本文主要是介绍meshlab: pymeshlab合并多个物体模型并保存(flatten visible layers),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、关于环境
请参考:pymeshlab遍历文件夹中模型、缩放并导出指定格式-CSDN博客
二、关于代码
本文所给出代码仅为参考,禁止转载和引用,仅供个人学习。 本文所给出的例子是https://download.csdn.net/download/weixin_42605076/89233917中的obj_000001.ply和obj_000009.ply。
合并多个物体模型并不是布尔运算,而是简单的叠加。
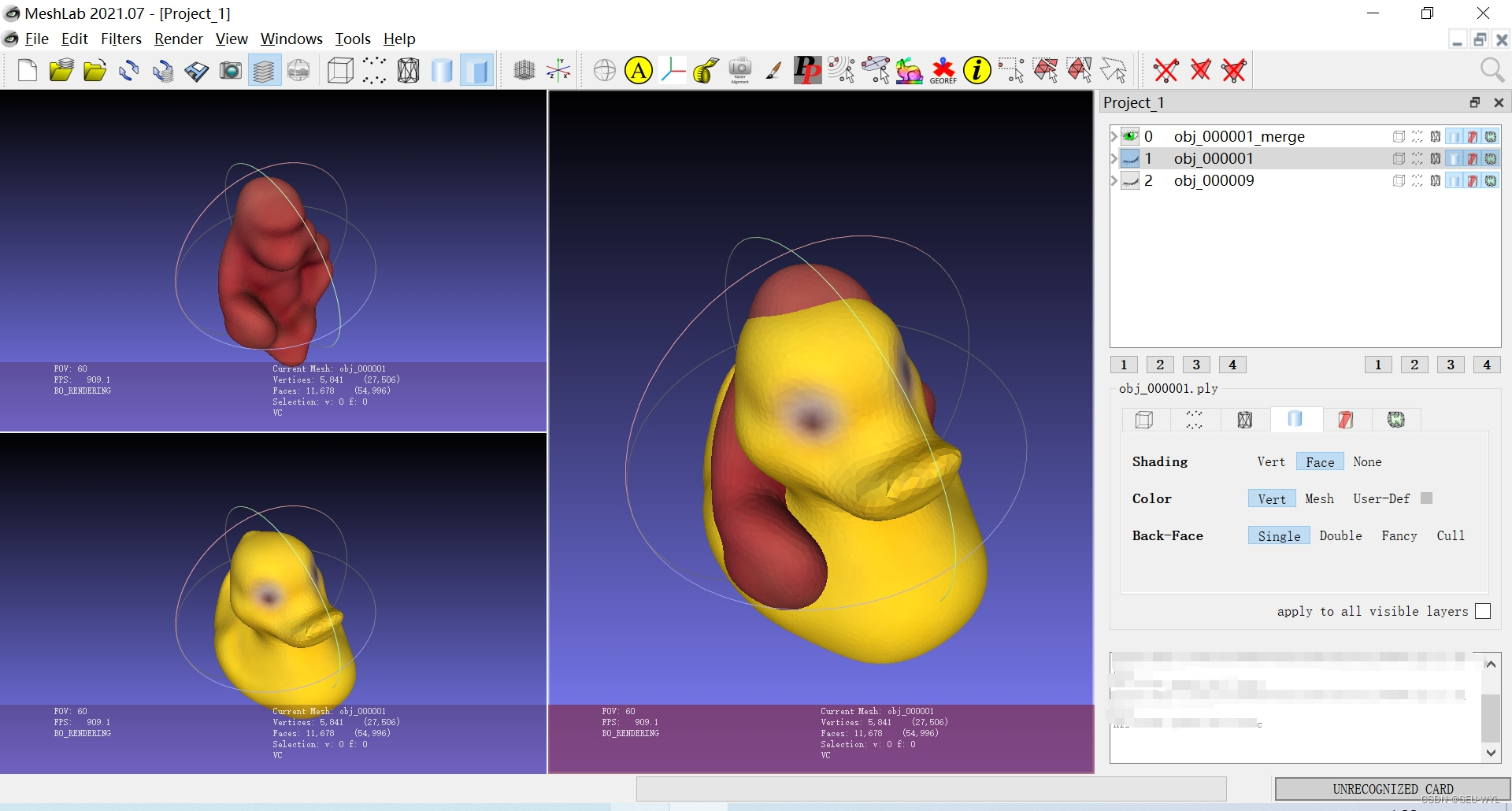
# pymeshlab需要导入,其一般被命名为ml
import pymeshlab as ml# 本案例所使用的3D模型1为压缩包中的obj_000001.ply,请将其与本脚本放置在同一文件夹内。
input_file_1 = 'obj_000001.ply'# 本案例所使用的3D模型2为压缩包中的obj_000009.ply,请将其与本脚本放置在同一文件夹内。
input_file_2 = 'obj_000009.ply'# 首先需要创建一个空的容器
mesh = ml.MeshSet()# 然后,加载物体模型1
mesh.load_new_mesh(input_file_1)# 然后,加载物体模型2
mesh.load_new_mesh(input_file_2)# 合并物体1和物体2
mesh.flatten_visible_layers()# 保存
mesh.save_current_mesh(input_file_1.replace('.ply', '_merge.ply'), save_vertex_normal = True, binary = False)
这篇关于meshlab: pymeshlab合并多个物体模型并保存(flatten visible layers)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








