本文主要是介绍20 项任务全面碾压 BERT,CMU 全新 XLNet 模型屠榜,代码已开源!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
BERT 带来的影响还未平复,CMU 与谷歌大脑提出的 XLNet 在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果。令人激动的是,目前 XLNet 已经开放了训练代码和大型预训练模型,这又可以玩一阵了~
转载来源
公众号:机器之心
“阅读本文大概需要 5 分钟。
2018 年,谷歌发布了基于双向 Transformer 的大规模预训练语言模型 BERT,刷新了 11 项 NLP 任务的最优性能记录,为 NLP 领域带来了极大的惊喜。很快,BERT 就在圈内普及开来,也陆续出现了很多与它相关的新工作。
BERT 带来的震撼还未平息,今日又一全新模型出现。

来自卡耐基梅隆大学与谷歌大脑的研究者提出新型预训练语言模型 XLNet,在 SQuAD、GLUE、RACE 等 20 个任务上全面超越 BERT。
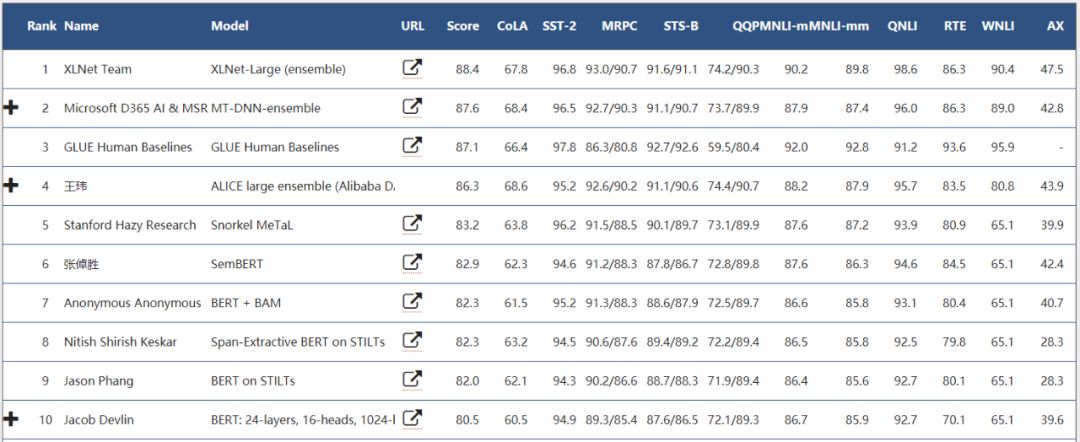
Glue 任务排行榜
而此论文的作者也都是我们熟知的研究者:共同一作为杨植麟(曾经的清华学霸,现在 CMU 读博)与 Zihang Dai(CMU 博士),此外还包括 CMU 教授 Yiming Yang,CMU 语言技术中心的总负责人 Jaime Carbonell,CMU 教授、苹果 AI 负责人 Russ Salakhutdinov,谷歌大脑的创始成员、AutoML 的缔造者之一 Quoc Le。
论文地址:https://arxiv.org/pdf/1906.08237.pdf
预训练模型及代码地址:https://github.com/zihangdai/xlnet
那么,相比于 BERT,XLNet 有哪些提升呢?
作者表示,BERT 这样基于去噪自编码器的预训练模型可以很好地建模双向语境信息,性能优于基于自回归语言模型的预训练方法。然而,由于需要 mask 一部分输入,BERT 忽略了被 mask 位置之间的依赖关系,因此出现预训练和微调效果的差异(pretrain-finetune discrepancy)。
基于这些优缺点,该研究提出了一种泛化的自回归预训练模型 XLNet。XLNet 可以:1)通过最大化所有可能的因式分解顺序的对数似然,学习双向语境信息;2)用自回归本身的特点克服 BERT 的缺点。此外,XLNet 还融合了当前最优自回归模型 Transformer-XL 的思路。
最终,XLNet 在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果(state-of-the-art),包括机器问答、自然语言推断、情感分析和文档排序。
以前超越 BERT 的模型很多都在它的基础上做一些修改,本质上模型架构和任务都没有太大变化。但是在这篇新论文中,作者从自回归(autoregressive)和自编码(autoencoding)两大范式分析了当前的预训练语言模型,并发现它们虽然各自都有优势,但也都有难以解决的困难。为此,研究者提出 XLNet,并希望结合大阵营的优秀属性。
AR 与 AE 两大阵营
无监督表征学习已经在自然语言处理领域取得了巨大的成功。在这种理念下,很多研究探索了不同的无监督预训练目标,其中,自回归(AR)语言建模和自编码(AE)成为两个最成功的预训练目标。
AR 语言建模旨在利用自回归模型估计文本语料库的概率分布。由于 AR 语言模型仅被训练用于编码单向语境(前向或后向),因而在深度双向语境建模中效果不佳。而下游语言理解任务通常需要双向语境信息。这导致 AR 语言建模无法实现有效预训练。
相反,基于 AE 的预训练模型不会进行明确的密度估计,而是从残缺的输入中重建原始数据。一个著名的例子就是 BERT。给出输入 token 序列,BERT 将一部分 token 替换为特殊符号 [MASK],随后训练模型从残缺版本恢复原始的 token。由于密度估计不是目标的一部分,BERT 允许使用双向语境进行重建。
但是,模型微调时的真实数据缺少 BERT 在预训练期间使用的 [MASK] 等人工符号,这导致预训练和微调之间存在差异。此外,由于输入中预测的 token 是被 mask 的,因此 BERT 无法像自回归语言建模那样使用乘积法则(product rule)对联合概率进行建模。
换言之,给定未 mask 的 token,BERT 假设预测的 token 之间彼此独立,这被过度简化为自然语言中普遍存在的高阶、长期依赖关系。
两大阵营间需要新的 XLNet
现有的语言预训练目标各有优劣,这篇新研究提出了一种泛化自回归方法 XLNet,既集合了 AR 和 AE 方法的优势,又避免了二者的缺陷。
首先,XLNet 不使用传统 AR 模型中固定的前向或后向因式分解顺序,而是最大化所有可能因式分解顺序的期望对数似然。由于对因式分解顺序的排列操作,每个位置的语境都包含来自左侧和右侧的 token。因此,每个位置都能学习来自所有位置的语境信息,即捕捉双向语境。
其次,作为一个泛化 AR 语言模型,XLNet 不依赖残缺数据。因此,XLNet 不会有 BERT 的预训练-微调差异。同时,自回归目标提供一种自然的方式,来利用乘法法则对预测 token 的联合概率执行因式分解(factorize),这消除了 BERT 中的独立性假设。
除了提出一个新的预训练目标,XLNet 还改进了预训练的架构设计。
受到 AR 语言建模领域最新进展的启发,XLNet 将 Transformer-XL 的分割循环机制(segment recurrence mechanism)和相对编码范式(relative encoding)整合到预训练中,实验表明,这种做法提高了性能,尤其是在那些包含较长文本序列的任务中。
简单地使用 Transformer(-XL) 架构进行基于排列的(permutation-based)语言建模是不成功的,因为因式分解顺序是任意的、训练目标是模糊的。因此,研究人员提出,对 Transformer(-XL) 网络的参数化方式进行修改,移除模糊性。
目标:排列语言建模(Permutation Language Modeling)
从上面的比较可以得出,AR 语言建模和 BERT 拥有其自身独特的优势。我们自然要问,是否存在一种预训练目标函数可以取二者之长,同时又克服二者的缺点呢?
研究者借鉴了无序 NADE 中的想法,提出了一种序列语言建模目标,它不仅可以保留 AR 模型的优点,同时也允许模型捕获双向语境。具体来说,一个长度为 T 的序列 x 拥有 T! 种不同的排序方式,可以执行有效的自回归因式分解。从直觉上来看,如果模型参数在所有因式分解顺序中共享,那么预计模型将学习从两边的所有位置上收集信息。
为了提供一个完整的概览图,研究者展示了一个在给定相同输入序列 x(但因式分解顺序不同)时预测 token x_3 的示例,如下图所示:

图 1:排列语言建模目标示例:给定相同的输入序列 x,但因式分解顺序不同,此时预测 x_3。
模型架构:对目标感知表征的双流自注意力
对于参数化,标准 Transformer 架构存在两个互相矛盾的要求:1)预测 token 应该仅使用位置 z_t 而不是内容 x_z<t,不然该目标函数就变得不重要了;2)为了预测另一个 token x_zj,其中 j>t,
应该仅使用位置 z_t 而不是内容 x_z<t,不然该目标函数就变得不重要了;2)为了预测另一个 token x_zj,其中 j>t,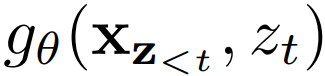 应该编码内容 x_z<t,以提供完整的上下文信息。为了解决这一矛盾,该研究提出使用两个隐藏表征的集合,而不是只用其中一个。
应该编码内容 x_z<t,以提供完整的上下文信息。为了解决这一矛盾,该研究提出使用两个隐藏表征的集合,而不是只用其中一个。
这两个隐藏表征即内容表征 h_zt 和 Query 表征 g_zt,下图 2 的 a、b 分别展示了这两种表征的学习。其中内容表征与 Transforme 的隐藏状态类似,它将同时编码输入本身的内容及上下文信息。Query 表征仅能获取上下文信息及当前的位置,它并不能获取当前位置的内容。
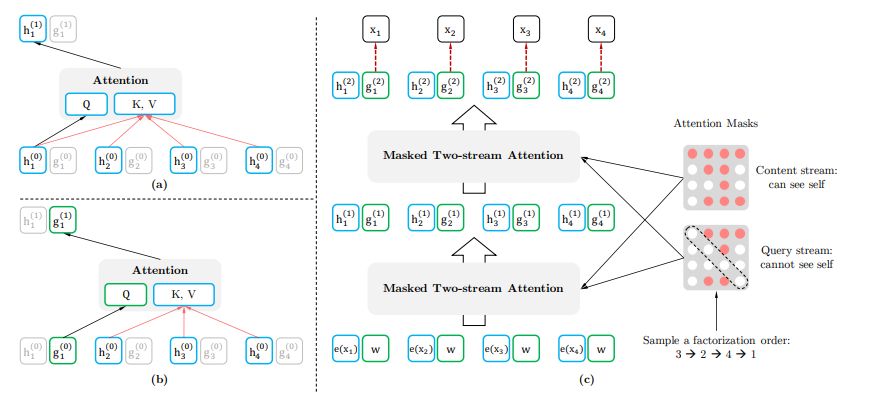
图 2:(a)内容流注意力,与标准自注意力相同;(b)Query 流注意力,没有获取内容 x_z_t 的信息;(c)利用双流注意力的排列语言建模概览图。
由于目标函数适用于 AR 框架,研究者整合了当前最佳的 AR 语言模型——Transformer-XL 到预训练框架中,并将其体现在方法名字中。具体来说,他们借鉴了 Transformer-XL 中的两项重要技术——相对位置编码范式和分割循环机制。现在,结合双流注意力和 Transformer-XL 的改进,上面图 2(c) 展示了最终的排列语言建模架构。
实验结果
和 BERT 相同,研究者使用了 BooksCorpus 和英文维基百科作为预训练数据,文本量达到 13GB。此外,论文还使用了 Giga 5(16GB 文本),ClueWeb 2012-B 和 Common Crawl 数据集进行预训练。他们在后两个数据集上使用了启发式搜索过滤掉较短或低质量的文本,最终分别剩余 19 GB 和 78 GB 文本。
这项工作中的最大模型 XLNet-Large 拥有与 BERT-Large 相同的架构超参数,因此模型大小也相似。研究者在 512 块 TPU v3 上借助 Adam 优化器对 XLNet-Large 训练 500K 步,学习率线性下降,batch 大小为 2048,训练时间为 2.5 天。
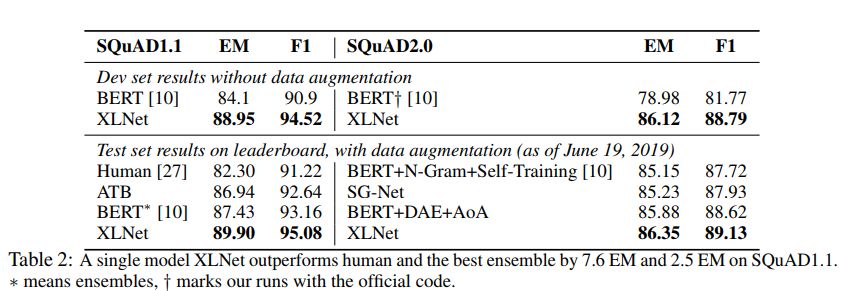
表 2:单模型的 XLNet 在 SQuAD1.1 数据集上的表现分别比人类和当前最好模型超过了 7.6EM 和 2.5EM。
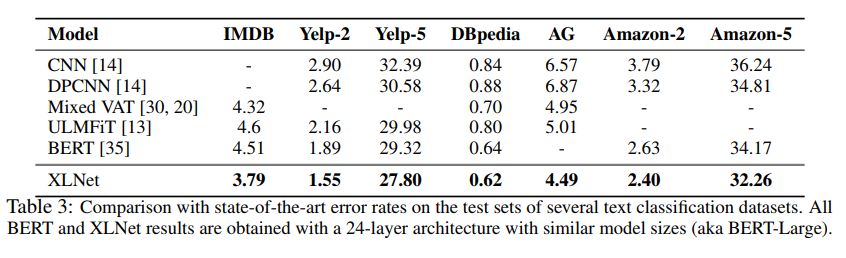
表 3:在一些文本分类数据集的测试集上与当前最优的误差率进行对比。所有的 BERT 和 XLNet 结果都通过同样模型大小的 24 层架构(相当于 BERT-Large)获得。

表 4:GLUE 的对比,∗表示使用集合,†表示多任务行的单任务结果。所有结果都基于同样模型大小的 24 层架构获得。表格最高一行是与 BERT 的直接对比,最低一行是和公开排行榜上最佳效果的对比。
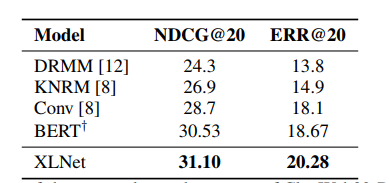
表 5:在 ClueWeb09-B 测试集(一项文档排名任务)上对比 XLNet 和当前最优方法的性能。† 表示该研究所做的实现。
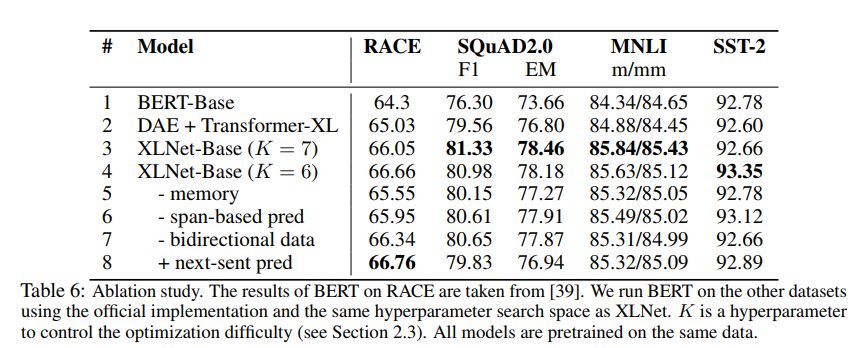
表 6:控制变量测试。其中 BERT 在 RACE 上的结果来自论文 [39]。研究者使用 BERT 的官方实现在其他数据集上运行,且它具备与 XLNet 相同的超参数搜索空间。K 是控制优化难度的超参数。所有模型都在相同数据上预训练而成。
推荐阅读
1
跟繁琐的命令行说拜拜!Gerapy分布式爬虫管理框架来袭!
2
跟繁琐的模型说拜拜!深度学习脚手架 ModelZoo 来袭!
3
只会用Selenium爬网页?Appium爬App了解一下
4
妈妈再也不用担心爬虫被封号了!手把手教你搭建Cookies池
崔庆才
静觅博客博主,《Python3网络爬虫开发实战》作者
隐形字
个人公众号:进击的Coder



长按识别二维码关注
这篇关于20 项任务全面碾压 BERT,CMU 全新 XLNet 模型屠榜,代码已开源!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





