本文主要是介绍GIS数据—1984-2020中国1km人造夜间灯光观测数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
夜间灯光观测数据(Nighttime Light,NTL)是评估人类活动边界的常用手段,目前,该数据已经广泛应用于城市范围、不透水面、基础设施建设等一系列过程。今天,小编要带来的是长时间序列中国区域边界的夜间灯光观测数据。
数据说明
今天带来的数据集由清华大学付昊恒和徐冰教授共同牵头开发,并联合众多一流机构和高等学府的学者。目前数据已经在国家青藏高原科学数据中心发布。

数据集的全称为中国长时间序列逐年人造夜间灯光数据集(1984-2020)(Prolonged Artificial Nighttime-light DAtaset:PANDA-China),如果大家不想记这么长,那就记“熊猫—中国吧”,也挺有意思的。
数据格式
所有数据为单独的Tiff格式,可以使用ArcMap打开。

数据展示
1990年北京市人造夜间灯光数据

2020年北京市人造夜间灯光数据
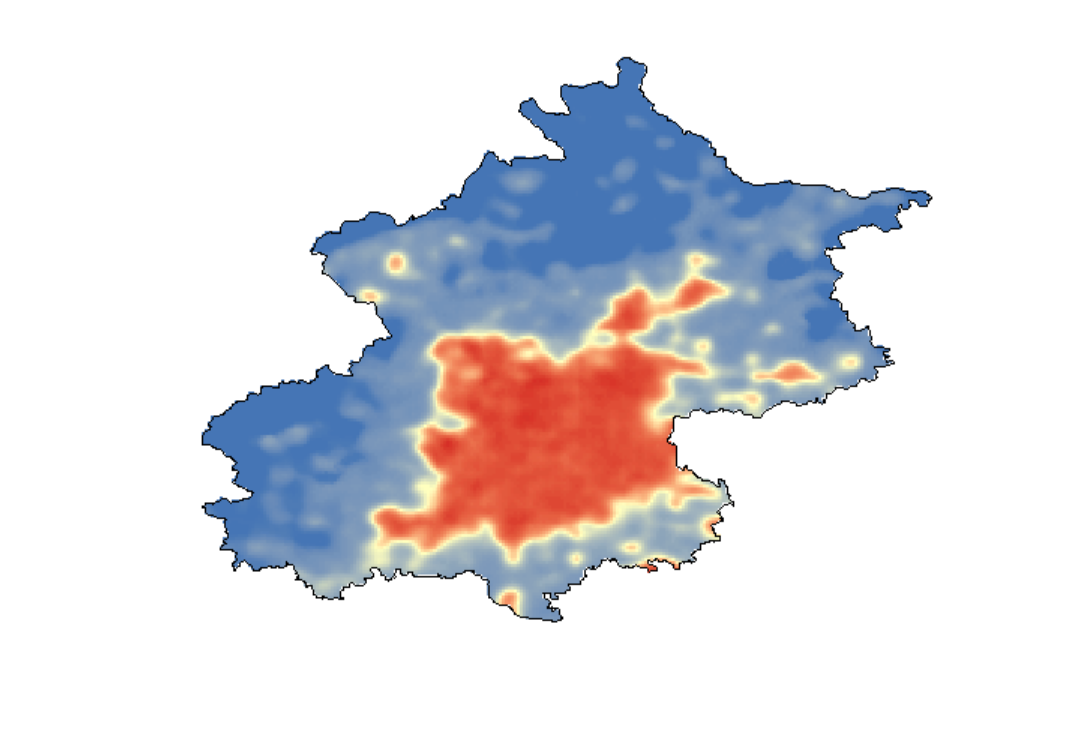
1990年山东省人造夜间灯光数据

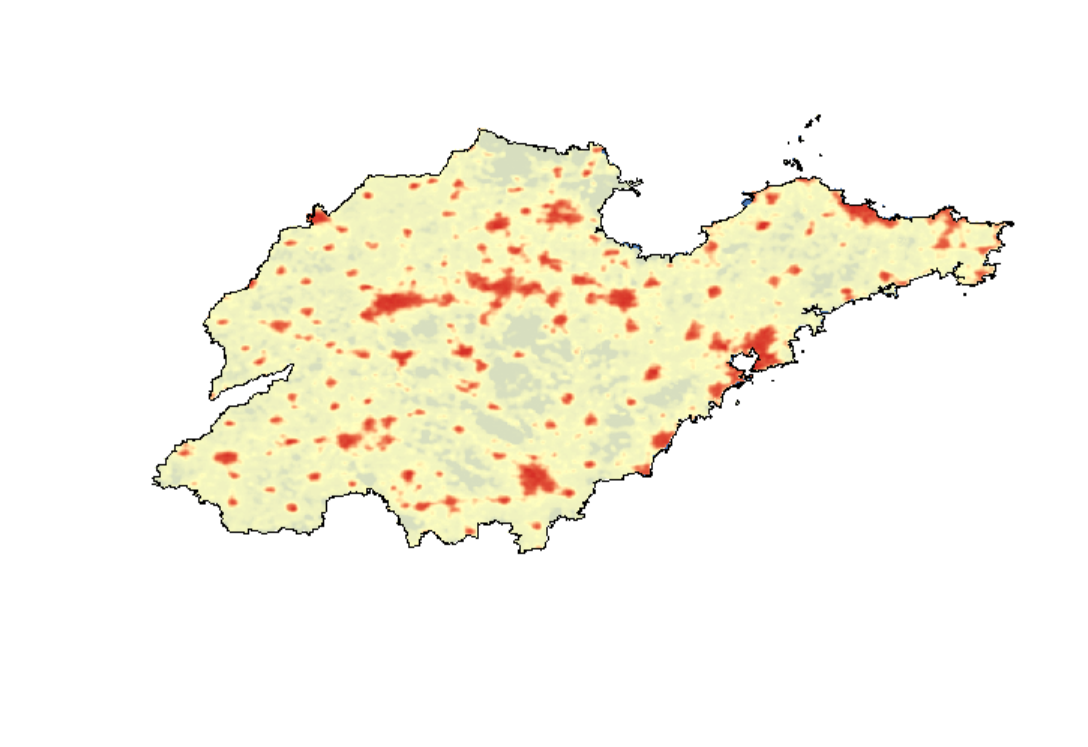
2020年山东省人造夜间灯光数据
论文阅读
如果想深入了解数据制作的算法和原理,可以阅读几位大佬在Scientific Data上发的文章。

小编也已经在文末给大家准备好了,如果不想自己去查,那就直接在文末获取吧!
数据获取方式
链接:
-
数据链接:https://pan.baidu.com/s/1xjUymD01aYhi_MaFUmRdAA?pwd=u5ji 提取码:u5ji
论文链接:https://pan.baidu.com/s/1quHO2L6mJo6FcL8_twSq3Q?pwd=tg3c 提取码:tg3c
内容创作不易,期待大家点赞、转发支持一下,我们是梧桐GIS,谢谢大家的关注!
再次声明,我们只是优质数据的分享者,版权归原作者所有!!各位小伙伴在使用数据时,记得加上数据的引用:
张立贤, 任浙豪, 陈斌, 宫鹏, 付昊桓, 徐冰. (2021). 中国长时间序列逐年人造夜间灯光数据集(1984-2020). 国家青藏高原数据中心.
https://doi.org/10.11888/Socioeco.tpdc.271202. https://cstr.cn/18406.11.Socioeco.tpdc.271202.

这篇关于GIS数据—1984-2020中国1km人造夜间灯光观测数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








