本文主要是介绍layerNorm和batchNorm,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
layerNorm和batchNorm
- 1、异同点
- 2、图解
- (1)1d Norm图
- (2)2d Norm图
1、异同点
BatchNorm与LayerNorm的异同、
batchnorm 和layernorm的区别
相同点:都是让该层参数稳定下来,避免梯度消失或者梯度爆炸,方便后续的学习。
不同点:
BN
- 对不同样本的同一特征做标准化(标准正态分布),抹杀了不同特征之间的大小关系,但是保留了不同样本间的大小关系;
- BN 需要在训练过程中,滑动平均累积每个神经元的均值和方差,并保存在模型文件中用于推理过程,而 LN 不需要。
- 更适用于
CV领域。(比如3维特征的图像在做BN时,相当于对不同样本的同一通道内的特征做标准化。)
LN:
- 对同一样本的不同特征做标准化(标准正态分布),抹杀了不同样本间的大小关系,但是保留了一个样本内不同特征之间的大小关系。
- 更适用于
NLP领域。因为NLP或者序列任务来说,一条样本的不同特征,其实就是时序上字符取值的变化,样本内的特征关系是非常紧密的。
2、图解
(1)1d Norm图
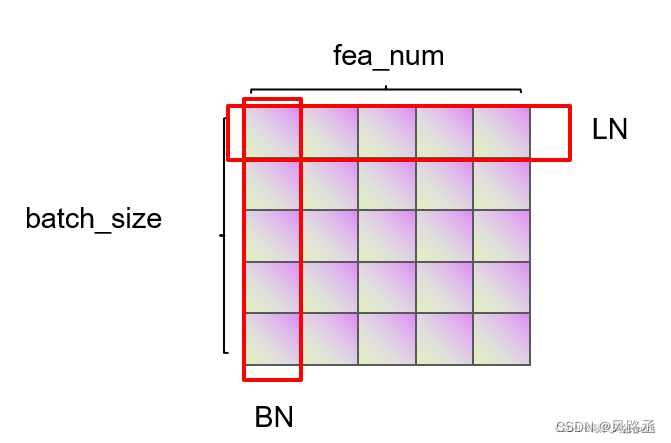
(2)2d Norm图
BatchNorm2d 讲解 及 illustration
3维特征的图像在做BN时,相当于对不同样本的同一通道内的特征做标准化。如下的粉色切片:
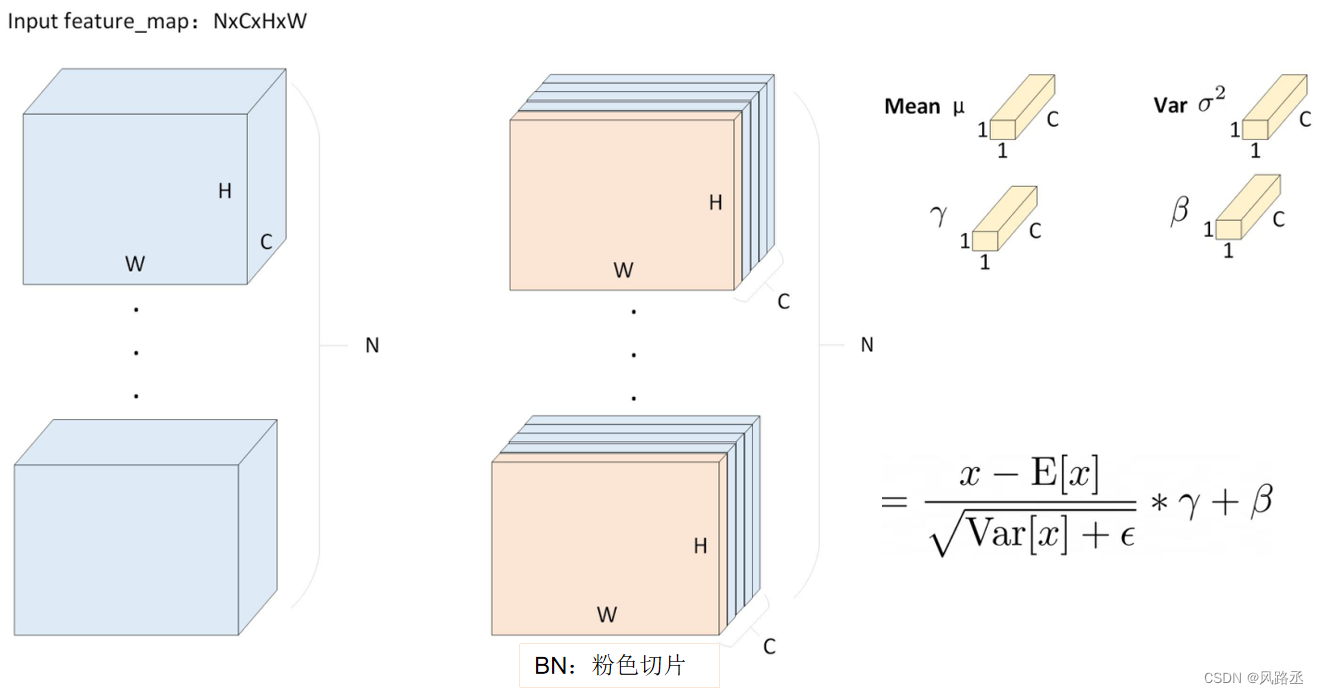
BatchNorm2d 实现案例:
具体举例说明,如下所示,输入feature_map维度为 2 x 2 x 2 x 2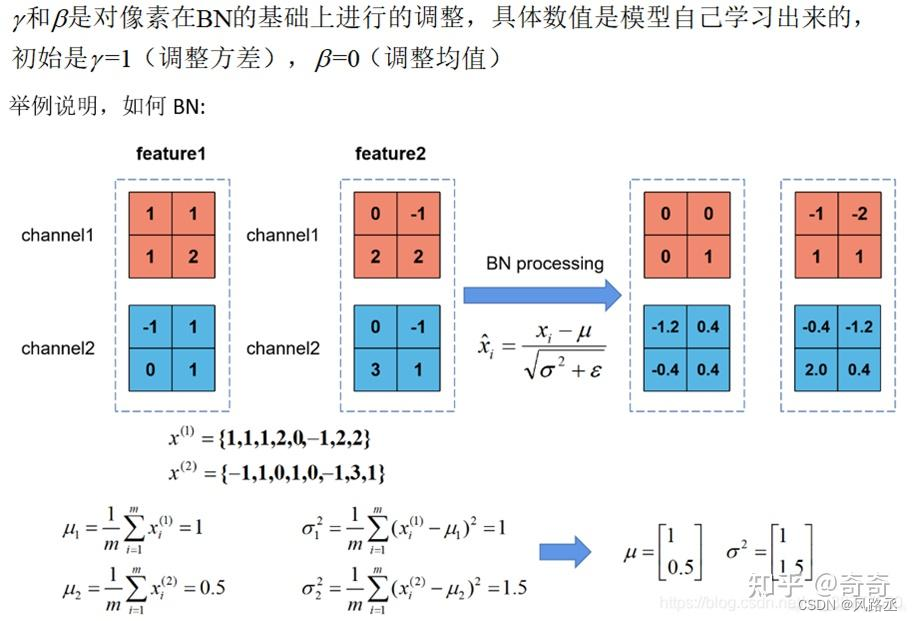
这篇关于layerNorm和batchNorm的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





