本文主要是介绍高质量新闻数据集OpenNewsArchive:880万篇主流新闻报道,国产大模型开源数据又添猛料,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在构建国产大语言模型的道路上,高质量新闻是不可或缺的重要语料之一。这类语料集准确性、逻辑性、时效性于一体,同时包含丰富的事实知识,可以大幅提升模型的文本生成质量、词汇表达能力、事件理解分析能力以及时序内容的适应性和预测能力,使其在现实世界的应用中更加准确和可靠。
近日 ,为了更好地满足大模型研发的数据需求,大模型语料数据联盟开源了大规模、高质量新闻数据集——开放新闻库数据集(OpenNewsArchive),提供了多个主流媒体来源、多种主题类型、共计880万篇新闻文章信息,为研究人员和数据科学家提供了丰富的文本数据资源。一起来看看。
一、开放新闻库介绍(OpenNewsArchive)

开放新闻库(OpenNewsArchive)数据集是由OpenDataLab联合蜜度、商汤等多家联盟机构进行开源开发,其中包含了880万篇新闻文章的信息,涵盖了各种不同主题和来源的新闻内容。每篇新闻文章包括字段如标题、内容、发布日期、语言等,且数据集的内容经过数据清洗去重等处理,为研究人员和数据科学家提供了丰富的文本数据资源。
下载链接:https://opendatalab.com/OpenDataLab/OpenNewsArchive
数据集具有三大亮点:
● 内容全面覆盖多个板块:包含财经、健康、军事、体育、房产、社会、学术等多个板块分类的新闻内容,涵盖广泛。
● 无毒性内容和价值偏见:新闻内容不含有害信息或偏见观点,确保信息公正客观。
● 保持新闻内容更新:数据集中包含的新闻发布日期主要集中在2023年,相较于其他已知的开放新闻数据集,具有较高的时效性,有利于提高模型预测的准确性与应对能力。
二、数据处理方法
1. 处理HTML标签:针对文本中含有HTML标签的部分进行清洗,去除标签并保留文本内容的可读性。
2. 清洗无效文本:删除全文无标点的文本和文本长度过短的部分,确保数据集中的文本质量。
3. 清除特殊字符:删除文本中的特殊字符,包括emoj表情、特殊符号等,保持文本干净规范。
4. 处理重复内容:去除重复的段落,确保每个新闻内容唯一。
5. 清洗混入的不明文本:逐行检查处理文本中包含关键词的句子或内容,确保数据集的纯净性。
6. 删除非法语言部分:排除非汉语和英语以外的语言内容,确保数据集的语言合法性。
三、数据信息
1. 基本信息
● 数据模态:纯文本数据
● 主要语言:中文、英文;(中文占比超过99.9%)
● 数据量:27GB;880万篇文章
● 数据格式:以Jsonlines形式存储的语料文本与附加信息
2. 统计信息
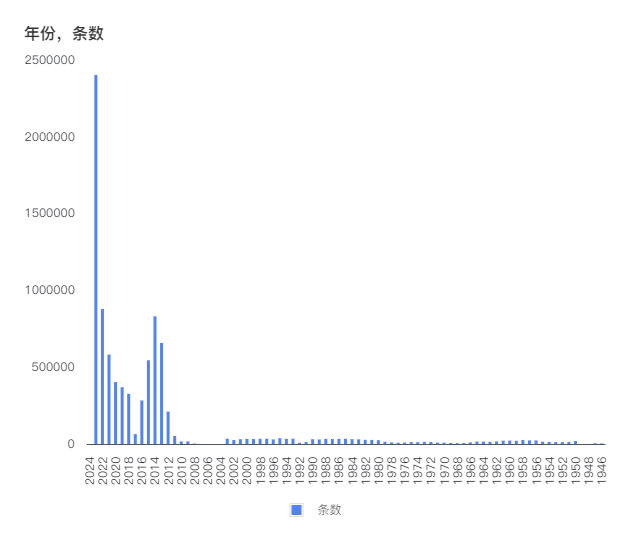
(开放新闻库数据集中2023年发布的新闻最多)
3. 数据样例
{"id": "Bl4ERwIANjygAeAMbr6A","content": "如今的NBA,来到一个群雄争霸的时代,因为老一辈超级球星还没完全跌落神坛,像詹姆斯、杜兰特、库里、哈登、欧文等球员,仍能带领球队保持一定的竞争力,与此同时,各新生代年轻球星也冉冉升起,要逐渐成为联盟未来的门面了,最有潜力的当属锡安、亚历山大、福克斯、文班亚马这些球员。此外,联盟还不缺乏那种大器晚成的球星,像现役三大统治级别球员,约基奇、字母哥和恩比德,他们在职业生涯早期并没有大放异彩,如今都已成为联盟TOP5级别的超级球星。在这样的环境之下,新赛季豪门球队众多,竞争相当激烈,大多数球队都拥有两个或以上的明星级别球员。\n不过说实话,有些球队虽然阵容豪华,但球星之间适配性不够强,产生不了良好的化学反应,一个典型的例子就是独行侠。独行侠拥有东契奇和欧文两大球星,他们还是上赛季联盟唯一一支,拥有两个全明星首发球员的队伍。即便如此,独行侠最终位仅列西部第11,季后赛的门票都没拿到。东契奇和欧文个人属性太重叠,都需要持球发动进攻,且两人防守端偏弱,同时在场时外线必然要出现防守漏洞。此外,快船这样的球队也有些华而不实,主要原因在于“卡椒”组合,伤病隐患太大,一到季后赛就出岔子,威少爷也不在巅峰期了。\n还有一些球队,他们阵容好看,硬实力也强,比如说西部这边的太阳,东部这边的凯尔特人,雄鹿。太阳现在是杜兰特+比尔+布克的三巨头坐镇,而凯尔特人经过休赛期的阵容变动之后,目前拥有4名全明星球员,那就是塔图姆、布朗、波尔津吉斯和霍勒迪。然而实际上,绿军主要还是围绕着双探花,塔图姆和布朗两个球员打,他们也是这支球队的绝对核心。塔图姆和布朗这对双人组合,下限真的超级高,自他俩进入NBA加盟凯尔特人以来,还从来都没有缺席过季后赛,过去6个赛季甚至带领球队4次闯进东决,一次闯进总决赛。\n上赛季,塔图姆场均可以砍下30.1分8.8篮板4.6助攻,而布朗场均可以得到26.6分6.9篮板3.5助攻,双探花场均轰出57+15+8,力压湖人詹眉,76人登帝,快船卡椒,勇士库汤等组合,成为联盟场均得分最高的二人组。新赛季,两人也将继续向NBA最强二人组发起挑战,唯一能对他们造成威胁的,可能就是雄鹿的利拉德+字母哥“表字”组合了,不过从季前赛前几场比赛的表现来看,字母哥统治力还在,利拉德的状态却有些堪忧,连拉了两场,刚加盟雄鹿,他也需要一段时间和球队进行磨合,雄鹿能否取得更大突破,还要等常规赛来考证。\n狂轰57+15+8!你们才是NBA最强二人组!东部豪门崛起,新赛季冲冠。话题回到凯尔特人,双探花组合下限确实足够高,但他们还从未联手拿到过总冠军,最可惜的是21-22赛季,凯尔特人与金州勇士在总决赛舞台一决高下,当时那支勇士队,被认为是巅峰已落幕,所有人都在看好绿军夺冠,最终他们却没能达到这一目标。其实这几年,凯尔特人屡次止步于季后赛后几轮,双探花的一些短板也显露了出来。塔图姆的缺点就在于自己不太稳定,关键球总是处理不好,容易上头。而布朗控运球能力太差,毫无组织能力,球商也不高,只有做二当家的命了。\n尽管如此,双探花现在也算年轻,还有上升空间,而凯尔特人依然属于联盟第一梯队的球队,媒体《体育画报》邀请部分球探及专家,对各个赛区的球队新赛季排名进行了预测,凯尔特人就稳居东部第一,在GM调查中,绿军新赛季的夺冠支持率与丹佛掘金并列第一,为33%,他们仍是冲冠机会最大的球队之一。根据球队队记说法,首发五虎+普理查德+霍福德+豪瑟+科内特大概率作为新季绿军9人轮换,值得一提的是,普理查德这名平民球员也值得关注,季前赛他的表现非常出色,场均能得到接近20分。你们来预测一下,绿军新赛季可以走多远呢?","title": "轰57+15+8!你们才是NBA最强二人组!东部豪门崛起","language": "zh","date": "2023-10-19","num_words": 870,"max_word_length": 6,"frac_chars_non_alphanumeric": 0.10888443553774214,"frac_chars_dupe_5grams": 0,"frac_chars_dupe_9grams": 0}
(左右滑动查看全部)
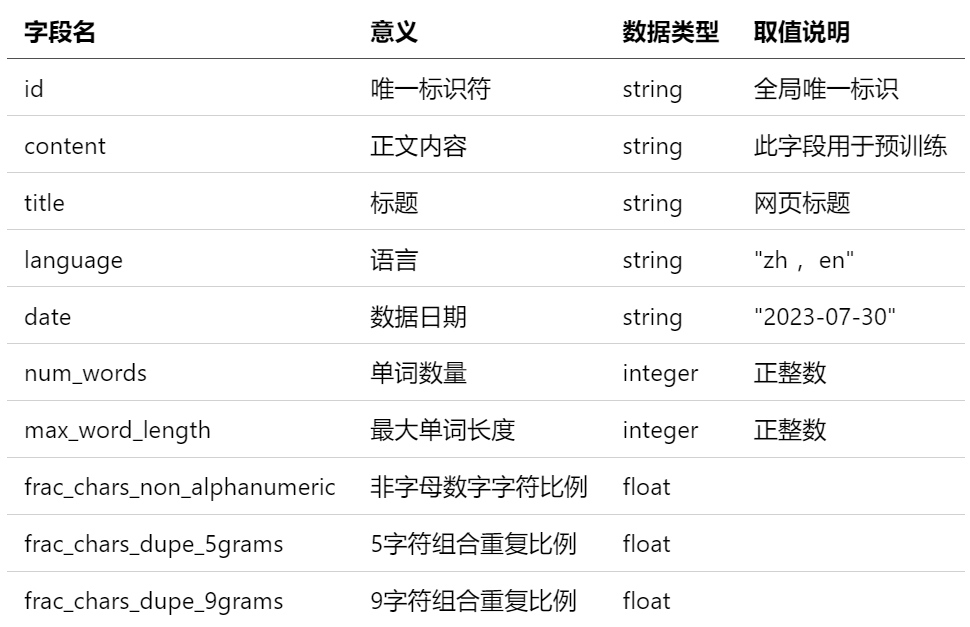
4. 数据字段格式
以下表格记录了数据各字段的字段名,意义,数据类型和取值说明:
四、许可
开放新闻库数据集整体采用CC BY 4.0许可协议。您可以自由共享、改编该数据集,唯需遵循以下条件:
● 署名:您必须适当地标明作者、提供指向本协议的链接,以及指明是否(对原始数据集)做了修改。您可以以任何合理的方式这样做,但不能以任何方式暗示许可人同意您或您的使用。
● 没有附加限制:您不得使用法律条款或技术措施来限制他人执行许可证允许的任何操作。完整协议内容,请访问CC BY 4.0协议全文。
特别注意事项
请注意,本数据集的某些子集可能受制于其他协议规定。在使用特定子集之前,请务必仔细阅读相关协议,确保合规使用。更为详细的协议信息,请在特定子集的相关文档或元数据中查看。
OpenDataLab作为非盈利机构,倡导和谐友好的开源交流环境,若在开源数据集内发现有侵犯您合法权益的内容,可发送邮件至(OpenDataLab@pjlab.org.cn),邮件中请写明侵权相关事实的详细描述并向我们提供相关的权属证明资料。我们将于3个工作日内启动调查处理机制,并采取必要的措施进行处置(如下架相关数据)。但您应确保您投诉的真实性,否则采取措施后所产生的不利后果应由您独立承担。
开放新闻库数据集已上架OpenDataLab官网,浏览器访问:https://opendatalab.com/OpenDataLab/OpenNewsArchive
这篇关于高质量新闻数据集OpenNewsArchive:880万篇主流新闻报道,国产大模型开源数据又添猛料的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






