本文主要是介绍Hadoop 3.4.0+HBase2.5.8+ZooKeeper3.8.4+Hive+Sqoop 分布式高可用集群部署安装 大数据系列二,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
创建服务器,参考
虚拟机创建服务器
| 节点名字 | 节点IP | 系统版本 | ||
| master11 | 192.168.50.11 | centos 8.5 | ||
| slave12 | 192.168.50.12 | centos 8.5 | ||
| slave13 | 192.168.50.13 | centos 8.5 |
1 下载组件
Hadoop:官网地址
Hbase:官网地址
ZooKeeper:官网下载
Hive:官网下载
Sqoop:官网下载
为方便同学们下载,特整理到网盘
2 通过xftp 上传软件到服务器,统一放到/data/soft/
3 配置ZooKeeper
tar zxvf apache-zookeeper-3.8.4-bin.tar.gz
mv apache-zookeeper-3.8.4-bin/ /data/zookeeper
#修改配置文件
cd /data/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
#创建数据保存目录
mkdir -p /data/zookeeper/zkdata
mkdir -p /data/zookeeper/logs
vim zoo.cfg
dataDir=/tmp/zookeeper-->dataDir=/data/zookeeper/zkdata
dataLogDir=/data/zookeeper/logs
server.1=master11:2888:3888
server.2=slave12:2888:3888
server.3=slave13:2888:3888#配置环境变量
vim /etc/profile
export ZooKeeper_HOME=/data/zookeeper
export PATH=$PATH:$ZooKeeper_HOME/bin
source /etc/profile#新建myid并且写入对应的myid
[root@master11 zkdata]# cat myid
1
#对应修改
slave12
myid--2
slave13
myid--34 配置HBase
tar zxvf hbase-2.5.8-bin.tar.gz
mv hbase-2.5.8/ /data/hbase
mkdir -p /data/hbase/logs
#vim /etc/profile
export HBASE_LOG_DIR=/data/hbase/logs
export HBASE_MANAGES_ZK=false
export HBASE_HOME=/data/hbase
export PATH=$PATH:$ZooKeeper_HOME/bin
#vim /data/hbase/conf/regionservers
slave12
slave13
#新建backup-masters
vim /data/hbase/conf/backup-masters
slave12
#vim /data/hbase/conf/hbase-site.xml<property><name>hbase.cluster.distributed</name><value>true</value></property>
<!--HBase端口-->
<property><name>hbase.master.info.port</name><value>16010</value>
</property>
<property><name>hbase.zookeeper.quorum</name><value>master11,slave12,slave13</value></property>
<property><name>hbase.rootdir</name><value>hdfs://master11:9000/hbase</value></property>
<property><name>hbase.wal.provider</name><value>filesystem</value>
</property>5 配置hadoop
tar zxvf hadoop-3.4.0.tar.gz
mv hadoop-3.4.0/ /data/hadoop
#配置环境变量
vim /etc/profile
export HADOOP_HOME=/data/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$PATH:$HADOOP_HOME/sbin
source /etc/profile
#查看版本
[root@master11 soft]# hadoop version
Hadoop 3.4.0
Source code repository git@github.com:apache/hadoop.git -r bd8b77f398f626bb7791783192ee7a5dfaeec760
Compiled by root on 2024-03-04T06:35Z
Compiled on platform linux-x86_64
Compiled with protoc 3.21.12
From source with checksum f7fe694a3613358b38812ae9c31114e
This command was run using /data/hadoop/share/hadoop/common/hadoop-common-3.4.0.jar6 修改hadoop配置文件
#core-site.xml
vim /data/hadoop/etc/hadoop/core-site.xml
#增加如下
<configuration>
<property><name>fs.defaultFS</name><value>hdfs://master11</value>
</property>
<!-- hadoop 本地数据存储目录 format 时自动生成 -->
<property><name>hadoop.tmp.dir</name><value>/data/hadoop/data/tmp</value>
</property>
<!-- 在 WebUI访问 HDFS 使用的用户名。-->
<property><name>hadoop.http.staticuser.user</name><value>root</value>
</property>
<property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value>
</property>
<property><name>hadoop.proxyuser.root.hosts</name><value>*</value>
</property>
<property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property>
<property><name>ha.zookeeper.quorum</name><value>master11:2181,slave12:2181,slave13:2181</value></property><property><name>ha.zookeeper.session-timeout.ms</name><value>10000</value></property>
</configuration>
#hdfs-site.xml
vim /data/hadoop/etc/hadoop/hdfs-site.xml
<configuration><!-- 副本数dfs.replication默认值3,可不配置 --><property><name>dfs.replication</name><value>3</value></property><!-- 节点数据存储地址 --><property><name>dfs.namenode.name.dir</name><value>/data/hadoop/data/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>/data/hadoop/data/dfs/data</value></property><!-- 主备配置 --><!-- 为namenode集群定义一个services name --><property><name>dfs.nameservices</name><value>mycluster</value></property><!-- 声明集群有几个namenode节点 --><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><!-- 指定 RPC通信地址 的地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>master11:8020</value></property><!-- 指定 RPC通信地址 的地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>slave12:8020</value></property><!-- http通信地址 web端访问地址 --><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>master11:50070</value></property><!-- http通信地址 web 端访问地址 --><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>slave12:50070</value></property><!-- 声明journalnode集群服务器 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://master11:8485;slave12:8485;slave13:8485/mycluster</value></property><!-- 声明journalnode服务器数据存储目录 --><property><name>dfs.journalnode.edits.dir</name><value>/data/hadoop/data/dfs/jn</value></property><!-- 开启NameNode失败自动切换 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 隔离:同一时刻只能有一台服务器对外响应 --><property><name>dfs.ha.fencing.methods</name><value>sshfenceshell(/bin/true)</value></property><!-- 配置失败自动切换实现方式,通过ConfiguredFailoverProxyProvider这个类实现自动切换 --><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 指定上述选项ssh通讯使用的密钥文件在系统中的位置。 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- 配置sshfence隔离机制超时时间(active异常,standby如果没有在30秒之内未连接上,那么standby将变成active) --><property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value></property><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property>
<!-- 开启hdfs允许创建目录的权限,配置hdfs-site.xml --><property><name>dfs.permissions.enabled</name><value>false</value></property><!-- 使用host+hostName的配置方式 --><property><name>dfs.namenode.datanode.registration.ip-hostname-check</name><value>false</value></property>
<property><name>dfs.webhdfs.enabled</name><value>true</value>
</property>
<!-- 开启自动化: 启动zkfc -->
<property><name>dfs.ha.automatic-failover.enabled</name><value>true</value>
</property>
<property><name>ipc.client.connect.max.retries</name><value>100</value><description>Indicates the number of retries a client will make to establish a server connection.</description>
</property>
<property><name>ipc.client.connect.retry.interval</name><value>10000</value><description>Indicates the number of milliseconds a client will wait for before retrying to establish a server connection.</description>
</property></configuration>
#yarn-site.xml
vi /data/hadoop/etc/hadoop/yarn-site.xml
<configuration><!-- 指定yarn占电脑资源,默认8核8g --><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>2</value>
</property>
<property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value>
</property><property><name>yarn.log.server.url</name><value>http://node10:19888/jobhistory/logs</value>
</property><!-- 指定 MR 走 shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 开启日志聚集功能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置日志保留时间为 7 天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>86400</value></property><!-- 主备配置 --><!-- 启用resourcemanager ha --><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.cluster-id</name><value>my-yarn-cluster</value></property><!-- 声明两台resourcemanager的地址 --><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>slave12</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>slave13</value></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>slave12:8088</value></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>slave13:8088</value></property><!-- 指定zookeeper集群的地址 --><property><name>yarn.resourcemanager.zk-address</name><value>master11:2181,slave12:2181,slave13:2181</value></property><!-- 启用自动恢复 --><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><!-- 指定resourcemanager的状态信息存储在zookeeper集群 --><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>2048</value></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>2048</value></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value></property><property><name>mapred.child.java.opts</name><value>-Xmx1024m</value></property><property><name>yarn.resourcemanager.address.rm1</name><value>slave12:8032</value></property><property><name>yarn.resourcemanager.scheduler.address.rm1</name><value>slave12:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address.rm1</name><value>slave12:8031</value></property><property><name>yarn.resourcemanager.admin.address.rm1</name><value>slave12:8033</value></property><property><name>yarn.nodemanager.address.rm1</name><value>slave12:8041</value></property><property><name>yarn.resourcemanager.address.rm2</name><value>slave13:8032</value></property><property><name>yarn.resourcemanager.scheduler.address.rm2</name><value>slave13:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address.rm2</name><value>slave13:8031</value></property><property><name>yarn.resourcemanager.admin.address.rm2</name><value>slave13:8033</value></property><property><name>yarn.nodemanager.address.rm2</name><value>slave13:8041</value></property><property><name>yarn.nodemanager.localizer.address</name><value>0.0.0.0:8040</value></property><property><description>NM Webapp address.</description><name>yarn.nodemanager.webapp.address</name><value>0.0.0.0:8042</value></property>
<property><name>yarn.nodemanager.address</name><value>${yarn.resourcemanager.hostname}:8041</value>
</property>
<property><name>yarn.application.classpath</name><value>/data/hadoop/etc/hadoop:/data/hadoop/share/hadoop/common/lib/*:/data/hadoop/share/hadoop/common/*:/data/hadoop/share/hadoop/hdfs:/data/hadoop/share/hadoop/hdfs/lib/*:/data/hadoop/share/hadoop/hdfs/*:/data/hadoop/share/hadoop/mapreduce/lib/*:/data/hadoop/share/hadoop/mapreduce/*:/data/hadoop/share/hadoop/yarn:/data/hadoop/share/hadoop/yarn/lib/*
:/data/hadoop/share/hadoop/yarn/*</value> </property>
</configuration>
#修改workers
vi /data/hadoop/etc/hadoop/workers
master11
slave12
slave137 分发文件和配置
#master11
cd /data/
scp -r hadoop/ slave12:/data
scp -r hadoop/ slave13:/data
scp -r hbase/ slave13:/data
scp -r hbase/ slave12:/data
scp -r zookeeper/ slave12:/data
scp -r zookeeper/ slave13:/data
#3台服务器的/etc/profile 变量一致
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export CLASSPATHexport HADOOP_HOME=/data/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$PATH:$HADOOP_HOME/sbin
export ZooKeeper_HOME=/data/zookeeper
export PATH=$PATH:$ZooKeeper_HOME/bin
#
export HBASE_LOG_DIR=/data/hbase/logs
export HBASE_MANAGES_ZK=false
export HBASE_HOME=/data/hbase
export PATH=$PATH:$ZooKeeper_HOME/binexport HIVE_HOME=/data/hive
export PATH=$PATH:$HIVE_HOME/bin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_ZKFC_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_JOURNALNODE_USER=root
8 集群启动
#HA模式第一次或删除在格式化版本
#第一次需要格式化,master11上面
start-dfs.sh
hdfs namenode -format
ll /data/hadoop/data/dfs/name/current/
total 16
-rw-r--r--. 1 root root 399 May 13 20:21 fsimage_0000000000000000000
-rw-r--r--. 1 root root 62 May 13 20:21 fsimage_0000000000000000000.md5
-rw-r--r--. 1 root root 2 May 13 20:21 seen_txid
-rw-r--r--. 1 root root 218 May 13 20:21 VERSION
#同步数据到slave12节点(其余namenode节点)
scp -r /data/hadoop/data/dfs/name/* slave12:/data/hadoop/data/dfs/name/
#成功如图
#在任意一台 NameNode上初始化 ZooKeeper 中的 HA 状态
[root@master11 hadoop]# jps
2400 QuorumPeerMain
4897 Jps
3620 JournalNode
3383 DataNode
#
hdfs zkfc -formatZK
#如下图 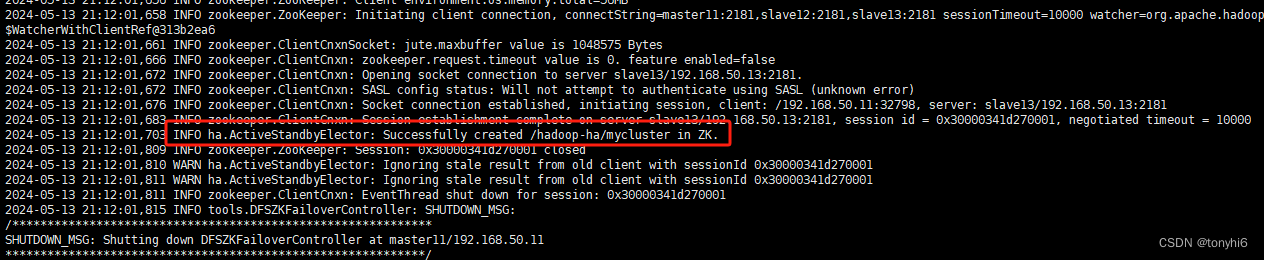
#集群正常启动顺序
#zookeeper,3台服务器都执行
zkServer.sh start
#查看
[root@master11 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@slave12 data]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
[root@slave13 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
#master11 ,hadoop集群一键启动
start-all.sh start
#一键停止
stop-all.sh
#jps 查看如图 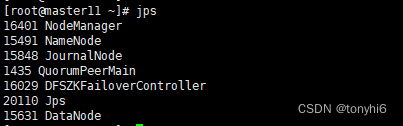
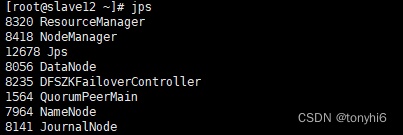

#查看集群状态
#NameNode
[root@master11 ~]# hdfs haadmin -getServiceState nn1
active
[root@master11 ~]# hdfs haadmin -getServiceState nn2
standby
[root@master11 ~]# hdfs haadmin -ns mycluster -getAllServiceState
master11:8020 active
slave12:8020 standby
#yarn
[root@master11 ~]# yarn rmadmin -getServiceState rm1
standby
[root@master11 ~]# yarn rmadmin -getServiceState rm2
active
#查看HDFS web ui
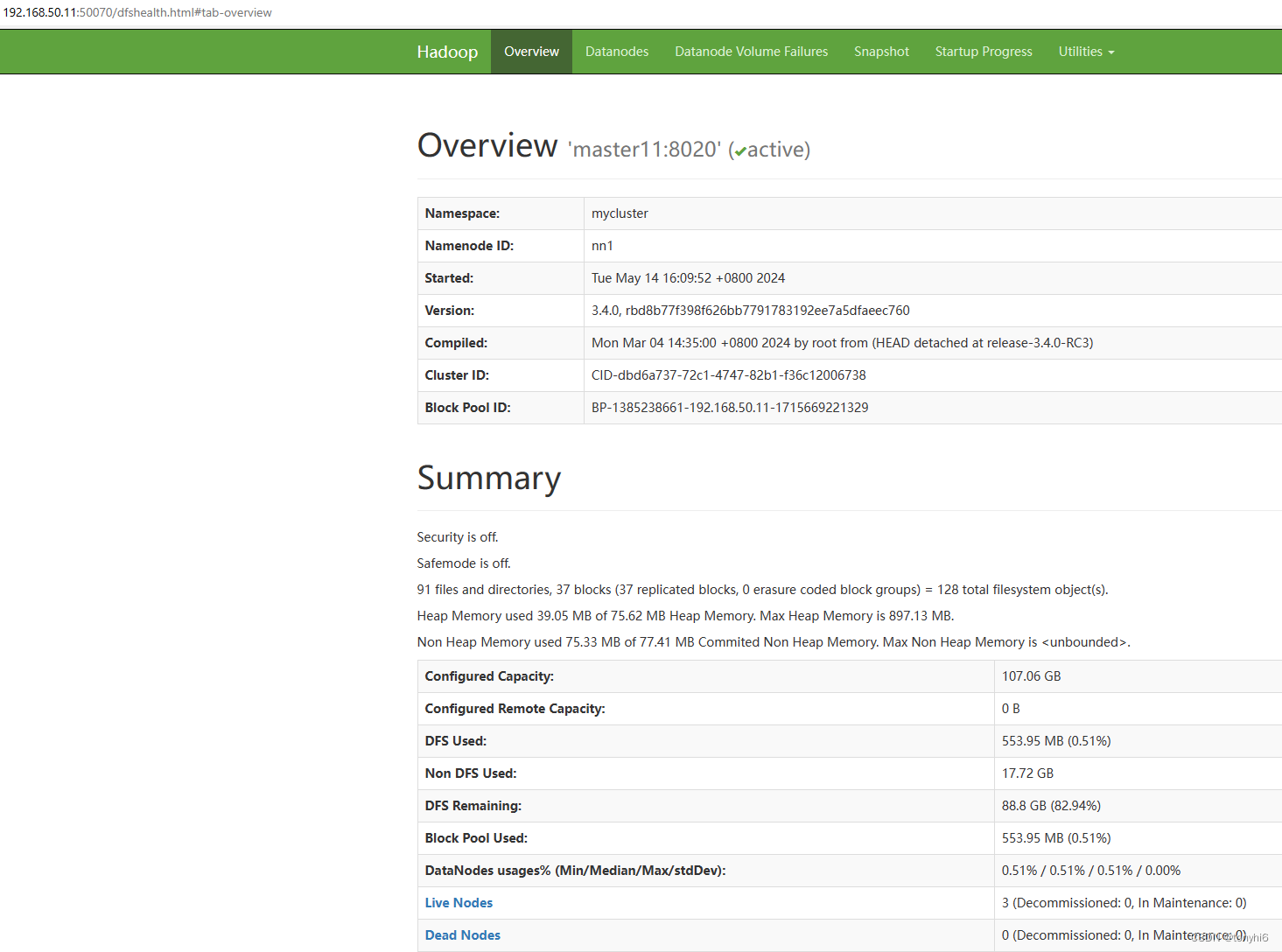
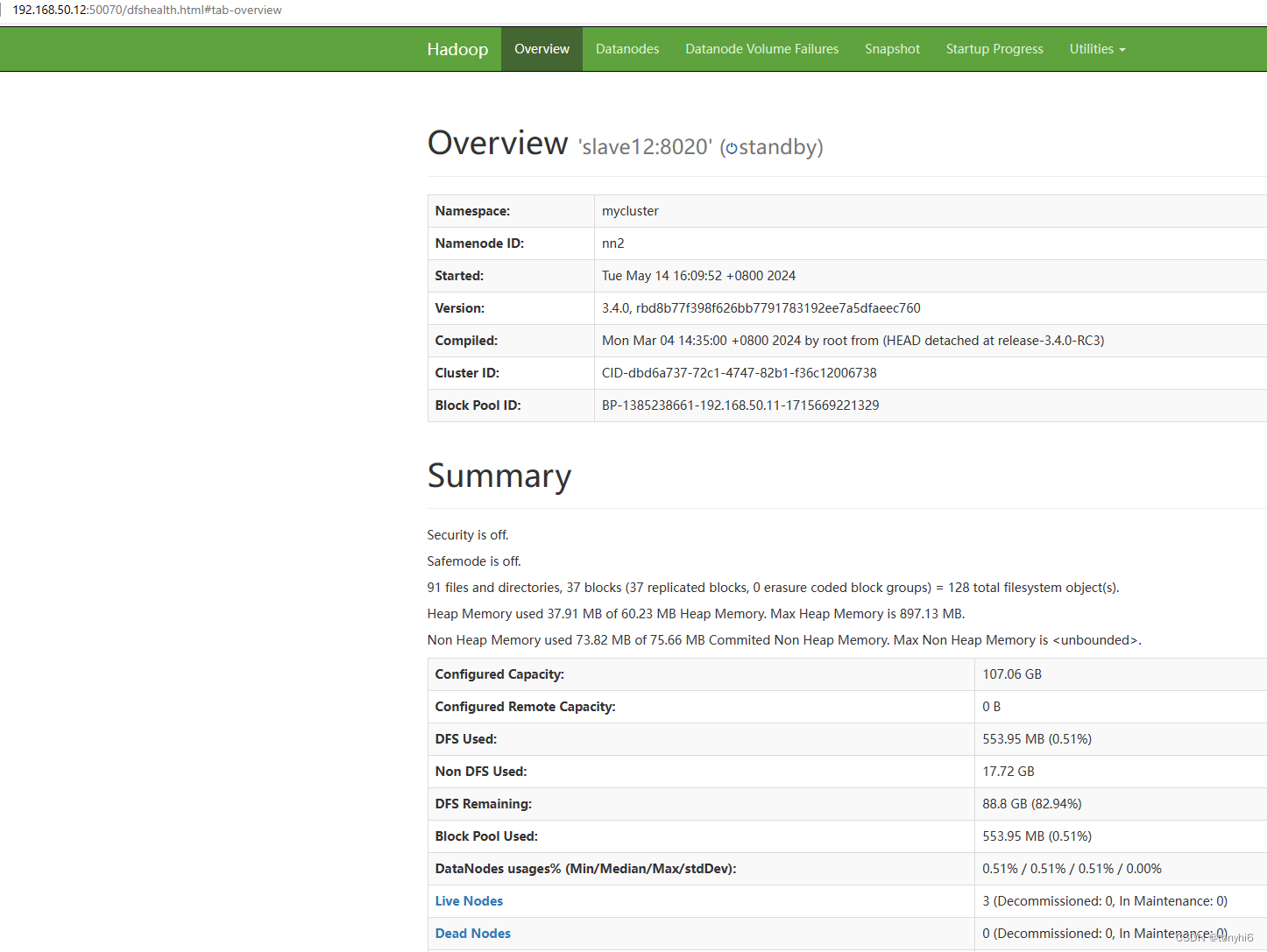
#查看 yarn集群
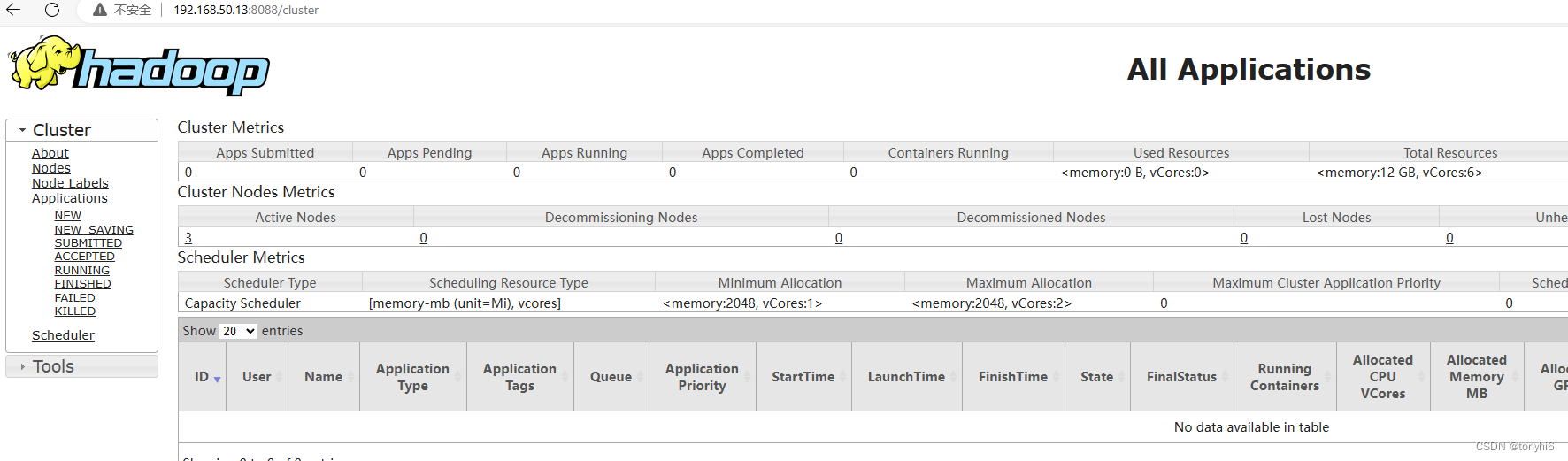
9 hadoop 测试使用
#创建目录
hdfs dchaungfs -mkdir /testdata
#查看
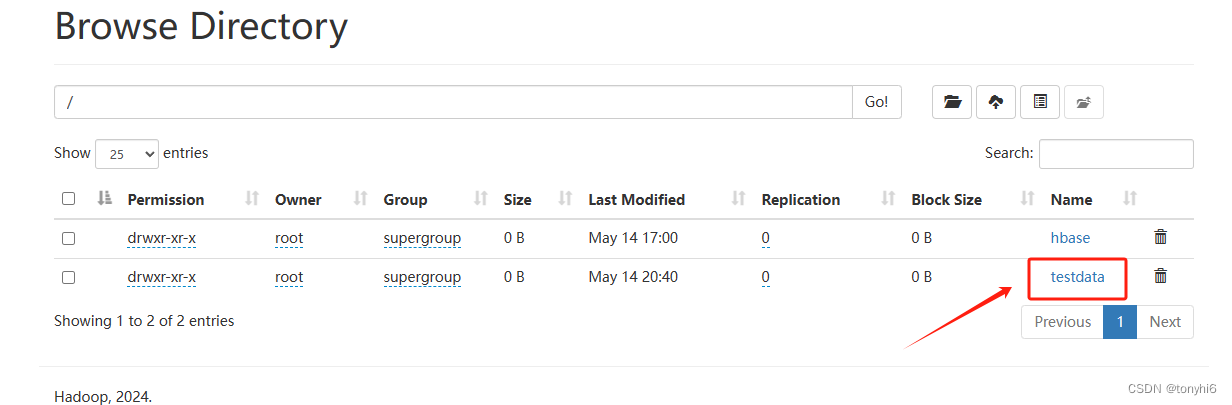
[root@master11 ~]# hdfs dfs -ls /
Found 2 items
drwxr-xr-x - root supergroup 0 2024-05-14 17:00 /hbase
drwxr-xr-x - root supergroup 0 2024-05-14 20:32 /testdata
#上传文件
hdfs dfs -put jdk-8u191-linux-x64.tar.gz /testdata
#查看文件
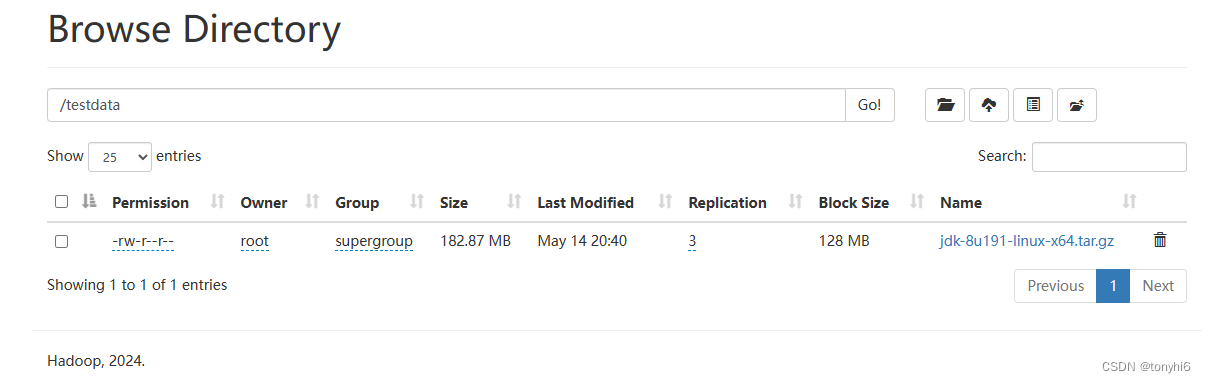
[root@master11 soft]# hdfs dfs -ls /testdata/
Found 1 items
-rw-r--r-- 3 root supergroup 191753373 2024-05-14 20:40 /testdata/jdk-8u191-linux-x64.tar.gz 
10 启动Hbase,hadoop的active节点
[root@master11 ~]# hdfs haadmin -getServiceState nn1
active
#启动
start-hbase.sh
#查看
[root@master11 ~]# jps
16401 NodeManager
15491 NameNode
21543 HMaster
15848 JournalNode
1435 QuorumPeerMain
16029 DFSZKFailoverController
21902 Jps
15631 DataNode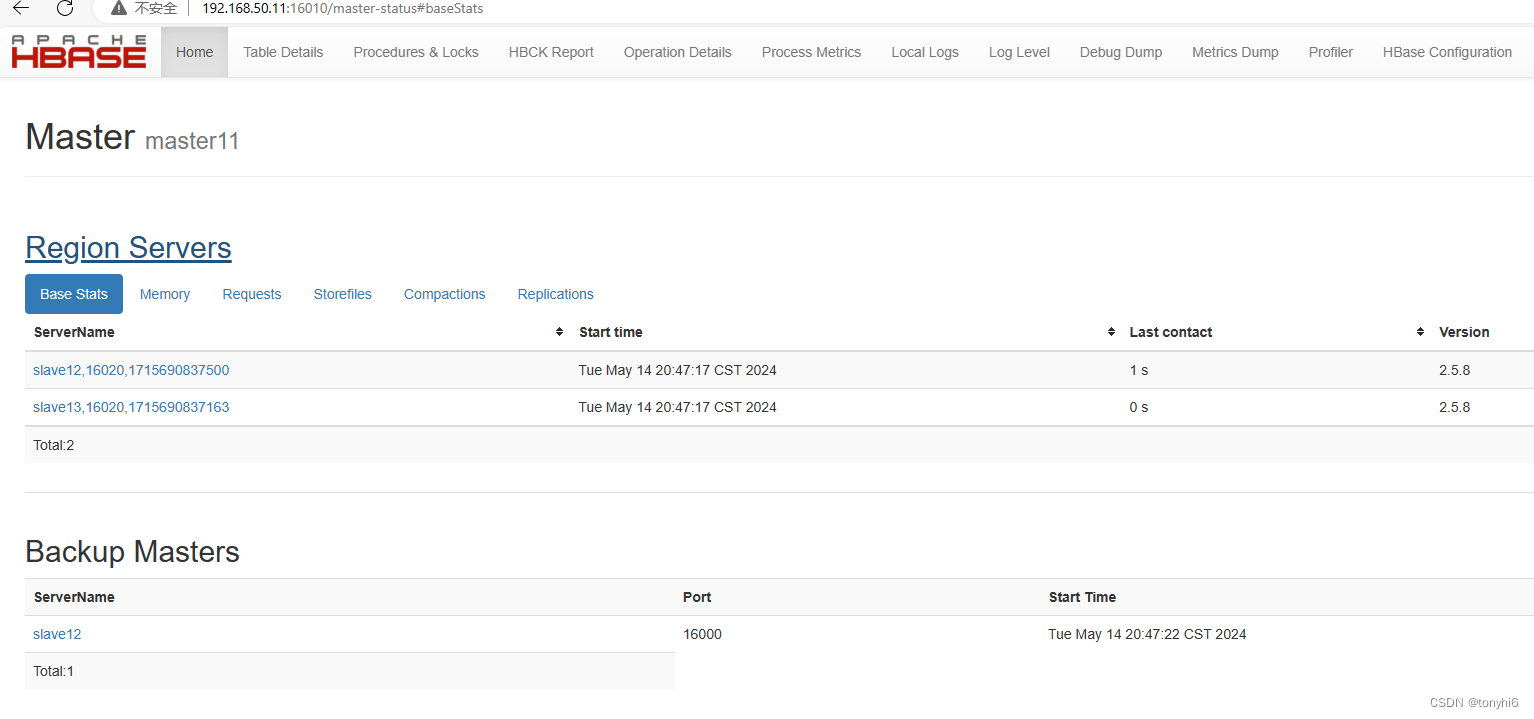 11 安装Hive
11 安装Hive
#解压和配置环境变量
tar zxvf apache-hive-4.0.0-bin.tar.gz
mv apache-hive-4.0.0-bin/ /data/hive
#环境变量
vi /etc/profile
export HIVE_HOME=/data/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile# 安装mysql ,可参考
mysql 8.3 二进制版本安装
#mysql驱动
mv mysql-connector-java-8.0.29.jar /data/hive/lib/schematool -dbType mysql -initSchema
#报错
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/data/hive/lib/log4j-slf4j-impl-2.18.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/data/hadoop/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Exception in thread "main" [com.ctc.wstx.exc.WstxLazyException] com.ctc.wstx.exc.WstxUnexpectedCharException: Unexpected character '=' (code 61); expected a semi-colon after the reference for entity 'characterEncoding'at [row,col,system-id]: [5,86,"file:/data/hive/conf/hive-site.xml"]at com.ctc.wstx.exc.WstxLazyException.throwLazily(WstxLazyException.java:40)at com.ctc.wstx.sr.StreamScanner.throwLazyError(StreamScanner.java:737)at com.ctc.wstx.sr.BasicStreamReader.safeFinishToken(BasicStreamReader.java:3745)at com.ctc.wstx.sr.BasicStreamReader.getTextCharacters(BasicStreamReader.java:914)at org.apache.hadoop.conf.Configuration$Parser.parseNext(Configuration.java:3434)at org.apache.hadoop.conf.Configuration$Parser.parse(Configuration.java:3213)at org.apache.hadoop.conf.Configuration.loadResource(Configuration.java:3106)at org.apache.hadoop.conf.Configuration.loadResources(Configuration.java:3072)at org.apache.hadoop.conf.Configuration.loadProps(Configuration.java:2945)at org.apache.hadoop.conf.Configuration.getProps(Configuration.java:2927)at org.apache.hadoop.conf.Configuration.set(Configuration.java:1431)at org.apache.hadoop.conf.Configuration.set(Configuration.java:1403)at org.apache.hadoop.hive.metastore.conf.MetastoreConf.newMetastoreConf(MetastoreConf.java:2120)at org.apache.hadoop.hive.metastore.conf.MetastoreConf.newMetastoreConf(MetastoreConf.java:2072)at org.apache.hive.beeline.schematool.HiveSchemaTool.main(HiveSchemaTool.java:144)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.hadoop.util.RunJar.run(RunJar.java:330)at org.apache.hadoop.util.RunJar.main(RunJar.java:245)
Caused by: com.ctc.wstx.exc.WstxUnexpectedCharException: Unexpected character '=' (code 61); expected a semi-colon after the reference for entity 'characterEncoding'at [row,col,system-id]: [5,86,"file:/data/hive/conf/hive-site.xml"]at com.ctc.wstx.sr.StreamScanner.throwUnexpectedChar(StreamScanner.java:666)at com.ctc.wstx.sr.StreamScanner.parseEntityName(StreamScanner.java:2080)at com.ctc.wstx.sr.StreamScanner.fullyResolveEntity(StreamScanner.java:1538)at com.ctc.wstx.sr.BasicStreamReader.readTextSecondary(BasicStreamReader.java:4765)at com.ctc.wstx.sr.BasicStreamReader.finishToken(BasicStreamReader.java:3789)at com.ctc.wstx.sr.BasicStreamReader.safeFinishToken(BasicStreamReader.java:3743)... 18 more
#解决 vi /data/hive/conf/hive-site.xml
&字符 需要转义 改成 &
#成功提示 Initialization script completed
数据库如下图
#启动,hive 在master11,mysql 安装在slave12
cd /data/hive/
nohup hive --service metastore & (启动hive元数据服务)
nohup ./bin/hiveserver2 & (启动jdbc连接服务)
#直接hive,提示“No current connection”
hive
[root@master11 hive]# hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/data/hive/lib/log4j-slf4j-impl-2.18.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/data/hadoop/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/data/hive/lib/log4j-slf4j-impl-2.18.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/data/hadoop/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 4.0.0 by Apache Hive
beeline> show databases;
No current connection
beeline>
#在提示符 输入!connect jdbc:hive2://master11:10000,之后输入mysql用户和密码
beeline> !connect jdbc:hive2://master11:10000
Connecting to jdbc:hive2://master11:10000
Enter username for jdbc:hive2://master11:10000: root
Enter password for jdbc:hive2://master11:10000: *********
Connected to: Apache Hive (version 4.0.0)
Driver: Hive JDBC (version 4.0.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://master11:10000> show databases;
INFO : Compiling command(queryId=root_20240514222349_ac19af6a-3c43-49fd-bcd0-25fc0e5b76c6): show databases
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=root_20240514222349_ac19af6a-3c43-49fd-bcd0-25fc0e5b76c6); Time taken: 0.021 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20240514222349_ac19af6a-3c43-49fd-bcd0-25fc0e5b76c6): show databases
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20240514222349_ac19af6a-3c43-49fd-bcd0-25fc0e5b76c6); Time taken: 0.017 seconds
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (0.124 seconds)
0: jdbc:hive2://master11:10000>这篇关于Hadoop 3.4.0+HBase2.5.8+ZooKeeper3.8.4+Hive+Sqoop 分布式高可用集群部署安装 大数据系列二的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







