本文主要是介绍一个超快的公共情报搜集爬虫 — Photon,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是「进击的Coder」的第 456 篇技术分享
作者:Ckend
来源:Python 实用宝典
“
阅读本文大概需要 3 分钟。
”Photon 是一个由 s0md3v 开源的情报搜集爬虫,其主要功能有:
1.爬取链接(内链、外链)。
2.爬取带参数的链接,如(pythondict.com/test?id=2)。
3.文件(pdf, png, xml)。
4.密钥(在前端代码中不小心被释放出来的)。
5.js 文件和 Endpoint(spring 中比较重要的监视器)
6.匹配自定义正则表达式的字符串。
7.子域名和 DNS 相关数据。
你可以用它来干很多事,比如爬图片、找漏洞、找子域名、爬数据等等。而且提取出来的数据格式非常整洁:
不仅如此,它甚至支持 json 格式 ,仅需要在输入命令的时候加上 json 参数:
python photon.py -u "http://example.com" --export=json
为什么能用来做情报搜集呢?耐心往后看哦。
1.下载安装
你可以上 photon 的 github 下载完整项目:https://github.com/s0md3v/Photon
下载后解压到你想要使用的地方。如果你还没有安装Python,建议阅读这篇文章:超详细Python安装指南,进行Python的安装。
安装完 Python 后,打开 CMD(windows)/Terminal(macOS),下面简称为终端,进入你刚解压的文件夹,然后输入以下命令安装 Photon 的依赖:
pip install -r requirements.txt
如图所示:

2.简单使用
注意,使用的时候要在 Photon 文件夹下。比如我们随便提取一个网站的 URL 试一下,在终端输入以下命令:
python photon.py -u https://bk.tencent.com/
结果如下:

它会在当前目录下产生一个你测试的域名的文件夹,比如在我这里是 bk.tencent.com:
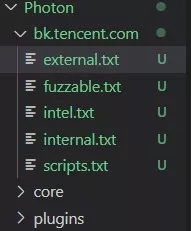
嘻嘻,让我们看看里面有什么东西,有没有程序员留下的小彩蛋,打开 external.txt,这是该网站的外链的存放位置。可以看到,这里不仅仅是只有网站页面,连 CDN 文件地址都会放在这里,所以 external 可能是个藏宝库哦。
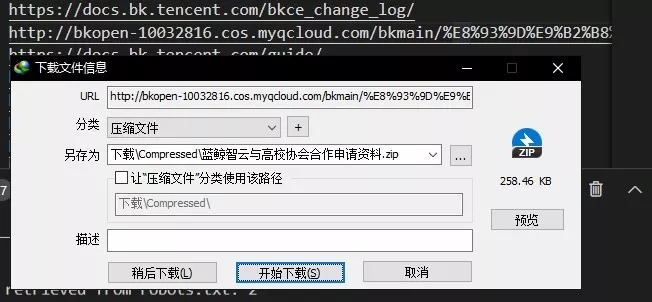
还能一下找出该网站上链接的全部开源项目:
3.扩展
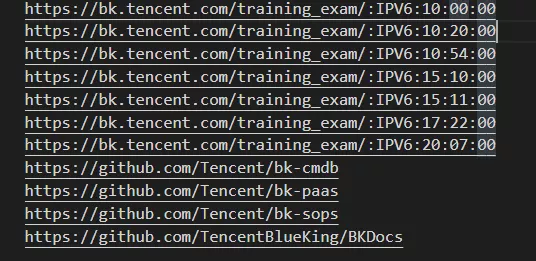
这个项目的价值,不仅在于能够快速拉取你想要得到的数据,还在于能够构建一个牛逼轰轰的情报系统(如果你技术够强的话)。因为它是能不断延伸下去的,比如从外链出发,你能找到很多和这个网站相关的讯息:

相比于搜索引擎搜索的结果,实际上这些信息更符合情报的要求。而且不是所有的信息都能在搜索引擎搜索得到,而通过这个 Photon,你可以顺藤摸瓜找到那些隐藏在互联网世界的它们。
试想一下,如果你搜集了很多这样的网站...然后用正则表达式搭建一个属于你自己的搜索引擎,这样的感觉是不是很棒?

End
「进击的Coder」专属学习群已正式成立,搜索「CQCcqc4」添加崔庆才的个人微信或者扫描下方二维码拉您入群交流学习。

看完记得关注@进击的Coder
及时收看更多好文
↓↓↓
崔庆才的「进击的Coder」知识星球已正式成立,感兴趣的可以查看《我创办了一个知识星球》了解更多内容,欢迎您的加入:

好文和朋友一起看~
这篇关于一个超快的公共情报搜集爬虫 — Photon的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







