batchnorm专题

选取训练神经网络时的Batch size ,BatchNorm
BatchNorm 优点:对于隐藏层的每一层输入,因为经过激活函数的处理,可能会趋向于大的正值和负值,容易出现梯度下降和梯度消失。所以强行拉回到服从均值为0,方差为1的标准正态分布,避免过拟合 缺点:正是因为这种强行改变分布的手段,使得隐层输入和原始数据分布差异太大,如果数据量不大时,容易欠拟合。可能不用更好一些 https://www.zhihu.com/search?type=conte

BatchNorm层的作用
而第一步的规范化会将几乎所有数据映射到激活函数的非饱和区(线性区),仅利用到了线性变化能力,从而降低了神经网络的表达能力。而进行再变换,则可以将数据从线性区变换到非线性区,恢复模型的表达能力。 代码 def Batchnorm_simple_for_train(x, gamma, beta, bn_param):"""param:x : 输入数据,设shape(B,L)param:

caffe中BatchNorm层和Scale层实现批量归一化(batch-normalization)注意事项
caffe中实现批量归一化(batch-normalization)需要借助两个层:BatchNorm 和 Scale BatchNorm实现的是归一化 Scale实现的是平移和缩放 在实现的时候要注意的是由于Scale需要实现平移功能,所以要把bias_term项设为true 另外,实现BatchNorm的时候需要注意一下参数use_global_stats,在训练的时候设为false,
Caffe Prototxt 特征层系列:BatchNorm Layer
BatchNorm Layer 是对输入进行均值,方差归一化,消除过大噪点,有助于网络收敛 首先我们先看一下 BatchNormParameter message BatchNormParameter {// If false, accumulate global mean/variance values via a moving average.// If true, use those a

【darknet】阅读理解(5)——batchnorm和activation
1. batchnorm 1.1 原理 大致的原理可以参考:https://blog.csdn.net/qq_25737169/article/details/79048516 如果了解个大概的话,就是:(x-均值)/ 偏差 * 缩放系数 + 一个偏置 1.2 darknet实现 说明: darknet cpu采用C实现的,能更有助于原理的理解或者也可以用numpy等高级框架实现 总
nn.BatchNorm中affine参数的作用
在PyTorch的nn.BatchNorm2d中,affine参数决定是否在批归一化(Batch Normalization)过程中引入可学习的缩放和平移参数。 BN层的公式如下, affine参数决定是否在批归一化之后应用一个可学习的线性变换,即缩放和平移。具体来说,如果 affine=True,批归一化层会有两个额外的可学习参数:缩放参数γ(初始值为1)和平移参数β(初始值为0),归一

自然语言处理: 第二十四章 为什么在NLP领域中普遍用LayerNorm 而不是BatchNorm?
前言 前面讲了Transformer 架构, 其中有一个层归一化layerNorm结构,最近在看不同的大模型结构中也发现会对其优化。但是似乎在CV领域貌似批次归一化BN层用的也很多,那么这两个归一化层到底有什么区别呢?为何在NLP领域几乎都是LN层,而不用BN层呢? 一、What is Normalization? Normalization:规范化或标准化,就是把输入数据X,在
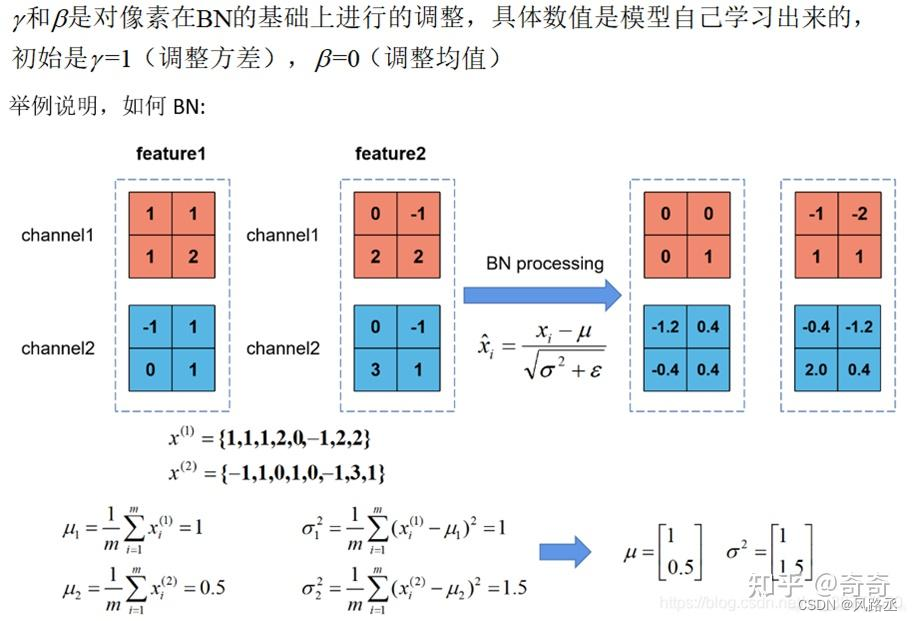
layerNorm和batchNorm
layerNorm和batchNorm 1、异同点2、图解(1)1d Norm图(2)2d Norm图 1、异同点 BatchNorm与LayerNorm的异同、 batchnorm 和layernorm的区别 相同点:都是让该层参数稳定下来,避免梯度消失或者梯度爆炸,方便后续的学习。 不同点: BN 对不同样本的同一特征做标准化(标准正态分布),抹杀了不同特征之间的大小

【深度学习】四种归一化方式对比:| LayerNorm,BatchNorm,InstanceNorm,GroupNorm
文章目录 1 四种归一化方式对比2 代码实践2.1 BatchNorm(批归一化)2.2 LayerNorm(层归一化)2.3 InstanceNorm(实例归一化)2.4 GroupNorm(组归一化) 归一化技术可以很好地,缓解梯度消失/爆炸问题,并有助于更快地收敛,也是一种正则化技术防止过拟合 实际中会看到好多归一化 比如BatchNorm,LayerNorm,Gro

神经网络:卷积神经网络中的BatchNorm
一、BN介绍 1.原理 在机器学习中让输入的数据之间相关性越少越好,最好输入的每个样本都是均值为0方差为1。在输入神经网络之前可以对数据进行处理让数据消除共线性,但是这样的话输入层的激活层看到的是一个分布良好的数据,但是较深的激活层看到的的分布就没那么完美了,分布将变化的很严重。这样会使得训练神经网络变得更加困难。所以添加BatchNorm层,在训练的时候BN层使用batch来估计数据的均
BatchNorm介绍:卷积神经网络中的BN
一、BN介绍 1.原理 在机器学习中让输入的数据之间相关性越少越好,最好输入的每个样本都是均值为0方差为1。在输入神经网络之前可以对数据进行处理让数据消除共线性,但是这样的话输入层的激活层看到的是一个分布良好的数据,但是较深的激活层看到的的分布就没那么完美了,分布将变化的很严重。这样会使得训练神经网络变得更加困难。所以添加BatchNorm层,在训练的时候BN层使用batch来估计数据的均值和
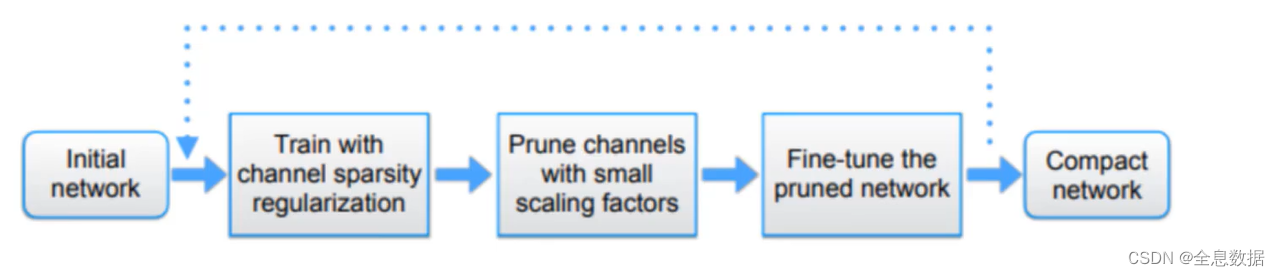
基于BatchNorm的模型剪枝【详解+代码】
文章目录 1、BatchNorm(BN)2、L1与L2正则化2.1 L1与L2的导数及其应用2.2 论文核心点 3、模型剪枝的流程 ICCV经典论文,通俗易懂!论文题目:Learning Efficient Convolutional Networks through Network Slimming卷积后能得到多个特征图,这些图一定都重要吗?训练模型的时候能否加入一些策略,让

CS231n作业笔记2.4:Batchnorm的实现与使用
CS231n简介 详见 CS231n课程笔记1:Introduction。 本文都是作者自己的思考,正确性未经过验证,欢迎指教。 作业笔记 Batchnorm的思想简单易懂,实现起来也很轻松,但是却具有很多优良的性质,具体请参考课程笔记。下图简要介绍了一下Batchnorm需要完成的工作以及优点(详情请见CS231n课程笔记5.3:Batch Normalization): 需要注意

pytorch中的归一化:BatchNorm、LayerNorm 和 GroupNorm
1 归一化概述 训练深度神经网络是一项具有挑战性的任务。 多年来,研究人员提出了不同的方法来加速和稳定学习过程。 归一化是一种被证明在这方面非常有效的技术。 1.1 为什么要归一化 数据的归一化操作是数据处理的一项基础性工作,在一些实际问题中,我们得到的样本数据都是多个维度的,即一个样本是用多个特征来表示的,数据样本的不同特征可能会有不同的尺度,这样的情况会影响到数据分析的结果。为了解决

深度学习论文: Rethinking “Batch” in BatchNorm及其PyTorch实现
深度学习论文: Rethinking “Batch” in BatchNorm及其PyTorch实现 Rethinking “Batch” in BatchNorm PDF: https://arxiv.org/pdf/2105.07576.pdf PyTorch代码: https://github.com/shanglianlm0525/CvPytorch PyTorch代码: https://
批量归一化 - BatchNorm
批量归一化(Batch Normalization),由Google于2015年提出,是近年来深度学习(DL)领域最重要的进步之一。该方法依靠两次连续的线性变换,希望转化后的数值满足一定的特性(分布),不仅可以加快了模型的收敛速度,也一定程度缓解了特征分布较散的问题,使深度神经网络(DNN)训练更快、更稳定。 损失出现在最后,后面的层训练较快数据在最底部 底部的层训练较慢底部层一变化,所有都得跟
NLP任务中-layer-norm比BatchNorm好在哪里
NLP任务中,layer-norm比BatchNorm好在哪里 本文主要是讲一下,为什么NLP任务中,比如Transformer,使用LayerNorm而不是使用BatchNorm 这个问题其实很有意思,理解的最核心的点在于:为什么LayerNorm单独对一个样本的所有单词做缩放可以起到效果。 大家往下慢慢看,我说一下我自己的理解,欢迎大佬拍砖,如果觉得我说的还行,点个在看鼓励一下。 为啥

英伟达APEX,多GPU分布式训练,同步Batchnorm,自动混合精度训练法宝指南
上一篇博客我讲解了APEX如何配置,以及简单的使用。这一篇主要讲一下注意细节。 英伟达(NVIDIA)训练深度学习模型神器APEX使用指南 多GPU,同步BN,自动混合精度 结合当前时代背景,这三个可以说是能训练好网络的基本条件。多GPU重要性不多说,既然都使用了多GPU,同步BN自然缺不得,还不知道同步BN(Sync BN)的同学,赶紧去查查吧。自动混合精度(amp)是干啥的,点击上面的链接
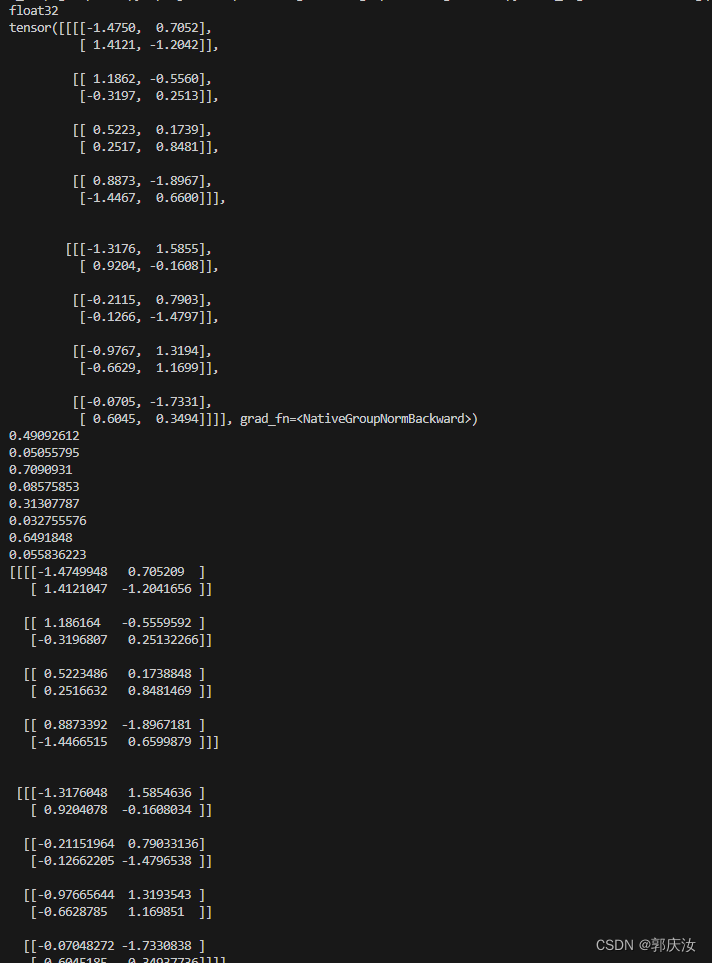
深度学习基础知识 BatchNorm、LayerNorm、GroupNorm的用法解析
深度学习基础知识 BatchNorm、LayerNorm、GroupNorm的用法解析 1、BatchNorm2、LayerNorm3、GroupNorm用法: BatchNorm、LayerNorm 和 GroupNorm 都是深度学习中常用的归一化方式。 它们通过将输入归一化到均值为 0 和方差为 1 的分布中,来防止梯度消失和爆炸,并提高模型的泛化能力 1、Batc
深度学习基础知识 BatchNorm、LayerNorm、GroupNorm的用法解析
深度学习基础知识 BatchNorm、LayerNorm、GroupNorm的用法解析 1、BatchNorm2、LayerNorm3、GroupNorm用法: BatchNorm、LayerNorm 和 GroupNorm 都是深度学习中常用的归一化方式。 它们通过将输入归一化到均值为 0 和方差为 1 的分布中,来防止梯度消失和爆炸,并提高模型的泛化能力 1、Batc