本文主要是介绍AquaCrop模型运行及结果分析、代码解析;气象、土壤、作物和管理措施等数据的准备和输入;农业水资源管理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
专题一 模型原理与数据要求
专题二 模型数据准备
专题三 模型运行及结果分析
专题四 参数分析
专题五 源代码分析
更多应用
AquaCrop是由世界粮食及农业组织(FAO)开发的一个先进模型,旨在研究和优化农作物的水分生产效率。这个模型在全球范围内被广泛应用于农业水管理,特别是在制定农作物灌溉计划和应对水资源限制方面显示出其强大的实用性。AquaCrop 不仅包含一个全面的数据库,还提供了用户友好的接口,使得它在实际应用中极为便捷。
AquaCrop模型的核心优势在于其独特的水分管理能力,能够精确模拟作物生长过程中水分的需求与消耗,帮助农业工作者制定更为科学和高效的灌溉策略。通过对作物的水分需求和供应的精确计算,AquaCrop 能够帮助提高水资源的使用效率,优化作物产量和质量。
为了让更多的科研人员和农业工作者能够深入理解AquaCrop模型的原理,有效地运用这一工具,将详细讲解AquaCrop模型的各个组成部分,包括气象、土壤、作物和管理措施等数据的准备和输入。通过模型的实践操作和结果分析,让参与者能够不仅理解模型背后的科学原理,同时掌握如何在实际工作中应用模型来解决问题。此外,还将深入探讨如何通过修改模型代码来定制和优化模型,以适应特定的研究需求或解决特定的农业问题。
专题一 模型原理与数据要求
1.AquaCrop模型的应用范围
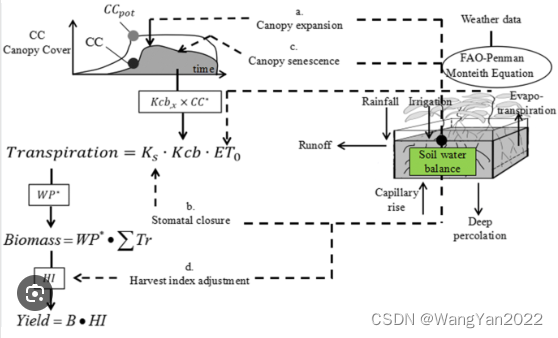
2.模型基本原理与计算框架
3.模型输入数据要求
4.模型应用实例简介
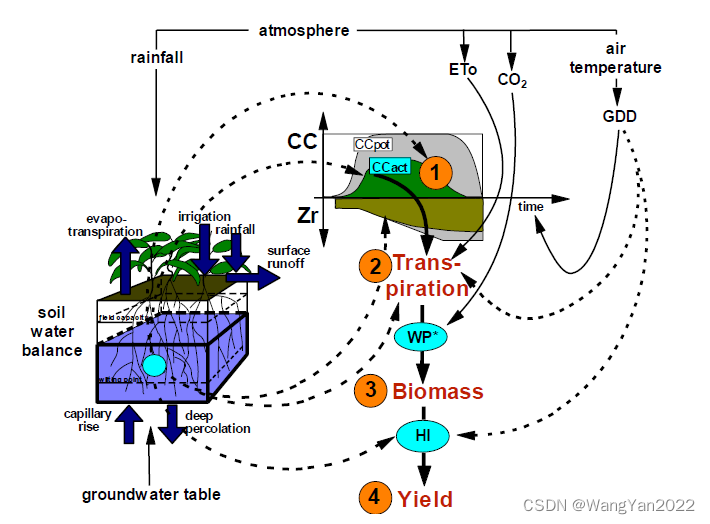
专题二 模型数据准备
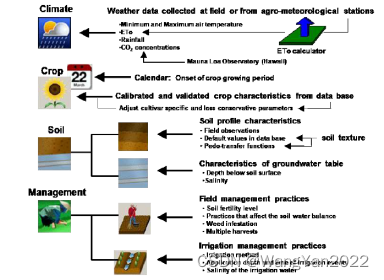
1.气象数据准备:包括温度、降水量、蒸发量等。
2.土壤数据制备:土壤类型、含水量、水分保持能力
3.农作物数据制备:作物类型、生长周期、水分需求
4.管理措施的输入:灌溉方式、施肥计划、病虫害管理
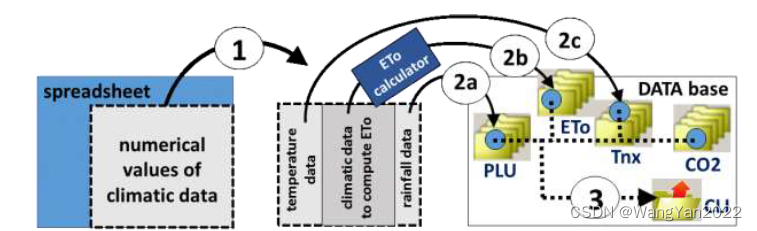
专题三 模型运行及结果分析
1.模型运行步骤
2.模型输出
3.模型结果分析(在线版)
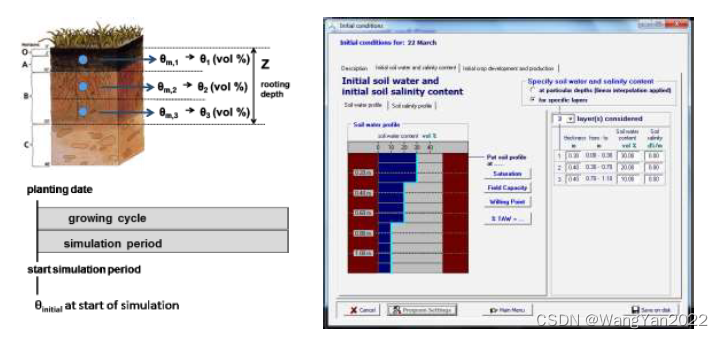
专题四 参数分析
1.敏感性分析方法
2.模型敏感参数
3.参数的不确定性分析方法
4.参数的不确定性分析
5.参数调优建议
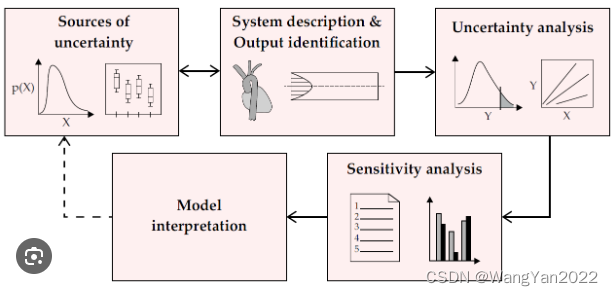
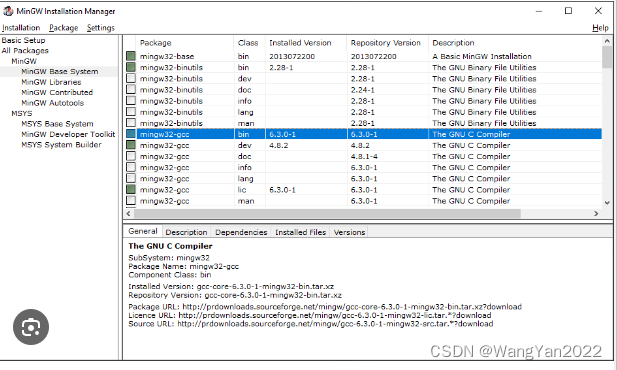
专题五 源代码分析
1.现代Fortran基础
2.模型Fortran代码编译
3.模型代码结构
4.模型入口分析
5.模型主要计算功能分析
注:请提前自备电脑及安装所需软件
更多应用
①R语言与作物模型(以DSSAT模型为例)融合
②最新DSSAT作物模型建模方法及实践技术应用
③基于Python语言快速批量运行DSSAT模型及交叉融合、扩展应用
④遥感数据与作物生长模型同化及在作物长势监测与估产中的应用
⑤WOFOST模型与PCSE模型实践技术应用
⑥基于R语言APSIM模型进阶应用与参数优化、批量模拟
智慧农业新篇章:DSSAT模型、APSIM模型、WOFOST与PCSE模型综合应用,引领作物生长模拟与产量预测新潮流_wofost(world food studies)作物生长模型-CSDN博客文章浏览阅读1.2k次,点赞18次,收藏20次。作物模型技术得到了不断的发展,多种模型如DSSAT、APSIM、WOFOST与PCSE等被广泛应用于农业生产实践和科学研究中。这些模型的综合应用,可以更加全面和深入地了解作物生长发育的规律和机制,为农业生产提供更加科学、精准的指导。_wofost(world food studies)作物生长模型https://blog.csdn.net/WangYan2022/article/details/136669738?spm=1001.2014.3001.5502★关 注【科研充电吧】公 众 号,获取海量教程和资源
这篇关于AquaCrop模型运行及结果分析、代码解析;气象、土壤、作物和管理措施等数据的准备和输入;农业水资源管理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








