本文主要是介绍BeautifulSoup4模块的使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在day13下创建一个名为01-BeautifulSoup4模块的使用的代码文件
上一期我们获取了网页源代码,本期就从网页源代码这里提取我们想要的信息。
一、BeautifulSoup4概述
BeautifulSoup是一个用于从HTML文件(说白了就是HTML文件里写的前端代码)中提取数据的模块。使用BeautifulSoup模块,你就可以从HTML中提取到你想要的任何数据。BeautifulSoup4是BeautifulSoup系列模块的第四代。
二、BeautifulSoup4模块的安装
之前说过模块的安装方式有两种:
(1)可视化安装
我们之前安装pypinyin模块的时候用到过,友友们可以回顾一下
(2)在Terminal(终端)直接敲安装命令
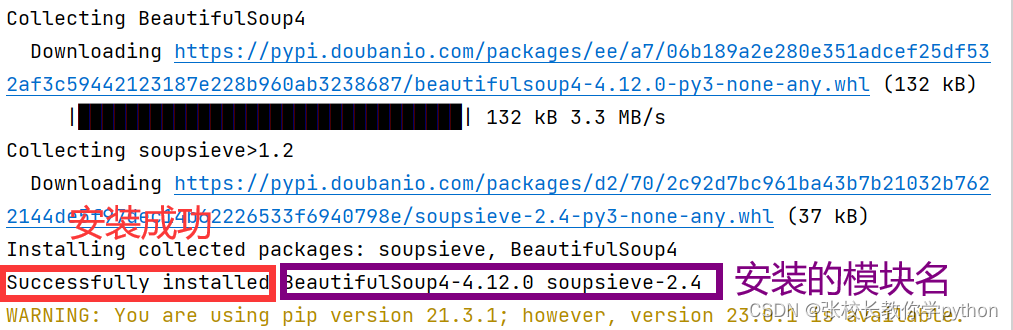
Windows系统:pip install BeautifulSoup4
Mac、linux系统:pip3 install BeautifulSoup4
本次使用直接在终端敲命令安装并以windows系统为例,打开Terminal,输入pip install BeautifulSoup4回车安装即可
三、使用
1、导包
BeautifulSoup4模块在使用的时候简称bs4,因为python爬虫这块涉及到的都是三方模块,三方模块大部分都需要安装,模块有一个功能:别人已经实现了,我们可以直接用别人实现这个功能的模块。已经安装了这个模块(bs4),所以说要告诉程序我们要的功能(BeautifulSoup4)在哪,从哪(bs4)导入什么方法/功能/模块(BeautifulSoup4)
from bs4 import BeautifulSoup
2、接下来,就要从网页源代码这里提取我们想要的信息。
(1)假设html_str就是requests拿到的字符串类型的网页源代码
回顾字符串的性质:
字符串是使用引号(单引号、双引号、三引号)作为容器符号。此处就是使用了三对双引号
html_str = """
<html><head><title>The Dormouse's story</title></head><body><p class="title"><b>The Dormouse's story</b></p><p class="story" id="story">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie<p>Test</p></a>;and they lived at the bottom of a well.</p><p class="story" id="story">...</p>
"""
PS:字符串html_str里写的是一个很简陋的前端框架(利用缩进看层次结构)
(2)针对字符串做这样一步操作:
soup = BeautifulSoup(html_str, 'html.parser')
这行代码是用来干嘛的?
1、首先对于变量soup,BeautifulSoup4模块这个官方文档写的就是soup。
2、使用BeautifulSoup方法针对于网页源代码进行文档解析,返回一个BeautifulSoup对象(树结构)。
3、解析过程需要解析器,html.parser是一个解析器。
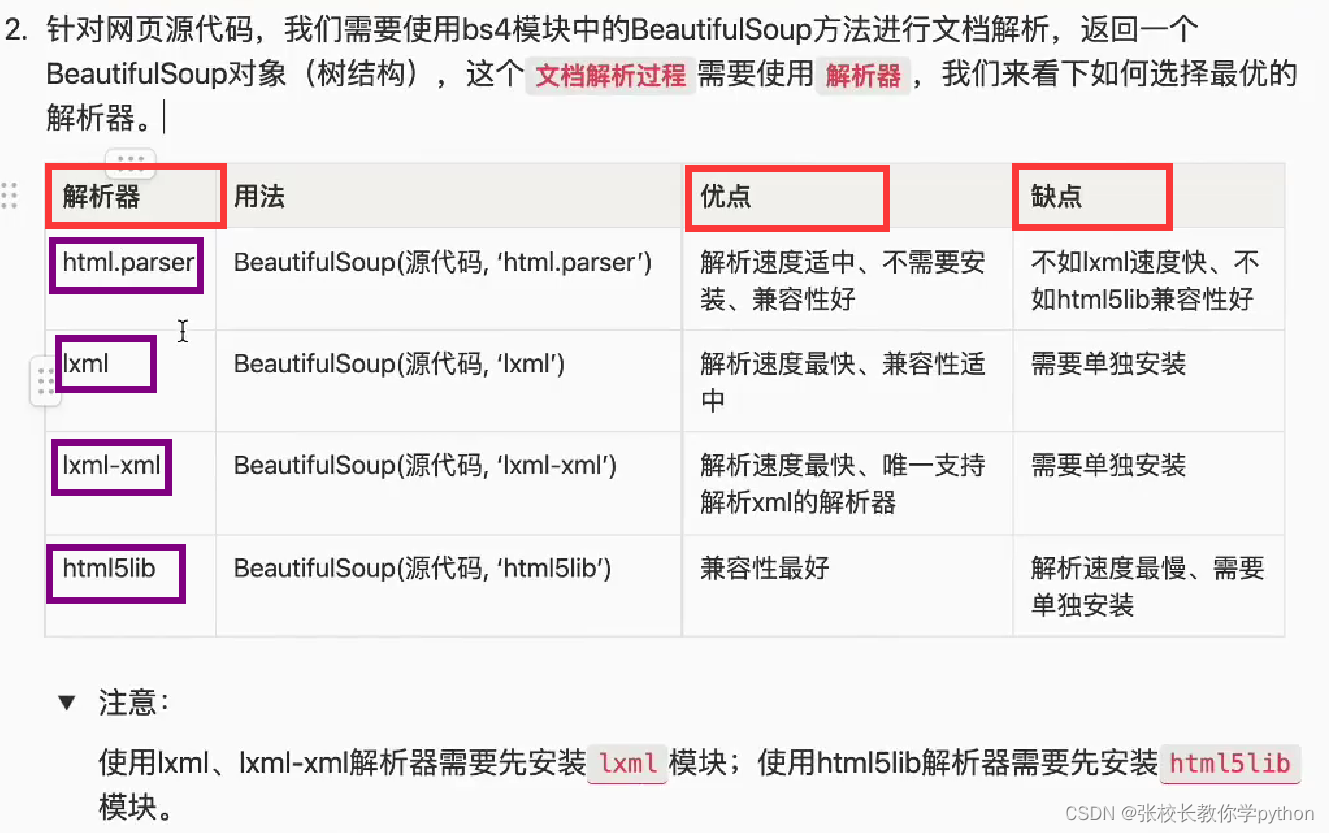
什么是树结构?
使用树结构的原因?
html网页的结构就是树结构,便于更快更方便的查找信息。
将html源代码转为了树结构
print(soup)
打印结果:
打印发现,树结构和字符串类型的源代码没区别,内容没变,只是换了一种数据类型(为了更好的查询),暂且称为BeautifulSoup类型(树结构),打印完注释掉(只是为了让大家看一下打印的结果)。

3、从网页中提、取内容的方法和属性。
select:使用CSS选择器从树结构中
遍历符合的结果,存放在列表中,列表中的每个元素依旧是树结构。(从树结构中提取一部分出来还是树结构,只不过这个树结构变小了)
CSS选择器包含标签选择器、id选择器、class选择器、父子选择器、后代选择器、nth-of-child选择器等)
select_one:使用CSS选择器从树结构中拿到
符合条件的第一个结果,这个结果依旧是树结构。
text:从树结构中
得到标签中的内容,结果为字符串。
attrs:从树结构的标签中
获得属性名对应的属性值,结果为字符串。
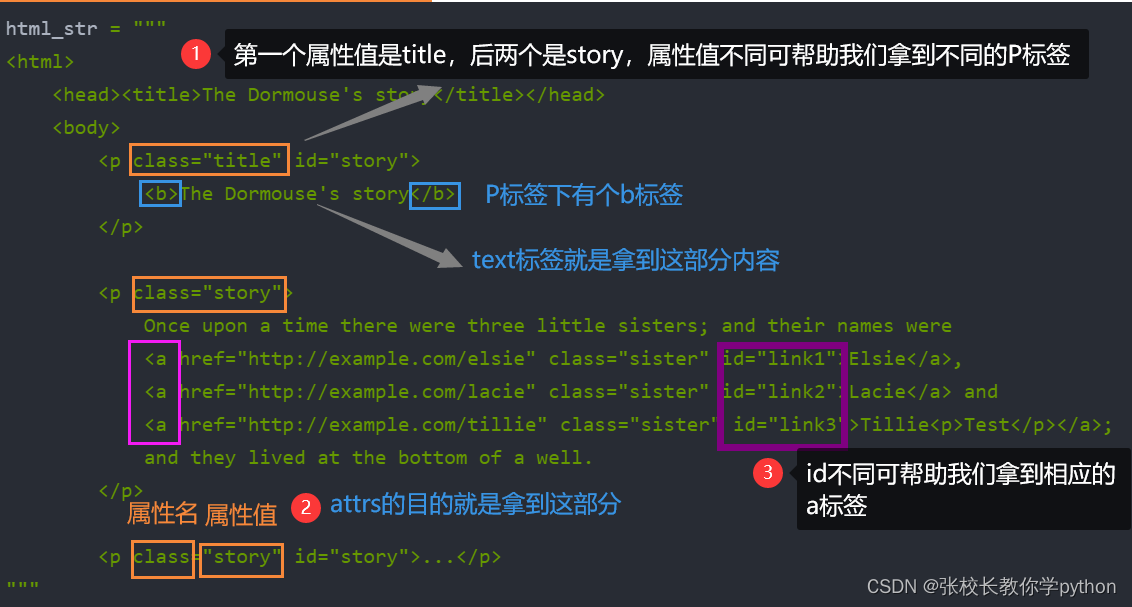
Q1:从soup这个树结构中提取所有的p标签
---->(soup这个树结构就是源代码,只需要找准P标签在哪,就可以拿到P标签)
----> 使用select(存放在列表下)
标签选择器:只写标签名,能从树结构中拿到所有的某个标签
p_list1 = soup.select('p')
print(p_list) # 第四个P标签包含在第三个里面

Q2:提取body标签下的所有p子标签
----> 使用select(存放在列表下)
什么是父什么是子?看缩进。父子关系一定是后代关系,反之不然。父子标签用 “>” 连接,右边的是子标签,左边的是父标签。执行顺序:body > p,从整个树结构soup中先找到body标签,再去找body的p子标签
CSS选择器作用:按照树结构,寻找所需要的内容。(限定条件)
p_list2 = soup.select('body > p')
print(p_list2)
打印结果:body标签下有3个p子标签(不包含后代标签)

Q3:提取body标签下的所有p标签
----> 使用select(存放在列表下)
后代选择器:祖先标签和后代标签使用空格隔开,祖先在左,后代在右。PS:父子关系一定是后代关系,后代关系不一定是父子关系。
p_list3 = soup.select('body p')
print(p_list3)
打印结果:body标签下有4个p标签(包含后代标签)

Q4:提取body标签下的第一个p子标签
class选择器,class属性对应的属性值使用点.调用。第一个P子标签对应的属性值是title,后两个P子标签对应的属性值是story
p = soup.select('body > p.title')
print(p)

Q5:提取body标签的后两个p子标签
id选择器:id属性名对应的属性值使用#调用
p_list5 = soup.select('body > p#story')
print(p_list5)

Q6:提取body标签下的第二个p子标签的第三个a子标签的标签内容和href属性值
nth-child选择器:不区分标签名,获取同级所有标签的第N个。选择器最后写的什么标签,拿到的就是什么列表,比如下方的a列表
select_one选择器:拿到的是select结果中的第一个元素
a_list = soup.select('body > p:nth-child(2) > a#link3')
print(a_list)
取body标签下的第二个p子标签:body > p:nth-child(2);第二个p子标签的第三个a子标签的标签内容:p:nth-child(2) > a#link3
----> 三个a子标签class=sister,我们发现id不同,所以利用id做文章,将三个a标签区分开

列表里面的还是树结构,接下来把这层列表给去掉。利用下标切片……就可以将列表去掉。
----> text:从树结构中得到标签中的内容,结果为字符串。
----> attrs:从树结构的标签中获得属性名对应的属性值,结果为字符串。
text_str = soup.select('body > p:nth-child(2) > a#link3')[0].text
print(text_str)# select_one拿到的是select结果中的第一个元素
# text_str2 = soup.select('body > p:nth-child(2) > a#link3').text
# print(text_str2)href_str = soup.select('body > p:nth-child(2) > a#link3')[0].attrs['href']
print(href_str)

所有的CSS选择器能够随意组合使用。
这篇关于BeautifulSoup4模块的使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






