本文主要是介绍AI绘画神级Stable Diffusion入门教程|快速入门SD绘画原理与安装,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是Stable Diffusion,什么是炼丹师?根据市场研究机构预测,到2025年全球AI绘画市场规模将达到100亿美元,其中Stable Diffusion(简称SD)作为一种先进的图像生成技术之一,市场份额也在不断增长,越来越多的人参与到AI掘金这场运动中来。炼丹师,就是指那些专门研究、开发与应用Stable Diffusion模型的专业人士或爱好者,他们在实践中不断优化模型,使其产生更高质量、更具创意的图像。
一、SD绘画原理
基本概念
| 名词 | 解释说明 |
| Stable Diffusion | 是一种基于扩散模型的先进的人工智能技术,特别适用于文本到图像(Text-to-Image)的生成任务。该模型由CompVis、Stability AI、LAION等研究机构和公司合作研发,它利用扩散过程在潜在空间(latent space)中生成图像,而不是直接在高维像素空间中操作。 |
| SD WebUI | Stable Diffusion Web UI (SD WebUI) 是一个用于交互式控制和使用 Stable Diffusion 模型的网页应用程序界面。用户可以通过这个界面输入文本提示(prompt)来驱动模型生成相应的图像,提供了简单易用的方式来体验和定制基于 Stable Diffusion 的文本到图像生成过程。 |
| Python | 是一种广泛使用的高级编程语言,以其语法简洁清晰和代码可读性强而著称。在AI领域,Python尤为流行,因为它拥有丰富的科学计算、机器学习和数据处理相关的库,比如NumPy、Pandas和TensorFlow等。在部署和使用像Stable Diffusion这样的深度学习模型时,Python常被作为开发和运行环境的基础。 |
| Controlnet插件 | 是针对 Stable Diffusion 模型开发的一种功能扩展插件,它允许用户在文本生成图像的过程中实现更为细致和精确的控制。该插件使得用户不仅能够通过文本提示(prompt)指导模型生成图像,还能添加额外的输入条件,比如控制图像的构图、颜色、纹理、物体位置、人物姿势、景深、线条草图、图像分割等多种图像特征。通过这种方式,ControlNet 提升了 AI 绘画系统的可控性和灵活性,使得艺术创作和图像编辑更加精细化。 |
| Controlnet模型 | 是配合上述插件工作的一个组成部分,它是经过训练以实现对大型预训练扩散模型(如 Stable Diffusion)进行细粒度控制的附加神经网络模型。ControlNet 模型可以学习如何根据用户的特定需求去调整原始扩散模型的输出,即便是在训练数据有限的情况下,依然能够确保生成结果的质量和稳定性。例如,ControlNet 可能包括用于识别和利用边缘映射、分割映射或关键点信息的子模块,从而实现对生成图像的特定区域进行针对性修改或强化。 |
| VAE | Variational Autoencoder (VAE): 变分自编码器是一种概率生成模型,它结合了编码器(将输入数据编码为潜在空间中的概率分布)和解码器(从潜在空间重构数据)的概念。在图像生成场景中,VAE可以用来学习数据的潜在表示,并基于这些表示生成新的图像。 |
| CHECKPOINT | SD能够绘图的基础模型,因此被称为大模型、底模型或者主模型,WebUI上就叫它Stable Diffusion模型。安装完SD软件后,必须搭配主模型才能使用。不同的主模型,其画风和擅长的领域会有侧重。checkpoint模型包含生成图像所需的一切,不需要额外的文件。 |
| hyper-network | 超网络是一种模型微调技术,最初是由NOVA AI 公司开发的。它是一个附属于Stable Diffusion 稳定扩散模型的小型神经网络,是一种额外训练出来的辅助模型,用于修正SD稳定扩散模型的风格。 |
| LORA | 全称是Low-Rank Adaptation of Large Language Models 低秩的适应大语言模型,可以理解为SD模型的一种插件,和hyper-network,controlNet一样,都是在不修改SD模型的前提下,利用少量数据训练出一种画风/IP/人物,实现定制化需求,所需的训练资源比训练SD模要小很多,非常适合社区使用者和个人开发者。LoRA最初应用于NLP领域,用于微调GPT-3等模型(也就是ChatGPT的前生)。由于GPT参数量超过千亿,训练成本太高,因此LoRA采用了一个办法,仅训练低秩矩阵(low rank matrics),使用时将LoRA模型的参数注入(inject)SD模型,从而改变SD模型的生成风格,或者为SD模型添加新的人物/IP。 |
prompt | 提示词/咒语 |
工作原理
Stable Diffusion就是一个接收文本提示词,并生成相应图像的生成模型。

SD来自于扩散模型(Diffusion Model)

扩散模型:(Diffusion Model)的核心原理被生动地比喻为物理学中的扩散过程,通过前向扩散过程逐渐将图像转化为噪声图像,然后通过反向扩散过程恢复出清晰的图像。在Stable Diffusion中,模型训练了一个噪声预测器(noise predictor),它是一个U-Net结构的神经网络,可以预测并从图像中去除噪声,从而重构原始图像。
然而,传统的扩散模型在图像空间中的运算效率极低,不适合实时应用。为此,Stable Diffusion采用了在潜在空间(latent space)中进行扩散的过程,利用变分自编码器(VAE)将图像压缩到较低维度的空间,极大地提高了计算速度和效率。
Stable Diffusion的具体工作流程包括:
-
输入图像被编码到潜在空间。
-
添加噪声,并通过噪声预测器估算添加的噪声量。
-
反复迭代,通过噪声预测器预测并减去潜在噪声。
-
使用VAE的解码器将清理过的潜在图像转换回像素空间,生成最终图像。
学习资料
国外一手资料:
stability.ai官网
https://stability.ai/aboutgithub开源项目
https://github.com/CompVis/stable-diffusion/blob/main/README.md
The Illustrated Stable Diffusion @Jay Alammar 讲的原理
https://jalammar.github.io/illustrated-stable-diffusion/
二、本地部署安装SD WebUI
硬件条件
说明:本地部署的硬件要求,当然使用云端部署租赁更高端的机器也是没问题。
最低推荐配置 | 推荐配置 | 备注 | |
显卡(GPU) | GTX1050Ti | 低配推荐:RTX4060Ti-16G高配推荐:RTX4090 | 为达到良好的体验,请尽可能使用8GB显存及以上显卡。低显存虽然能跑,但是体验极差 |
内存(RAM) | 8GB内存 | 总内存24GB及以上 | 可以开启虚拟内存,内存过小会在加载模型的时候出现问题 |
存储空间 | 20GB任意存储设备 | 500GB以上固态硬盘 | 强烈建议单独使用一个盘符,如果不想启动的时候等10分钟的话,那么只推荐使用SSD |
CPU | x86架构的Intel或AMD等处理器都可以, 若为Mac电脑建议使用搭载M系列芯片的机型。 | ||
- 显卡VRAM在4GB以下的会很容易遇到显存不足的问题,即使使用放大插件也就非常慢(以时间换显存)
2. 显卡较差/显存严重不足时可以开启CPU模式,但是速度非常慢。你不希望一个小时一张图的话那就别想着用CPU跑图。
软件需求
Windows:最低要求为Windows 10 64比特,请确保系统已更新至最新版本。
macOS:最低要求为macOS Monterey (12.5),如果可以的话请使用最新版macOS。建议使用搭载Apple Silicon M芯片 (M1、M2) 的Mac机型。旧款Mac需配备AMD独立显卡,只有Intel核显的不能使用。
下载地址 (不藏着掖着,直接拿走不谢)
SD WebUI秋叶整合包与SD Webui绘世启动器
请看文末扫描获取
SD WebUI秋叶整合包【A卡适配版】
请看文末扫描获取
安装部署
2024.1月 更新了最新的整合包,无需任何操作即可达到最佳速度,解压打开即用,内置启动器。
整合包做了哪些事情?打包了 Python、Git、CUDA 等等必须的环境,并且放了运行必须的模型。简单来说,整合包就是 SD-WebUI内核+启动器+安装好的环境+必须的模型。你只需下载它解压就可以直接启动运行!
特别鸣谢,安装包作者@秋葉aaaki
三、生成第一张SD绘画
启动“A启动器.exe”
加载更新
点击“一键启动”
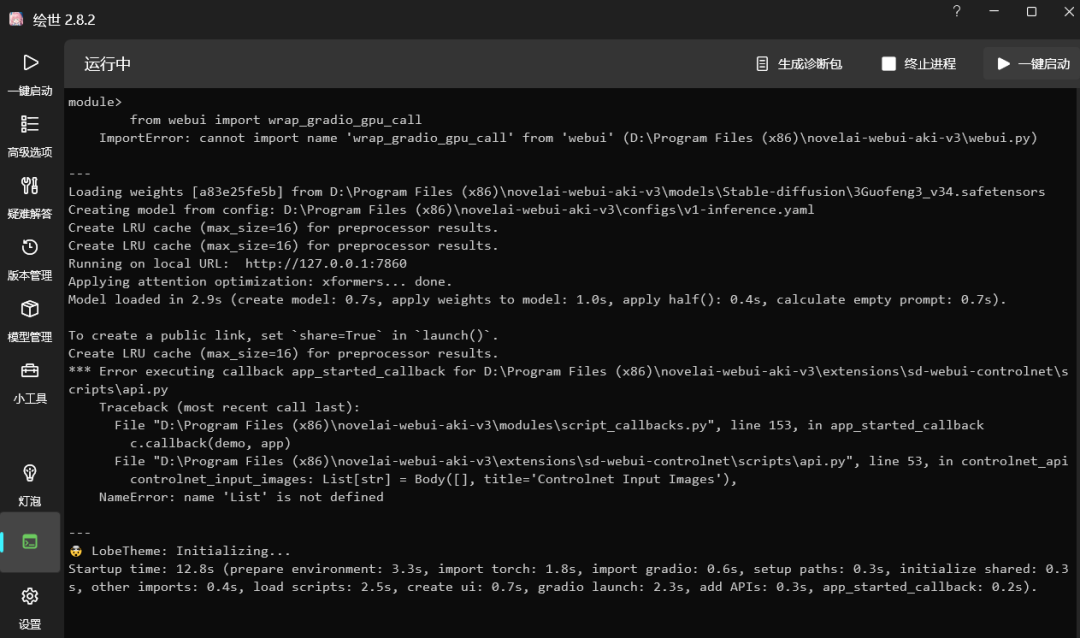
[不要关闭它],它会自动打开,浏览器地址"http://127.0.0.1:7860/?__theme=dark"
基本功能介绍
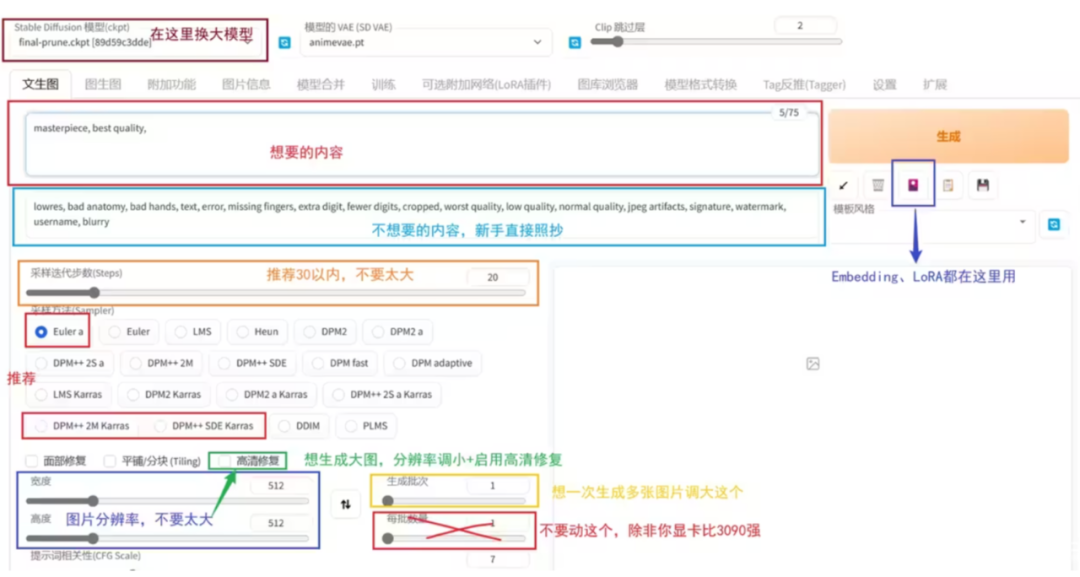
| 界面及操作说明 | |
| stable diffusion模型 | 下拉,替换大模型/底模 |
| 正面提示词 Tag | (想要的内容,提示词) 如:masterpiece, best quality, |
| 反面提示词 Tag | (不想要的内容,提示词) 如:lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry |
| 提示词加权重 | (girl) 加权重,这里是1.1倍。 ((girl)) 加很多权重,1.1*1.1=1.21倍,以此类推。 |
| 提示词减权重 | [girl] 减权重,一般用的少。减权重也一般就用下面的指定倍数。 |
| 提示词指定权重 | (girl:1.5) 指定倍数,这里是1.5倍的权重。还可以 (girl:0.9) 达到减权重的效果 |
| 采样迭代步数 | 不需要太大,一般在50以内。通常28是一个不错的值。 |
| 采样方法 | 没有优劣之分,但是他们速度不同。全看个人喜好。推荐的是图中圈出来的几个,速度效果都不错 |
| 提示词相关性 | 代表你输入的 Tag 对画面的引导程度有多大,可以理解为 “越小AI越自由发挥”,太大会出现锐化、线条变粗的效果。太小AI就自由发挥了,不看 Tag |
| 随机种子 | 生成过程中所有随机性的源头 每个种子都是一幅不一样的画。默认的 -1 是代表每次都换一个随机种子。由随机种子,生成了随机的噪声图,再交给AI进行画出来 |
切换webUI黑白皮肤,修改浏览器http地址:
白:http://127.0.0.1:7860/?__theme=light
黑:http://127.0.0.1:7860/?__theme=dark
输入提示词【1 girl】,点击生成即可:
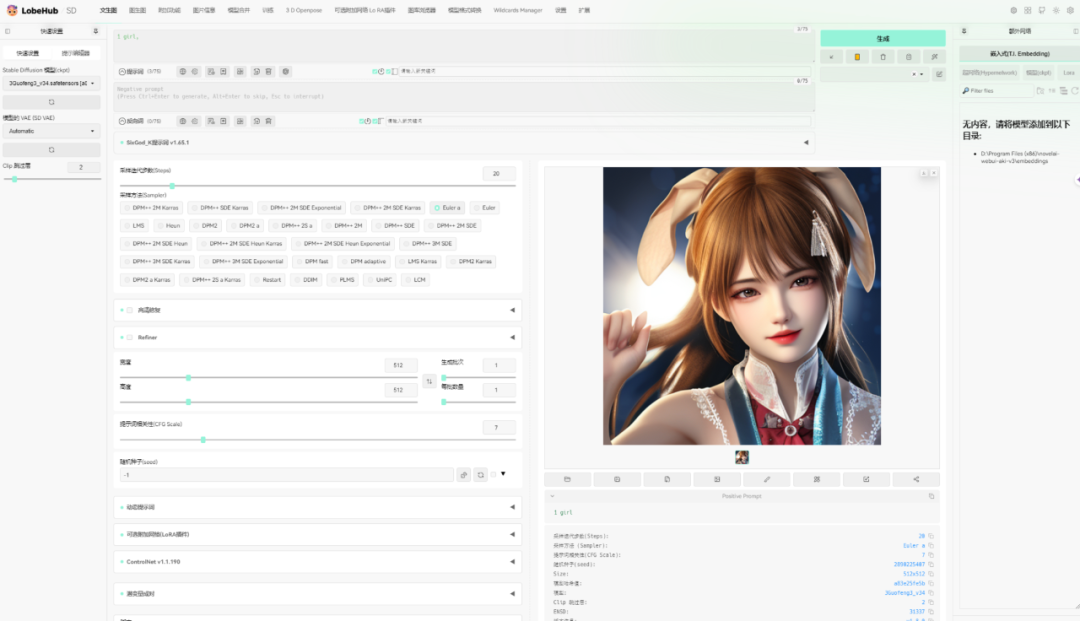
(我安装了皮肤插件,所以和你运行的界面稍微酷炫一点_)
这里直接将该软件分享出来给大家吧~
这份完整版的stable diffusion资料我已经打包好,需要的点击下方添加,即可前往免费领取!

1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方添加,即可前往免费领取!
这篇关于AI绘画神级Stable Diffusion入门教程|快速入门SD绘画原理与安装的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






