本文主要是介绍Question about kNN Algorithm,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
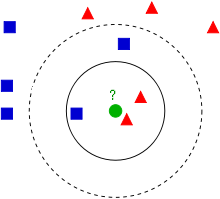
kNN算法中K表示最接近自己的K个数据样本例如下图绿色的圆形是我们待分类的数据。根据kNN算法:
- 如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
- 如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。

当遇到下列这种情况:
- 如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
- 如果K=4,那么离绿色点最近的有2个红色三角形和2个蓝色的正方形,这4个点投票,那么绿色的这个待分类点应该属于哪一个类型呢?
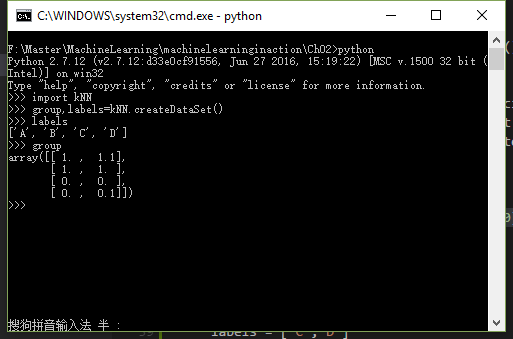
Python代码试验:构造四个四个点A(1,1.1)、B(1,1)、C(0,0)、D(0,0.1)
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','B','C','D']
return group, labels
kNN待分类数据点(0.5,0.5),与各邻近数据点的欧氏距离的平方分别为:
Distan(A)=0.25+0.36=0.61
Distan(B)=0.5
Distan(C)=0.5
Distan(D)=0.25+0.16=0.41
当k=1,最邻一点只有D,预计推荐结果为D

当k=2,待测点与B、C点距离相等,实际kNN推荐结果为B

当k=3,相邻3点有B、C、D,最近为D,实际kNN推荐结果为C

当k=4,相邻4点有A、B、C、D,最近为D,最远为A,实际kNN推荐结果为A

问题总结:
在kNN算法中,当k取值为类别组数的偶数时,如何得出推荐结果?
kNN分类算法:
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
kNN算法本身简单有效,它是一种lazy-learning算法,分类器不需要使用训练集进行训练,训练时间复杂度为0。kNN分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为n,那么kNN的分类时间复杂度为O(n)。
这篇关于Question about kNN Algorithm的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[Algorithm][综合训练][栈和排序][加减]详细讲解](https://i-blog.csdnimg.cn/direct/7df413c28a644b6097dcfa5df3fb027c.png)