本文主要是介绍学习BeautifulSoup4(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
BeautifulSoup4
参考中文文档:BeautifulSoup4
简介
Beautiful Soup是一个可以从HTML或者XML文件中提取数据的Python库。可以通过选择转换器来实现惯用的文档导航,查找,修改文档的方式。Beautiful Soup可以帮助我们节省数小时设置数天的工作时间。
安装Beautiful Soup
- 如果是在Debian或者ubuntu下,可以通过系统的软件包管理来安装:
$ apt-get install Python-bs4
Beautiful Soup4通过PyPi发布的,如果没法使用系统包管理安装,也可以通过easy_install或pip来安装,包的名字是beautifulsoup4,它兼容Python2和Python3。
$ easy_install beautifulsoup4
$ pip install beautifulsoup4
现在基本安装使用beautifulsoup4,虽然PyPi里有BeautifulSoup,不过那个是Beautiful Soup3版本的,因为之前的很多项目都用到它,所以它仍然有效,不过bs3已经停止开发了。
如果没有安装esay_install或pip,可以下载BS4的源码,然后通过setup.py来安装:
$ Python setup.py install
- 在Windows下,可以直接通过dos界面或者在pycharm里通过Terminal来安装。
D:\Python>pip install beautifulsoup4
D:\Python>esay_install install beautifulsoup4
通过pip list查看已经安装的库:

安装解析器
Beautiful Soup支持Python标准库自带的HTML解析器(html.parser),还支持一些第三方的解析器:lxml
安装lxml:
$ apt-get install Python-lxml
$ esay_install lxml
$ pip install lxml
还有一个可以选择的解析器是纯Python实现的html5lib,html5lib的解析方法和浏览器相同,安装:
$ apt-get install Python-html5lib
$ easy_install html5lib
$ pip install html5lib
以下是各种解析器的优缺点比较:
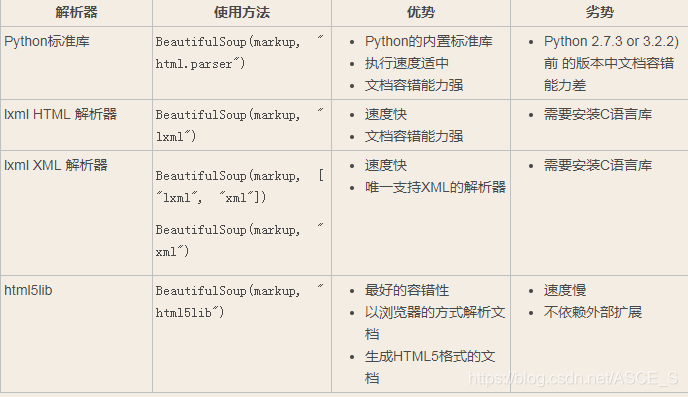
推荐使用lxml解析器,速度快。
简单的使用
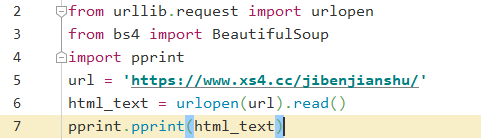
这里以访问全书网为例,使用urlopen()发起对网页的请求,如果不添加read(),则打印的是描述代码:

添加read(),以可阅读的形式打印出来:
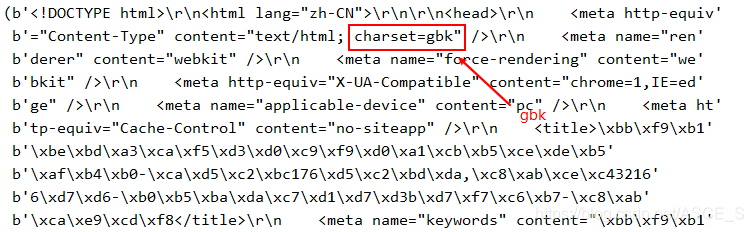
注意,网页编码是gbk,是中文编码集,而pycharm里的编码我设置为utf-8,所以中文显示都是\xbe\xa3这样的。
接着把文档,也就是刚刚解析到的html_text传入BeautifulSoup构造方法,就可以得到一个文档的对象,当然还可以传入一段字符串或者是文件句柄。
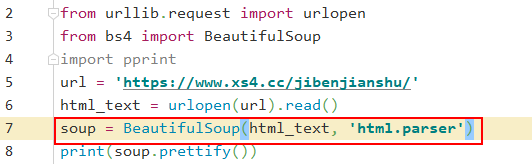
传入构造方法的字符串都会被转为unicode编码。第二个参数可以指定解析器,不指定的话,bs4会自己选择最合适的解析器。

查看输出的soup类型:
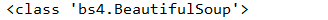
这是BeautifulSoup的自定义类型,后面会详细介绍。

格式化输出结果:
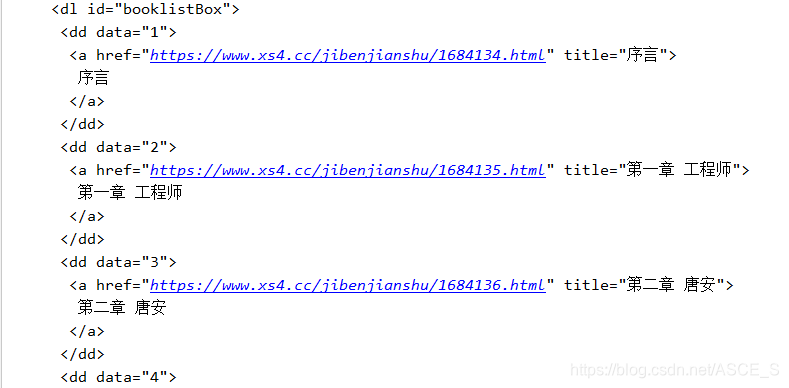
以上就是网页的部分内容了。
对象的种类
BeautifulSoup把复杂的html文档(就是刚刚解析到的html_text)转换成一个复杂的树形结构,树的每个节点都是Python对象,对象可以归纳位4种:Tag,NavigableString,BeautifulSoup,Comment.
- Tag
Tag对象与xml,html中的tag一样:

以上的div,ul都是tag.
相比于用正则表达式去匹配标签等内容,BeautifulSoup的方法更简单一些:
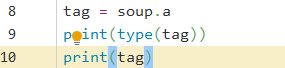
只需要在对象(soup)后面跟上标签即可,不过这样只能匹配到第一个符合条件的标签。
输出:

Tag中有两个最重要的属性:name,和,attributes
-
Tag.name
每个Tag都有自己的名字,可以通过Tag.name来获取:

输出:

也可以修改tag.name,这样会修改BS对象生成的文档:

输出:
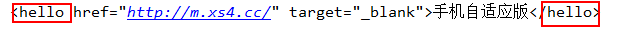
-
Tag.attributes
一个标签可能有多个属性:

其中content, http-quiv均是meta标签的属性,他们的值分别为等号后双引号里的内容。
对标签的属性操作方法和字典一样:

输出:

第一种列出指定属性的值;第二种列出该标签的所有属性和值。
其中content又称为多值属性,一个属性对应两个值,多值属性的返回类型是list. -
NavigableString
字符串被包含在tag内。Beautiful Soup用NavigableString类来包装tag中的字符串。

输出:

tag.string包含标签(title)的内容。
tag中包含的字符串不能被编辑,但是可以通过replace_with()方法替换:

输出:

-
Beautiful Soup
BeautifulSoup对象表示一个文档的全部内容,它不是真正意义上的tag,但是可以看成一个特殊的tag。
输出:
-
Comment
Comment是一个特殊类型的NavigableString对象:
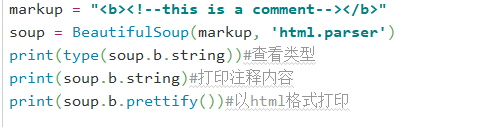
输出:
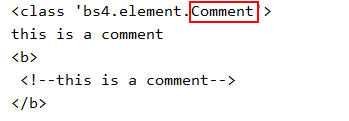
这是一个注释字符串,通过string会把注释内容直接打印出来,不过通常我们不需要注释,这只是为了帮助我们理解代码用的。
这里通过一个简单的判断,判断标签内容是否是注释:

输出:

前面说过Beautiful Soup把复杂的HTML文档转为复杂的数结构,所以接下来的遍历,搜索,修改都是针对树的操作。
遍历文档树
-
1.子节点
一个Tag里可能会包含多个字符串或者是多个Tag,他们都是Tag的子节点。
注意:字符串没有子节点-
通过tag的名字遍历文档:
相比于正则表达式,我们只要给出标签名字就可以了:

部分输出:
如果Tag里还包含有Tag,可以继续通过 '.'来访问:

输出:

不过,这种访问方法只能找到第一个匹配的Tag,如果要匹配所有Tag,可以使用方法
find_all():

部分输出:
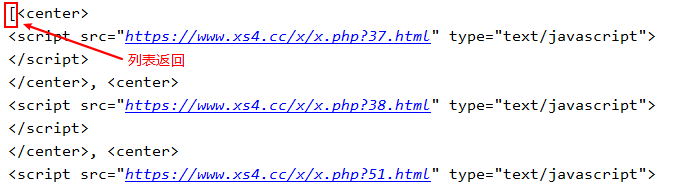
输出结果是列表形式的。 -
.contents和.children

输出:

返回类型是列表,注意还包含换行符。
以列表形式访问:
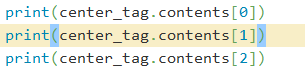
输出包括换行符:
BeautifulSoup对象(soup)本身也包含子节点,标签就是他的子节点:

输出:
通过.children生成器对Tag子节点进行遍历:

部分输出:

-
.descendants
.children和.contents仅仅包含tag的直接子节点,而子节点下可能还有子节点或是字符串,
可以通过.descendtants来对子节点进行递归循环:

输出:
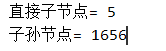
-
.string
如果一个tag仅仅含有一个子tag,可以用.string得到子节点的内容:

输出:

如果一个tag仅仅含有一个NavigableString 类型的子节点,那么该字符串也可以用.string 得到:

输出:
如果有多个子节点,则不能通过这种方法得到子节点,.string无法确定是哪一个子节点, 结果是None:

输出:

-
.strings和.stripped_strings
如果tag中包含多个字符串,可以用.strings来获取:

输出:

如果输出的字符串包含多个空格或空行,用.stripped_strings可以去除空白内容:

输出:

-
-
2.父节点
- .parent
获取某个元素的父节点。
- .parent
print(soup.p)
#<p>
# 基本剑术有声小说 无弹窗-收录176章节,全文32166字-暗黑茄子b作品-全书网
#</p>
获取p标签的父标签title
print(soup.p.parent)
#<title>
# <p>
# 基本剑术有声小说 无弹窗-收录176章节,全文32166字-暗黑茄子b作品-全书网
# </p>
#<br/>
#<br/>
#</title>
Beautiful Soup对象的父亲是None:
print(soup.parent)
#None
- .parents
递归得到某个元素的所有父辈节点:
for parent in soup.p.parents:print(parent)
#<title>
#<p>
# 基本剑术有声小说 无弹窗-收录176章节,全文32166字-暗黑茄子b作品-全书网
# </p>
#<br/>
#<br/>
#</title>
- 3.兄弟节点
.next_sibling 和 .previous_sibling
<meta content="no-siteapp" http-equiv="Cache-Control"/><title>基本剑术有声小说 无弹窗-收录176章节,全文32166字-暗黑茄子b作品-全书网</title><meta content="基本剑术,基本剑术有声小说," name="keywords"/>
meta和title标签属于同一层:他们是同一个元素的子节点,所以和是兄弟节点,兄弟节点有着相同的缩进级别。
meta标签的下一个不是title标签,而是他们之间的换行符:
print(soup.meta.next_sibling)
#输出为空行
soup.meta.next_sibling
#'\n'
print(soup.meta.next_sibling.next_sibling)
#<title>
# 基本剑术有声小说 无弹窗-收录176章节,全文32166字-暗黑茄子b作品-全书网
# </title>
.next_siblings 和 .previous_siblings
可以对元素的兄弟节点进行迭代输出。
- 4.回退和前进
<title><p>基本剑术有声小说 无弹窗-收录176章节,全文32166字-暗黑茄子b作品-全书网</p>
</title>
HTML解析器会把该字符串转为一系列的事件:打开title标签,打开p标签,添加一段字符串,关闭p标签,关闭title标签。BeautifulSoup重现了HTML解析器的工作过程。
.next_element 和 .previous_element
这两个属性分别指向下一个/上一个解析过程中被解析的对象。
.next_elements 和 .previous_elements
for element in soup.title.next_elements:print(element)
输出
总结下输出方式:
-
格式化输出
prettify()将BS文档树格式化后以Unicode编码输出,每个xml/html标签都独占一行:

输出:

-
压缩输出
如果不重视输出格式,可以使用unicode()或str()方法:
注意:unicode()方法在python3中已经改为str()方法。str()方法返回UTF-8编码的字符串,可以指定编码;
-
输出格式
Beautiful Soup输出是把HTML中的特殊字符转换位Unicode,比如"&lquot":
soup = BeautifulSoup("“Dammit!” he said.")
unicode(soup)
# u'<html><head></head><body>\u201cDammit!\u201d he said.</body></html>'
如果将文档转换成字符串,Unicode编码会被转为UTF-8,就无法正确显示HTML特殊字符了:
str(soup)
# '<html><head></head><body>\xe2\x80\x9cDammit!\xe2\x80\x9d he said.</body></html>'
- get_text()
get_text()方法可以获取tag里包括子孙tag的文本内容,并将结果作为Unicode字符串返回。
print(soup.get_text())
部分结果:
<!DOCTYPE html><html lang="zh-CN">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>
<meta content="webkit" name="renderer"/>
<meta content="webkit" name="force-rendering"/>
<meta content="chrome=1,IE=edge" http-equiv="X-UA-Compatible"/>
<meta content="pc" name="applicable-device"/>这篇关于学习BeautifulSoup4(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







