本文主要是介绍GEE案例分析——利用多时 Sentinel-1/2 和 Landsat-8/9 遥感数据在GEE中使用机器学习方法进行作物类时序分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
准确绘制作物类型图对于确保粮食安全至关重要。遥感(RS)卫星数据空间覆盖面广,时间频率高,是这一领域前景广阔的工具。然而,由于作物的类内和类间变异性很高,利用 RS 数据进行准确的作物类型分类方法的需求仍在不断增长。为此,本研究提出了一种新颖的并行级联集合结构(Pa-PCA-Ca),在谷歌地球引擎(GEE)中包含七个目标类别。Pa 部分由五个并行分支组成,每个分支利用多时 Sentinel-1/2 和 Landsat-8/9 卫星图像以及机器学习(ML)模型为不同的目标类别生成概率图(PM)。PMs 在每个目标类别中都显示出高度相关性,因此有必要使用最相关的信息来降低 Ca 部分的输入维度。因此,我们采用了主成分分析法(PCA)来提取不相关的最高成分。然后在 Ca 结构中使用这些分量,并使用另一个称为元模型的 ML 模型进行最终分类。Pa-PCA-Ca 模型是利用在伊朗西北部广泛实地勘测收集到的现场数据进行评估的。结果表明,所提议的结构性能优越,总体准确率 (OA) 达到 96.25%,Kappa 系数达到 0.955。加入 PCA 后,OA 提高了 6%以上。此外,所提出的模型明显优于传统的分类方法,后者只是简单地将 RS 数据源堆叠起来,并将其输入到一个单一的 ML 模型中,从而使 OA 提高了 10%。
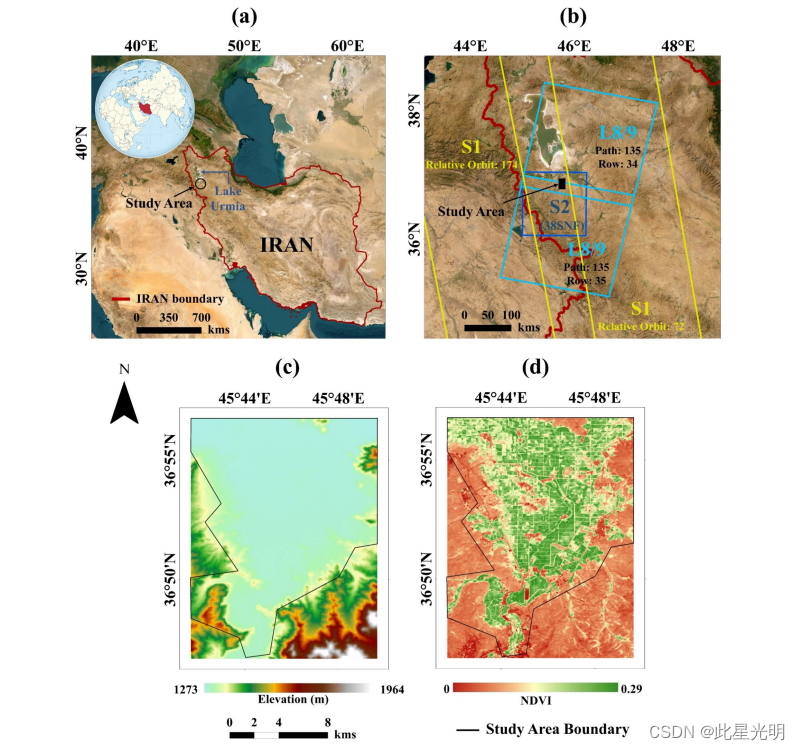
本文提出了一种新颖的集成机器学习模型(Parallel-Cascaded ensemble stru
这篇关于GEE案例分析——利用多时 Sentinel-1/2 和 Landsat-8/9 遥感数据在GEE中使用机器学习方法进行作物类时序分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





