilter(布隆过滤器)
(1) Bloomfilter在hbase中的作用 Hbase利用bloomfilter来提高随机读(get)的性能,对于顺序读(scan)而言,设置Bloomfilter是没有作用的(0.92版本以后,如果设置了bloomfilter为rowcol,对于执行了qualifier的scan有 一定的优化) (2) Bloomfilter在hbase中的开销