beautifulsoup4专题

BeautifulSoup4通过lxml使用Xpath定位实例
有以下html。<a>中含有图片链接(可能有多个<a>,每一个都含有一张图片链接)。最后一个<div>中含有文字。 上代码: import requestsfrom bs4 import BeautifulSoupfrom lxml import etreeurl='https://www.aaabbbccc.com'r=requests.get(url)soup = Beauti

BeautifulSoup4和JsonPath
BeautifulSoup4和JsonPath 文章目录 BeautifulSoup4和JsonPathBeautifulSoup4遍历文档树搜索文档树CSS选择器 Json解析 BeautifulSoup4 BeautifulSoup可以从HTML、XML中提取数据,目前BS4在持续开发。 官方中文文档https://www.crummy.com/software/Be

Python3网络爬虫教程15——BeautifulSoup4中的编码,格式化,解析器的区别
上接: Python3网络爬虫教程14——BeautifulSoup4之搜索文档树 https://blog.csdn.net/u011318077/article/details/86633433 5.5. 格式化输出 prettify() 方法将Beautiful Soup的文档树格式化后以Unicode编码输出, 每个XML/HTML标签都独占一行 如下示例 markup = ‘I

Python3网络爬虫教程14——BeautifulSoup4之搜索文档树
上接: Python3网络爬虫教程13——BeautifulSoup4基本使用及遍历文档树 https://blog.csdn.net/u011318077/article/details/86633392 5.3. 搜索文档树 5.3.1. 过滤器 find_all() find_all() 方法将返回文档中符合条件的所有tag 过滤器 过滤器可以被用在tag的name中,节点的属
Python3网络爬虫教程13——BeautifulSoup4基本使用及遍历文档树
上接: Python3网络爬虫教程12——页面解析及正则表达式的使用 https://blog.csdn.net/u011318077/article/details/86633330 5. BeautifulSoup4使用 BeautifulSoup4官方文档地址: https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/#id7几个常用提取信息工

windows下Python3配置beautifulsoup4
Python3配置beautifulsoup4 网上很多教程都是基于python2.7*,python3的资料较少,而bs4在windows下一直无法安装,网上教程误导偏多,特总结如下: 1,python3中自带pip,只需将路径添加到 PATH 环境变量中去。 2,保证网络畅通。cmd中运行命令:pip BeatutifulSoup4 install 3,搞定。

python3.6+BeautifulSoup4 爬取360手机助手app应用的信息并存储数据库 批量下载apk
源码: #/usr/bin/python#encoding:utf-8'''Created on 2018年01月12日@author: xianqingchen'''import requestsfrom bs4 import BeautifulSoupimport osfrom urllib.request import urlopenimport pymysqldef
Beautifulsoup4的使用
一 介绍 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.你可能在寻找 Beautiful Soup3 的文档,Beautiful Soup 3 目前已经停止开发,官网推荐在现在的项目中使用Beautiful Soup 4,
ubuntu/linux pyhton3.x 安装pip、requests、bs4 BeautifulSoup4
安装pip sudo apt-get install python3-pip 安装requests sudo pip3 install requests --upgrade 安装BeautifulSoup4 sudo pip install BeautifulSoup4
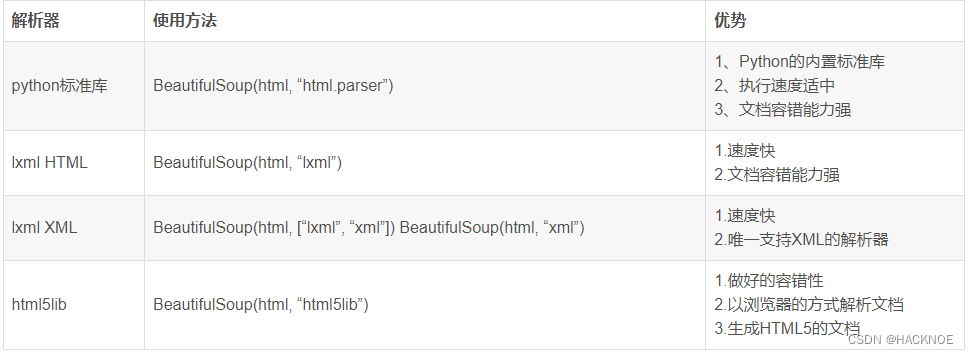
python从入门到精通(十六):python爬虫的BeautifulSoup4
python爬虫的BeautifulSoup4 BeautifulSoup4导入模块解析文件创建对象python解析器beautifulsoup对象的种类Tag获取整个标签获取标签里的属性和属性值Navigablestring 获取标签里的内容BeautifulSoup获取整个文档Comment输出的内容不包含注释符号BeautifulSoup文档遍历BeautifulSoup文档搜索
from beautifulsoup4 import BeautifulSoup 报错
>>> from beautifulsoup4 import BeautifulSoup Traceback (most recent call last): File "<stdin>", line 1, in <module> ModuleNotFoundError: No module named 'beautifulsoup4' 解决方法,重新执行了 pip install

BeautifulSoup4使用
使用文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id32

可狱可囚的爬虫系列课程 07:BeautifulSoup4(bs4)库的使用
前面一直在讲 Requests 模块如何使用,那都是在请求阶段要做的事情,相信很多网友都在等一个能够开始爬网站信息的教程,今天它来了,今天我要给大家讲一个很简单易懂的库:BeautifulSoup4。 一、概述&安装 BeautifulSoup4 属于 BeautifulSoup 系列的第四代版本,BeautifulSoup 是一个可以从 HTML 或 XML 文件中提取数据的 Python
可狱可囚的爬虫系列课程 07:BeautifulSoup4库的使用
前面一直在讲 Requests 模块如何使用,那都是在请求阶段要做的事情,相信很多网友都在等一个能够开始爬网站信息的教程,今天它来了,今天我要给大家讲一个很简单易懂的库:BeautifulSoup4。 一、概述&安装 BeautifulSoup4 属于 BeautifulSoup 系列的第四代版本,BeautifulSoup 是一个可以从 HTML 或 XML 文件中提取数据的 Python
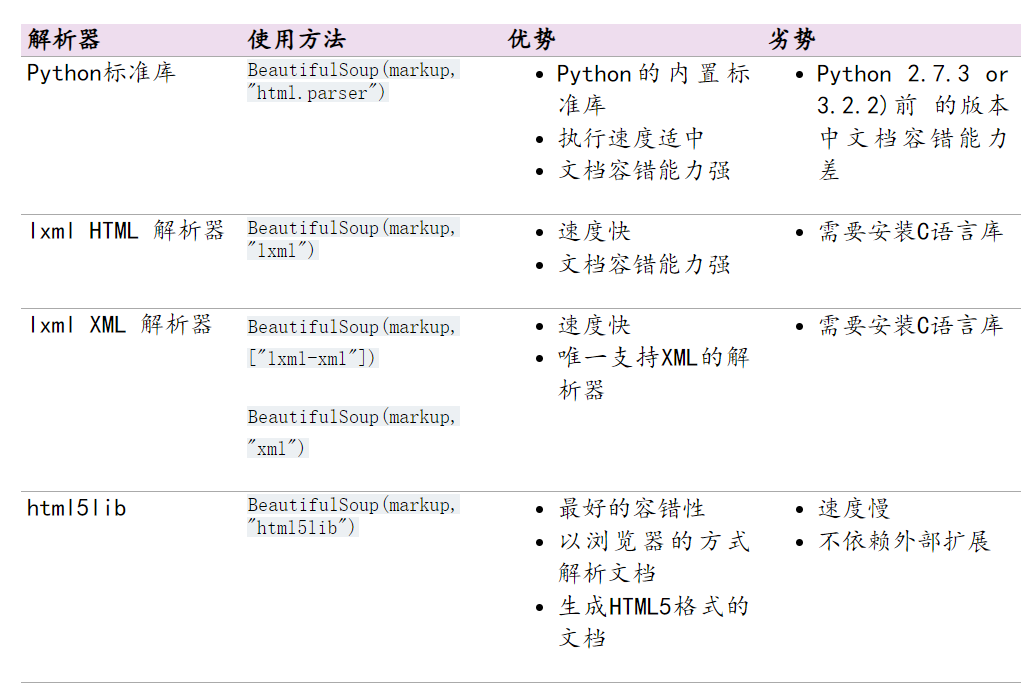
六:爬虫-数据解析之BeautifulSoup4
六:bs4简介 基本概念: 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据官方解释如下: '''Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。''' Beautiful

BeautifulSoup4模块的使用
在day13下创建一个名为01-BeautifulSoup4模块的使用的代码文件 上一期我们获取了网页源代码,本期就从网页源代码这里提取我们想要的信息。 一、BeautifulSoup4概述 BeautifulSoup是一个用于从HTML文件(说白了就是HTML文件里写的前端代码)中提取数据的模块。使用BeautifulSoup模块,你就可以从HTML中提取到你想要的任何数据。Beaut

学习BeautifulSoup4(1)
BeautifulSoup4 参考中文文档:BeautifulSoup4 简介 Beautiful Soup是一个可以从HTML或者XML文件中提取数据的Python库。可以通过选择转换器来实现惯用的文档导航,查找,修改文档的方式。Beautiful Soup可以帮助我们节省数小时设置数天的工作时间。 安装Beautiful Soup 如果是在Debian或者ubuntu下,可以通过系统

Ubuntu系统上Python2和Python3共存时安装BeautifulSoup4
问题 我的电脑安装的系统为Ubuntu 14.04,同时安装有python 2.7.6和python 3.4.0,我需要在python 3.4.0上面安装BeautifulSoup4,而直接采用下面命令: sudo apt-get install python-bs4 则将BeautifulSoup4安装在了python 2.7.6上面。采用什么方法将其安装在与python2.7.6共存的p

Python中利用BeautifulSoup4反查包含文本内容的标签
目录 1 问题引出2 问题分析3 解决方案 1 问题引出 编写爬取Amazon服装行业数据时,遇到一个问题:根据文本内容Next反查包含它的父标签。请看下面HTML片段 <li class="a-last"><a href="/s?k=red+tshirt&i=fashion-mens&page=2&qid=1588904638&ref=sr_