本文主要是介绍[机器学习-04] Scikit-Learn机器学习工具包进阶指南:集群化与校准功能实战【2024最新】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

🎩 欢迎来到技术探索的奇幻世界👨💻
📜 个人主页:@一伦明悦-CSDN博客
✍🏻 作者简介: C++软件开发、Python机器学习爱好者
🗣️ 互动与支持:💬评论 👍🏻点赞 📂收藏 👀关注+
如果文章有所帮助,欢迎留下您宝贵的评论,点赞加收藏支持我,点击关注,一起进步!
目录
前言
正文
01-集群化和校准功能简介
02-谱协聚类算法
03-光谱集群算法
04-分类器校准的比较
05-概率校准曲线
06-分类器的概率校准
07-三分类的概率校准
总结
前言
Scikit-Learn 是一个流行的 Python 机器学习工具包,提供了丰富的功能来实现各种机器学习任务,包括集群化(clustering)和校准(calibration)功能。
集群化(Clustering):
集群化是一种无监督学习任务,旨在将数据集中的样本划分为不同的组(或集群),以便相似的样本被分配到同一个集群中。Scikit-Learn 提供了多种常用的集群化算法,包括 K-Means、DBSCAN、层次聚类等。这些算法可以根据不同的数据特点和需求来选择合适的算法进行集群化分析。集群化可以用于数据压缩、异常检测、数据分割等应用场景。
校准(Calibration):
校准是指调整模型的预测概率,使其更好地反映实际情况。在很多机器学习模型中,尤其是概率模型,预测的概率并不总是准确的。例如,一个模型预测某个事件发生的概率为 0.7,但实际上这个事件发生的概率可能更接近于 0.8。校准的目的就是通过一些技术手段来调整模型的预测概率,使其更加准确。Scikit-Learn 提供了 CalibratedClassifierCV 类来实现模型的校准,该类可以用于调整分类器的输出概率,使其更加准确地反映真实概率。
正文
01-集群化和校准功能简介
对于集群化和校准功能,可以进行以下详细分析:
集群化的应用:
a、数据压缩与维度约简:通过将数据点聚合到代表性的集群中,可以减少数据的维度,从而实现数据的压缩和维度约简。
b、异常检测:集群化可以帮助识别数据中的异常点,因为异常点通常不会属于任何一个集群,或者会形成一个单独的集群。
c、数据分割与聚类:将数据集分割为不同的组可以帮助进行更细粒度的数据分析和理解,例如市场细分、用户分群等。
下面给出了三种具体代码案例进行分析集群化应用过程:
(1)数据压缩与维度约简(Clustering for Data Compression and Dimensionality Reduction):
代码部分:这段代码使用了KMeans算法对生成的虚拟数据集进行聚类,然后使用PCA对数据进行降维到2维。
解释:通过聚类算法将数据点分组为不同的簇,然后通过PCA将数据降维到二维,以便于可视化展示数据的聚类情况。在图中,每个点的颜色表示其所属的聚类簇,红色的十字表示每个聚类簇的中心。
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.datasets import make_blobs, make_moons
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus'] = False
# 创建数据集
X, _ = make_blobs(n_samples=1000, centers=10, n_features=20, random_state=42)# 使用 KMeans 算法进行聚类
kmeans = KMeans(n_clusters=5)
kmeans.fit(X)# 获取聚类中心
cluster_centers = kmeans.cluster_centers_# 使用 PCA 进行数据维度约简
pca = PCA(n_components=2)
X_reduced = pca.fit_transform(X)# 使用 KMeans 聚类结果进行可视化
plt.scatter(X_reduced[:, 0], X_reduced[:, 1], c=kmeans.labels_, cmap='viridis')
plt.scatter(cluster_centers[:, 0], cluster_centers[:, 1], marker='x', color='red')
plt.title('用于数据压缩和降维的聚类')
plt.savefig("../1.png", dpi=500)
plt.show()运行结果分别如下图所示

异常检测(Clustering for Anomaly Detection):
代码部分:这段代码使用了DBSCAN算法对生成的月亮形状数据进行聚类。
解释:DBSCAN是一种基于密度的聚类算法,它可以发现任意形状的聚类。在图中,不同颜色的点表示被DBSCAN聚类的不同群集,而未分配到任何群集的点可能被视为异常值。
from sklearn.cluster import DBSCAN# 创建数据集
X, _ = make_moons(n_samples=100, noise=0.1, random_state=42)# 使用 DBSCAN 算法进行聚类
dbscan = DBSCAN(eps=0.2)
dbscan.fit(X)# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=dbscan.labels_, cmap='viridis')
plt.title('用于异常检测的聚类')
plt.savefig("../2.png", dpi=500)
plt.show()运行结果分别如下图所示

数据分割与聚类(Clustering for Data Segmentation):
代码部分:这段代码使用了凝聚层次聚类算法对月亮形状数据进行聚类。
解释:凝聚层次聚类算法将数据点逐步合并为越来越大的聚类簇。在图中,不同颜色的点表示不同的聚类簇,通过这种方法可以对数据进行分割并识别出不同的类别。
from sklearn.cluster import AgglomerativeClustering# 创建数据集
X, _ = make_moons(n_samples=100, noise=0.1, random_state=42)# 使用凝聚层次聚类算法进行聚类
agg_clustering = AgglomerativeClustering(n_clusters=2)
agg_clustering.fit(X)# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=agg_clustering.labels_, cmap='viridis')
plt.title('用于数据分段的聚类')
plt.savefig("../3.png", dpi=500)
plt.show()运行结果分别如下图所示

校准的意义与方法:
a、概率模型的输出校准:在一些场景中,模型的预测概率需要准确地反映实际概率,而不仅仅是相对大小的关系。这时就需要对模型的输出概率进行校准。
b、校准方法:Scikit-Learn 提供的 CalibratedClassifierCV 类使用了 Platt 校准和 Isotonic 校准两种方法。Platt 校准通过拟合一个 logistic 回归模型来校准概率输出,而 Isotonic 校准则通过拟合一个非递减的线性函数来校准概率输出。选择合适的校准方法取决于数据的特性以及模型的性能。
下面给出具体代码分析概率模型的输出校准应用分析:
代码展示了使用CalibratedClassifierCV进行概率校准,并对概率校准前后的效果进行可视化比较。代码解释:
首先,加载了鸢尾花数据集,并将其划分为训练集和测试集。
然后,使用随机森林分类器(RandomForestClassifier)对训练集进行训练。
接着,通过CalibratedClassifierCV对已训练的随机森林分类器进行概率校准,采用了method='sigmoid'表示采用逻辑回归进行校准。
训练校准器后,获取测试集上的校准后的概率预测。
from sklearn.calibration import CalibratedClassifierCV
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus'] = False
# 加载鸢尾花数据集
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练一个随机森林分类器
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
rf_classifier.fit(X_train, y_train)# 使用 CalibratedClassifierCV 进行概率校准
calibrated_classifier = CalibratedClassifierCV(rf_classifier, method='sigmoid', cv='prefit')
calibrated_classifier.fit(X_train, y_train)# 获取校准后的概率预测
calibrated_probs = calibrated_classifier.predict_proba(X_test)# 可视化概率校准前后的效果
plt.hist(calibrated_probs[:, 1], bins=20, alpha=0.5, label='校准', color='blue')
plt.hist(rf_classifier.predict_proba(X_test)[:, 1], bins=20, alpha=0.5, label='未校准', color='red')
plt.xlabel('预测概率')
plt.ylabel('频率')
plt.legend(loc='upper center')
plt.title('概率校准比较')
plt.savefig("../4.png", dpi=500)
plt.show()运行结果如下图所示,图像分析:可视化图像通过直方图展示了概率校准前后的效果。蓝色的直方图表示经过校准后的概率分布,红色的直方图表示未经校准的概率分布。横坐标是预测概率的值,纵坐标是对应概率值的频数。通过对比可以看出,经过概率校准后,概率分布更加平滑、更接近理想的形式,与原始未校准的概率分布相比,更符合实际情况。这表明概率校准可以提高分类器的性能,使其更准确地反映出样本的真实概率分布,有助于提高分类器在实际应用中的可靠性。

02-谱协聚类算法
SpectralCoclustering(谱共聚类)是一种用于数据聚类的算法,它能够同时对数据的行和列进行聚类。这个算法利用了数据的谱特性,通过对数据的行和列同时进行聚类,可以发现数据中潜在的双向聚类结构,即同时考虑了样本和特征之间的关系。
具体来说,SpectralCoclustering 算法首先将数据转换成图的形式,其中节点表示数据的行或列,边表示行或列之间的关系。然后,通过对图进行谱分解,得到数据的特征向量,进而进行聚类分析。这种双向聚类的方法能够更好地发现数据中的局部模式和结构,对于一些复杂的数据集具有较好的效果。
总的来说,SpectralCoclustering 算法是一种基于谱分析的双向聚类方法,适用于发现数据集中的双向聚类结构,并在某些情况下比传统的单向聚类方法效果更好。
下面给出具体代码进行分析该算法应用:代码生成了一个二维矩阵的热图,并对热图进行了简单的美化处理。代码解释:
a、首先,使用make_biclusters函数生成了一个二维矩阵的数据集,其中包含了5个双聚类(biclusters)。
b、使用了SpectralCoclustering算法对数据进行双聚类分析。
c、导入了consensus_score用于评估聚类的一致性。
d、设置了中文字体以解决中文显示乱码的问题,并绘制了热图。
import numpy as np
from matplotlib import pyplot as pltfrom sklearn.datasets import make_biclusters
from sklearn.cluster import SpectralCoclustering
from sklearn.metrics import consensus_scoreplt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示乱码问题
plt.rcParams['axes.unicode_minus'] = False # 生成数据集
data, rows, columns = make_biclusters(shape=(300, 300), n_clusters=5, noise=5,shuffle=False, random_state=0)# 绘制热图
plt.matshow(data, cmap=plt.cm.Purples, aspect='auto')
plt.title("原始数据集", fontsize=16) # 修改标题并增加字体大小
plt.colorbar(label='数据值') # 添加颜色栏,并设置标签
plt.grid(False) # 关闭网格线
plt.savefig("../1.png", dpi=500)
plt.show()示例运行结果如下图所示:
a、生成的图像是一个热图,用颜色表示数据的数值大小。浅色代表较高的数值,深色代表较低的数值。
b、通过修改后的样式,热图更加清晰、美观。浅色和深色的对比更加明显,标题、标签和颜色栏的添加增强了图像的可读性。
c、这样的热图可以帮助我们观察数据的分布情况,尤其是在双聚类分析中,可以清晰地展示数据的聚类结构。

下面这部分代码是在上段代码段的基础上,对生成的数据集进行了打乱处理,并绘制了新的热图。对代码解释如下:
使用随机数生成器np.random.RandomState对数据集进行行和列的打乱处理。
打乱后的数据集通过plt.matshow绘制成热图。
与之前类似,添加了标题、标签和颜色栏等样式元素。
# shuffle clusters
rng = np.random.RandomState(0)
row_idx = rng.permutation(data.shape[0])
col_idx = rng.permutation(data.shape[1])
data = data[row_idx][:, col_idx]plt.matshow(data, cmap=plt.cm.Purples, aspect='auto')
plt.title("随机排序的数据集", fontsize=13) # 修改标题并增加字体大小
plt.colorbar(label='数据值') # 添加颜色栏,并设置标签
plt.grid(False) # 关闭网格线
plt.savefig("../2.png", dpi=500)
plt.show()示例运行结果如下图所示:
生成的图像是一个经过打乱处理后的热图,同样用颜色表示数据的数值大小。
与之前的热图相比,数据的排列顺序被打乱,但颜色映射和图像样式保持一致。
打乱后的热图依然可以帮助我们观察数据的分布情况,但行和列的关联关系被破坏,这可能会影响双聚类分析的结果。

下面代码是在上述代码的基础上进行完善之后的示例,代码解释如下:
使用SpectralCoclustering算法对数据进行双聚类分析,指定了n_clusters=5表示要生成的双聚类数量。
计算了双聚类的一致性评分,评估了双聚类的稳定性和一致性。
将数据按照行标签和列标签的排序重新排列,以便展示双聚类结构。
使用plt.matshow绘制了双聚类分析后的数据集热图。
model = SpectralCoclustering(n_clusters=5, random_state=0)
model.fit(data)
score = consensus_score(model.biclusters_,(rows[:, row_idx], columns[:, col_idx]))print("consensus score: {:.3f}".format(score))fit_data = data[np.argsort(model.row_labels_)]
fit_data = fit_data[:, np.argsort(model.column_labels_)]plt.matshow(fit_data, cmap=plt.cm.Purples, aspect='auto')
plt.title("双聚类分析后的数据集", fontsize=13) # 修改标题并增加字体大小
plt.colorbar(label='数据值') # 添加颜色栏,并设置标签
plt.grid(False) # 关闭网格线
plt.savefig("../3.png", dpi=500)
plt.show()# 输出结果
# consensus score: 1.000运行结果如下图所示:
生成的图像是经过双聚类分析后的热图,展示了数据集中的双聚类结构。
每个双聚类在热图中呈现出不同的颜色和形状。
通过双聚类分析,我们可以观察到数据集中的潜在模式和结构,以及行和列之间的相关性。

03-光谱集群算法
光谱集群算法(Spectral Clustering Algorithm)是一种基于图论的聚类算法,它利用数据集的特征空间的图表示进行聚类。该算法的主要思想是将数据集转换为图的形式,然后在图上进行聚类,最终将数据集分为不同的类别。
具体步骤包括:
构建相似度图:首先,根据数据集中样本之间的相似度,构建一个相似度矩阵或者相似度图。通常使用高斯核函数或者K近邻法计算相似度。
降维:对相似度矩阵进行降维,将其转换为低维空间。通常使用特征值分解或者奇异值分解等方法。
聚类:在降维后的空间中,利用传统的聚类算法(如K均值)对数据进行聚类。也可以在降维后的空间中使用谱聚类算法进行聚类。
后处理:根据需要,进行后处理步骤,如簇合并或者噪声过滤等。
光谱集群算法在图论和谱理论的基础上,通过将数据映射到低维度特征空间来实现聚类,适用于各种类型的数据集,尤其在数据集非凸形状或者存在噪声的情况下表现较好。
下面给出具体代码示例分析使用过程,此示例演示如何使用光谱集群算法生成棋盘数据集和集群。
数据由make_checkerboard函数生成,然后进行洗牌,并传递给光谱集群算法。对打乱的矩阵的行和列进行重新排列,以显示算法找到集群。
下方代码解释:
使用 make_checkerboard 函数生成了一个具有棋盘状结构的数据集,其中包含了指定数量的簇(clusters),并加入了一定程度的噪声。n_clusters 参数指定了生成的簇的数量,这里设定为 (4, 3),表示 4 行 3 列的簇。
调用 SpectralBiclustering 算法对生成的数据集进行双聚类分析。参数 n_clusters=5 表示要生成的双聚类的数量为 5。
使用 consensus_score 函数计算了双聚类的一致性评分,用来评估双聚类的稳定性和一致性。
对数据进行重新排序,使得行标签和列标签按照双聚类分析后的结果重新排列,以便展示双聚类结构。
使用 plt.matshow 函数绘制了经过双聚类分析后的数据集的热图,以展示数据集中的双聚类结构。
import numpy as np
from matplotlib import pyplot as pltfrom sklearn.datasets import make_checkerboard
from sklearn.cluster import SpectralBiclustering
from sklearn.metrics import consensus_score
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus'] = False n_clusters = (4, 3)
data, rows, columns = make_checkerboard(shape=(300, 300), n_clusters=n_clusters, noise=10,shuffle=False, random_state=0)plt.matshow(data, cmap=plt.cm.Purples,aspect='auto')
plt.title("原始数据集", fontsize=13) # 修改标题并增加字体大小
plt.colorbar(label='数据值') # 添加颜色栏,并设置标签
plt.grid(False) # 关闭网格线
plt.savefig("../3.png", dpi=500)
plt.show()示例运行结果如下图所示:生成的图像是经过双聚类分析后的热图,展示了数据集中的双聚类结构。每个双聚类在热图中呈现出不同的颜色和形状,反映了它们在数据集中的分布情况。通过观察热图,可以发现数据集中的潜在模式和结构,以及行和列之间的相关性。

下面这部分代码在展示双聚类结构之前,通过随机排序来观察数据在无序状态下的分布情况。这有助于比较双聚类分析前后数据的结构差异。代码解释如下:
使用 numpy 中的 random.RandomState 方法创建了一个随机数生成器 rng,并设置了种子为 0。
使用 rng.permutation 方法对数据集的行和列索引进行随机排列,以实现数据的随机排序。data.shape[0] 表示数据集的行数,data.shape[1] 表示数据集的列数。
根据随机排列后的行索引和列索引,重新排列了数据集 data。
使用 plt.matshow 函数绘制了经过随机排序后的数据集的热图,依然使用了紫色系的颜色映射,并设置了图像的宽高比自动调整。
# shuffle clusters
rng = np.random.RandomState(0)
row_idx = rng.permutation(data.shape[0])
col_idx = rng.permutation(data.shape[1])
data = data[row_idx][:, col_idx]plt.matshow(data, cmap=plt.cm.Purples, aspect='auto')
plt.title("随机排序的数据集", fontsize=13) # 修改标题并增加字体大小
plt.colorbar(label='数据值') # 添加颜色栏,并设置标签
plt.grid(False) # 关闭网格线
plt.savefig("../2.png", dpi=500)
plt.show()示例运行结果如下图所示:生成的图像展示了经过随机排序后的数据集的热图。与原始数据集相比,随机排序后的数据集失去了原始的结构模式,呈现出更加随机和无序的分布。颜色的变化仍然反映了数据值的大小,但是由于数据被重新排列,不再体现出原始数据集中的特定模式或结构。

下面这部分代码是在进行双聚类分析后的处理步骤,代码解释如下:
创建了 SpectralBiclustering 模型,指定了双聚类的数量为 n_clusters,使用对数变换的方法(method=‘log’)进行双聚类分析,并设置了随机种子为 0。
使用 model.fit(data) 对数据集进行双聚类分析,即将数据集拟合到双聚类模型中。
使用 consensus_score 函数计算了双聚类的一致性评分,评估了双聚类的稳定性和一致性。这个评分表示了双聚类结果在不同随机初始化下的一致性程度,得分越高表示双聚类结果越稳定。
对数据进行了重新排序,使得行标签和列标签按照双聚类分析后的结果重新排列,以便展示双聚类结构。这里使用了模型对象的 row_labels_ 和 column_labels_ 属性来对数据进行重新排序。
使用 plt.matshow 函数绘制了经过双聚类分析并重新排列后的数据集的热图,依然使用了紫色系的颜色映射,并设置了图像的宽高比自动调整。
model = SpectralBiclustering(n_clusters=n_clusters, method='log',random_state=0)
model.fit(data)
score = consensus_score(model.biclusters_,(rows[:, row_idx], columns[:, col_idx]))print("consensus score: {:.1f}".format(score))fit_data = data[np.argsort(model.row_labels_)]
fit_data = fit_data[:, np.argsort(model.column_labels_)]
plt.matshow(fit_data, cmap=plt.cm.Purples, aspect='auto')
plt.title("双聚后;重新排列以显示双星团", fontsize=13) # 修改标题并增加字体大小
plt.colorbar(label='数据值') # 添加颜色栏,并设置标签
plt.grid(False) # 关闭网格线
plt.savefig("../3.png", dpi=500)
plt.show()
示例运行结果如下图所示:生成的图像展示了经过双聚类分析并重新排列后的数据集的热图。相比于随机排序后的数据集,这张图反映了双聚类分析所揭示的数据结构。不同颜色和形状的区块代表了不同的双聚类,这些双聚类反映了数据集中的潜在模式和结构。通过观察这张图,可以更清晰地理解数据集中的双聚类结构及其对应的行列分布情况。

下面这段代码生成了一个展示双聚类结果的棋盘结构图像。代码解释如下:
使用 plt.matshow 函数绘制了一个矩阵,矩阵的行和列分别由模型的行标签和列标签组成。np.outer(np.sort(model.row_labels_) + 1, np.sort(model.column_labels_) + 1) 表示了一个外积矩阵,其中模型的行标签和列标签都经过排序,并且加上了偏移量1以避免0值。这样的外积矩阵可以反映出双聚类的结构。
plt.matshow(np.outer(np.sort(model.row_labels_) + 1,np.sort(model.column_labels_) + 1),cmap=plt.cm.Purples, aspect='auto')plt.title("重新排列数据的棋盘结构", fontsize=13) # 修改标题并增加字体大小
plt.colorbar(label='数据值') # 添加颜色栏,并设置标签
plt.grid(False) # 关闭网格线
plt.savefig("../4.png", dpi=500)
plt.show()
示例运行结果如下图所示:生成的图像展示了双聚类结果的棋盘结构,每个小方块代表了一个双聚类。棋盘结构的出现说明了数据集中存在着明显的双聚类模式,即某些行和列被分成了几个连续的块。这种结构的出现表明了数据集中存在着一些潜在的模式和关联性,而双聚类分析则有效地将这些模式和关联性捕捉出来。

04-分类器校准的比较
分类器的校准是指分类器的输出与样本的真实概率分布之间的一致性程度。一个经过良好校准的分类器是概率分类器,其输出可以被解释为置信度或概率。
考虑一个经过良好校准的二分类器,对于给定的样本,如果它输出的 predict_proba 值接近0.8,那么可以理解为该分类器对该样本属于正类的置信度约为80%。这表示该分类器对样本属于正类的概率估计比较可靠。
分类器校准的重要性在于它直接影响到分类器的应用场景。一些场景需要对分类器输出的概率进行准确的解释和利用,比如医疗诊断、金融风险评估等。在这些场景下,一个准确校准的分类器可以提供更可靠的概率估计,帮助决策者做出更准确的决策。
分类器校准的方法包括:Platt缩放、等渗压缩、直方图校准等。Platt缩放是一种常用的校准方法,它通过对分类器的输出进行逻辑回归拟合,将原始输出映射到概率空间。等渗压缩和直方图校准则是通过对样本的概率分布进行调整,使分类器的输出与样本真实概率分布更加一致。
综上所述,一个经过良好校准的分类器可以提供可靠的概率估计,帮助用户更准确地理解分类器的输出,并在需要时做出更可靠的决策。
下面给出具体代码示例进行分析应用过程,这段代码的目的是绘制分类器的校准曲线,它显示了分类器预测的概率与实际观察到的概率之间的关系。代码解释如下:
生成了一个合成数据集,包含特征和标签,用于分类器的训练和测试。
将数据集分成训练集和测试集,其中训练集用于拟合分类器,测试集用于评估分类器的性能。
实例化了四个不同的分类器:逻辑回归(LogisticRegression)、朴素贝叶斯(GaussianNB)、支持向量机(LinearSVC)和随机森林(RandomForestClassifier)。
使用训练集拟合每个分类器,并使用测试集获取概率估计。
绘制了校准曲线(reliability curve)和概率分布直方图(histogram),以便直观地比较每个分类器的校准效果和概率分布。
import numpy as np
np.random.seed(0)import matplotlib.pyplot as pltfrom sklearn import datasets
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import LinearSVC
from sklearn.calibration import calibration_curve
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus'] = False X, y = datasets.make_classification(n_samples=100000, n_features=20,n_informative=2, n_redundant=2)train_samples = 100 # Samples used for training the modelsX_train = X[:train_samples]
X_test = X[train_samples:]
y_train = y[:train_samples]
y_test = y[train_samples:]# Create classifiers
lr = LogisticRegression()
gnb = GaussianNB()
svc = LinearSVC(C=1.0)
rfc = RandomForestClassifier()# #############################################################################
# Plot calibration plotsplt.figure(figsize=(10, 10))
ax1 = plt.subplot2grid((3, 1), (0, 0), rowspan=2)
ax2 = plt.subplot2grid((3, 1), (2, 0))ax1.plot([0, 1], [0, 1], "k:", label="完美校准", color='gray', linestyle='--')
colors = ['blue', 'green', 'purple', 'red']for clf, name, color in zip([lr, gnb, svc, rfc], ['逻辑回归', '朴素贝叶斯', '支持向量机', '随机森林'], colors):clf.fit(X_train, y_train)if hasattr(clf, "predict_proba"):prob_pos = clf.predict_proba(X_test)[:, 1]else: # use decision functionprob_pos = clf.decision_function(X_test)prob_pos = \(prob_pos - prob_pos.min()) / (prob_pos.max() - prob_pos.min())fraction_of_positives, mean_predicted_value = \calibration_curve(y_test, prob_pos, n_bins=10)ax1.plot(mean_predicted_value, fraction_of_positives, "s-",label="%s" % (name, ), color=color)ax2.hist(prob_pos, range=(0, 1), bins=10, label=name,histtype="step", lw=2, color=color)ax1.set_ylabel("阳性分数")
ax1.set_ylim([-0.05, 1.05])
ax1.legend(loc="lower right")
ax1.set_title('校准图(可靠性曲线)', fontsize=15)ax2.set_xlabel("平均预测值")
ax2.set_ylabel("计数")
ax2.legend(loc="upper center", ncol=2)plt.tight_layout()
plt.savefig("../3.png", dpi=500)
plt.show()示例运行结果如下图所示:生成的图像展示了四个分类器的校准曲线和概率分布直方图。在校准曲线中,理想状态下的完美校准曲线以虚线表示,而实际的分类器校准曲线则以实线和标记的形式呈现。校准曲线越接近理想状态的虚线,表示分类器的校准效果越好。直方图显示了每个分类器输出的概率分布情况,可以直观地比较它们的校准效果。

05-概率校准曲线
在进行分类时,不仅要预测类标签,还要预测相关概率。这种概率给了预测某种程度的信心。此示例演示了如何显示预测概率的校准效果,以及如何校准未校准的分类器。
案例是在一个二分类的人工数据集上进行的,该数据集包含100000个样本(其中1000个用于模型拟合),共20个特征。在这20个特性中,只有2个是信息丰富的,10个是冗余的。第一幅图显示了通过Logistic回归、高斯朴素贝叶斯、 isotonic校准的高斯朴素贝叶斯和sigmoid校准的高斯朴素贝叶斯得到的估计概率。校准性能用Brier评分进行评估,在图例中有报道(越小越好)。这里可以看到,Logistic回归是很好的校准,而原始高斯朴素贝叶斯表现很差。这是因为冗余特征违背了特征无关的假设,导致分类器过于自信,这可以通过transposed-sigmoid曲线表明。
用 isotonic校准的高斯朴素贝叶斯的概率校准可以解决这一问题,这也可以从对角校准曲线可以看出这一点。sigmoid也略微提高了Brier评分,尽管不如非参数的isotonic回归那么强。这可以归因于这样一个事实:我们有大量的校准数据,以至于可以利用非参数模型的更大的灵活性。
第二个图显示了线性支持向量分类器(LinearSVC)的校准曲线。LinearSVC显示了与高斯朴素贝叶斯相反的行为:校准曲线有一条sigmoid曲线,这是欠自信分类器的典型特征。在LinearSVC的情况下,这是由hinge损失的边缘特性引起的,这使得模型关注于接近决策边界的硬样本(支持向量)。
这两种校准方法都可以解决这个问题,并得到几乎相同的结果。这表明,Sigmoid校准可以处理基本分类器的校准曲线为Sigmoid的情况(例如,LinearSVC),而不能处理transposed-sigmoid(例如,高斯朴素贝叶斯)的情况。
下面是对代码的具体解释过程:
这段代码是一个例子,用于比较不同分类器在进行概率校准(probability calibration)后的效果。概率校准是指对分类器输出的概率进行修正,使得概率值更加准确地反映样本真实的类别概率。
首先,生成了一个具有20个特征的分类任务的数据集,其中只有2个特征是有信息量的,其余特征是冗余的。然后,将数据集分成训练集和测试集,其中测试集占总数据集的99%。
接下来的函数 plot_calibration_curve 是用来绘制概率校准曲线的。它接受一个分类器 est、该分类器的名称 name、以及图形索引 fig_index。在函数内部,将分类器分别进行了三种方式的概率校准:无校准、等渗校准(isotonic calibration)、Sigmoid 校准。然后分别计算并打印了模型的 Brier 评分、精确度、召回率和 F1 分数。接着,绘制了两个子图:上面的子图是概率校准曲线,下面的子图是各分类器输出概率的直方图。
最后,通过调用 plot_calibration_curve 函数,分别对高斯朴素贝叶斯分类器和线性支持向量机分类器进行了概率校准曲线的绘制,并保存为相应的图片文件。
import matplotlib.pyplot as pltfrom sklearn import datasets
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import LinearSVC
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import (brier_score_loss, precision_score, recall_score,f1_score)
from sklearn.calibration import CalibratedClassifierCV, calibration_curve
from sklearn.model_selection import train_test_split# Create dataset of classification task with many redundant and few
# informative features
X, y = datasets.make_classification(n_samples=100000, n_features=20,n_informative=2, n_redundant=10,random_state=42)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.99,random_state=42)colors = ['blue', 'green', 'purple', 'red']def plot_calibration_curve(est, name, fig_index):"""Plot calibration curve for est w/o and with calibration. """# Calibrated with isotonic calibrationisotonic = CalibratedClassifierCV(est, cv=2, method='isotonic')# Calibrated with sigmoid calibrationsigmoid = CalibratedClassifierCV(est, cv=2, method='sigmoid')# Logistic regression with no calibration as baselinelr = LogisticRegression(C=1.)fig = plt.figure(fig_index, figsize=(10, 10))ax1 = plt.subplot2grid((3, 1), (0, 0), rowspan=2)ax2 = plt.subplot2grid((3, 1), (2, 0))ax1.plot([0, 1], [0, 1], "k:", label="Perfectly calibrated")for idx, (clf, name) in enumerate([(lr, 'Logistic'),(est, name),(isotonic, name + ' + Isotonic'),(sigmoid, name + ' + Sigmoid')]):clf.fit(X_train, y_train)y_pred = clf.predict(X_test)if hasattr(clf, "predict_proba"):prob_pos = clf.predict_proba(X_test)[:, 1]else: # use decision functionprob_pos = clf.decision_function(X_test)prob_pos = \(prob_pos - prob_pos.min()) / (prob_pos.max() - prob_pos.min())clf_score = brier_score_loss(y_test, prob_pos, pos_label=y.max())print("%s:" % name)print("\tBrier: %1.3f" % (clf_score))print("\tPrecision: %1.3f" % precision_score(y_test, y_pred))print("\tRecall: %1.3f" % recall_score(y_test, y_pred))print("\tF1: %1.3f\n" % f1_score(y_test, y_pred))fraction_of_positives, mean_predicted_value = \calibration_curve(y_test, prob_pos, n_bins=10)ax1.plot(mean_predicted_value, fraction_of_positives, "s-",color=colors[idx], label="%s (%1.3f)" % (name, clf_score))ax2.hist(prob_pos, range=(0, 1), bins=10, label=name,color=colors[idx], histtype="step", lw=2)ax1.set_ylabel("Fraction of positives")ax1.set_ylim([-0.05, 1.05])ax1.legend(loc="lower right")ax1.set_title('Calibration plots (reliability curve)')ax2.set_xlabel("Mean predicted value")ax2.set_ylabel("Count")ax2.legend(loc="upper center", ncol=2)plt.tight_layout()# Plot calibration curve for Gaussian Naive Bayes
plot_calibration_curve(GaussianNB(), "Naive Bayes", 1)
plt.savefig("../5.png", dpi=500)
# Plot calibration curve for Linear SVC
plot_calibration_curve(LinearSVC(max_iter=10000), "SVC", 2)
plt.savefig("../4.png", dpi=500)
plt.show()示例运行结果如下图所示:生成的图像展示了不同分类器进行概率校准后的效果。上面的子图显示了校准曲线,其中横轴是分类器输出的平均预测概率,纵轴是实际为正类别的样本在这个概率范围内的比例。理想状态下,曲线应该接近对角线(完美校准)。下面的子图显示了各分类器输出概率的直方图,可以观察到不同分类器输出概率的分布情况。


06-分类器的概率校准
概率校准是指调整分类器输出的概率值,使其更好地反映样本真实的类别概率。在实际分类问题中,分类器输出的概率并不总是准确的概率值,可能存在偏差或不良的概率估计。概率校准的目的是通过一些技术手段来修正这些概率,以提高分类器的性能和可靠性。
在概率校准中,主要有两种常用的方法:等渗校准(isotonic calibration)和 Sigmoid 校准(sigmoid calibration)。
等渗校准(Isotonic Calibration):
这种方法通过对分类器的输出概率进行非参数估计,从而消除概率的偏差。它基于等渗回归(Isotonic Regression)的思想,将分类器输出的概率值映射到一个更加平滑的曲线上,以提高概率估计的准确性。
等渗校准适用于任何分类器,但可能会因为需要存储训练数据而消耗更多的内存和计算资源。
Sigmoid 校准:
这种方法使用逻辑函数(Sigmoid function)对分类器输出的概率进行映射,将原始的概率转换成更加平滑且具有良好性质的概率值。通常采用的是 Platt 校准或者经验校准方法。
Sigmoid 校准相对来说更简单,计算速度也更快,但在某些情况下可能不如等渗校准效果好。
在代码中,通过 CalibratedClassifierCV 类实现了对分类器进行概率校准。其中,method='isotonic' 表示采用等渗校准,method='sigmoid' 表示采用 Sigmoid 校准。然后通过拟合不同校准方式的分类器,并计算其在测试集上的性能指标(如 Brier 评分、精确度、召回率和 F1 分数),来比较不同校准方式的效果。
总的来说,概率校准是一种提高分类器性能的重要技术,在需要对分类器输出的概率进行精细控制和调整时特别有用。
下面给出具体代码分析分类器的概率校准应用过程:这段代码首先生成了三个类别的数据集,每个类别均服从高斯分布。其中,第二个类别中的样本一半为正例,一半为反例,即类别标签为1和0的样本各占一半。然后,使用加权的高斯朴素贝叶斯分类器(Gaussian Naive-Bayes)对数据进行建模,分别进行了三种不同的概率校准方法:不校准、等渗校准和Sigmoid校准。
接着,代码计算了Brier分数,用以评估不同校准方法的效果。Brier分数越低代表模型的预测越准确,因此可通过比较这些分数来评估不同校准方法的性能。
import numpy as np
import matplotlib.pyplot as pltfrom sklearn.datasets import make_blobs
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import brier_score_loss
from sklearn.calibration import CalibratedClassifierCV
from sklearn.model_selection import train_test_split
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus'] = False
n_samples = 50000
n_bins = 3 # use 3 bins for calibration_curve as we have 3 clusters here# Generate 3 blobs with 2 classes where the second blob contains
# half positive samples and half negative samples. Probability in this
# blob is therefore 0.5.
centers = [(-5, -5), (0, 0), (5, 5)]
X, y = make_blobs(n_samples=n_samples, centers=centers, shuffle=False,random_state=42)y[:n_samples // 2] = 0
y[n_samples // 2:] = 1
sample_weight = np.random.RandomState(42).rand(y.shape[0])# split train, test for calibration
X_train, X_test, y_train, y_test, sw_train, sw_test = \train_test_split(X, y, sample_weight, test_size=0.9, random_state=42)# Gaussian Naive-Bayes with no calibration
clf = GaussianNB()
clf.fit(X_train, y_train) # GaussianNB itself does not support sample-weights
prob_pos_clf = clf.predict_proba(X_test)[:, 1]# Gaussian Naive-Bayes with isotonic calibration
clf_isotonic = CalibratedClassifierCV(clf, cv=2, method='isotonic')
clf_isotonic.fit(X_train, y_train, sample_weight=sw_train)
prob_pos_isotonic = clf_isotonic.predict_proba(X_test)[:, 1]# Gaussian Naive-Bayes with sigmoid calibration
clf_sigmoid = CalibratedClassifierCV(clf, cv=2, method='sigmoid')
clf_sigmoid.fit(X_train, y_train, sample_weight=sw_train)
prob_pos_sigmoid = clf_sigmoid.predict_proba(X_test)[:, 1]print("Brier 分数:(越小越好)")clf_score = brier_score_loss(y_test, prob_pos_clf, sample_weight=sw_test)
print("不校准: %1.3f" % clf_score)clf_isotonic_score = brier_score_loss(y_test, prob_pos_isotonic,sample_weight=sw_test)
print("具有等渗校准: %1.3f" % clf_isotonic_score)clf_sigmoid_score = brier_score_loss(y_test, prob_pos_sigmoid,sample_weight=sw_test)
print("具有Sigmoid 校准: %1.3f" % clf_sigmoid_score)# #############################################################################
# Plot the data and the predicted probabilities
plt.figure()
y_unique = np.unique(y)
colors = ['blue', 'green', 'purple', 'red'] # 修改颜色
for this_y, color in zip(y_unique, colors):this_X = X_train[y_train == this_y]this_sw = sw_train[y_train == this_y]plt.scatter(this_X[:, 0], this_X[:, 1], s=this_sw * 50,c=color,alpha=0.5, edgecolor='k',label="Class %s" % this_y)
plt.legend(loc="best")
plt.savefig("../2.png", dpi=500)
plt.title("数据")plt.figure()
order = np.lexsort((prob_pos_clf, ))
plt.plot(prob_pos_clf[order], color='red', label='不校准 (%1.3f)' % clf_score)
plt.plot(prob_pos_isotonic[order], color='green', linewidth=3,label='等渗校准 (%1.3f)' % clf_isotonic_score)
plt.plot(prob_pos_sigmoid[order], color='blue', linewidth=3,label='Sigmoid 校准 (%1.3f)' % clf_sigmoid_score)
plt.plot(np.linspace(0, y_test.size, 51)[1::2],y_test[order].reshape(25, -1).mean(1),'k', linewidth=3, label=r'实证')
plt.ylim([-0.05, 1.05])
plt.xlabel("根据预测概率排序的实例 ""(未校准的 GNB)")
plt.ylabel("P(y=1)")
plt.legend(loc="upper left")
plt.title("高斯朴素贝叶斯概率")
plt.savefig("../1.png", dpi=500)
plt.show()# 输出结果
Brier 分数:(越小越好)
不校准: 0.104
具有等渗校准: 0.084
具有Sigmoid 校准: 0.109示例运行结果如下图所示: 第一张图展示了生成的数据,每个类别用不同的颜色表示,样本点的大小表示其对应的权重。第二张图则展示了排序后的预测概率以及实际的标签情况,并分别标注了不同校准方法的Brier分数。


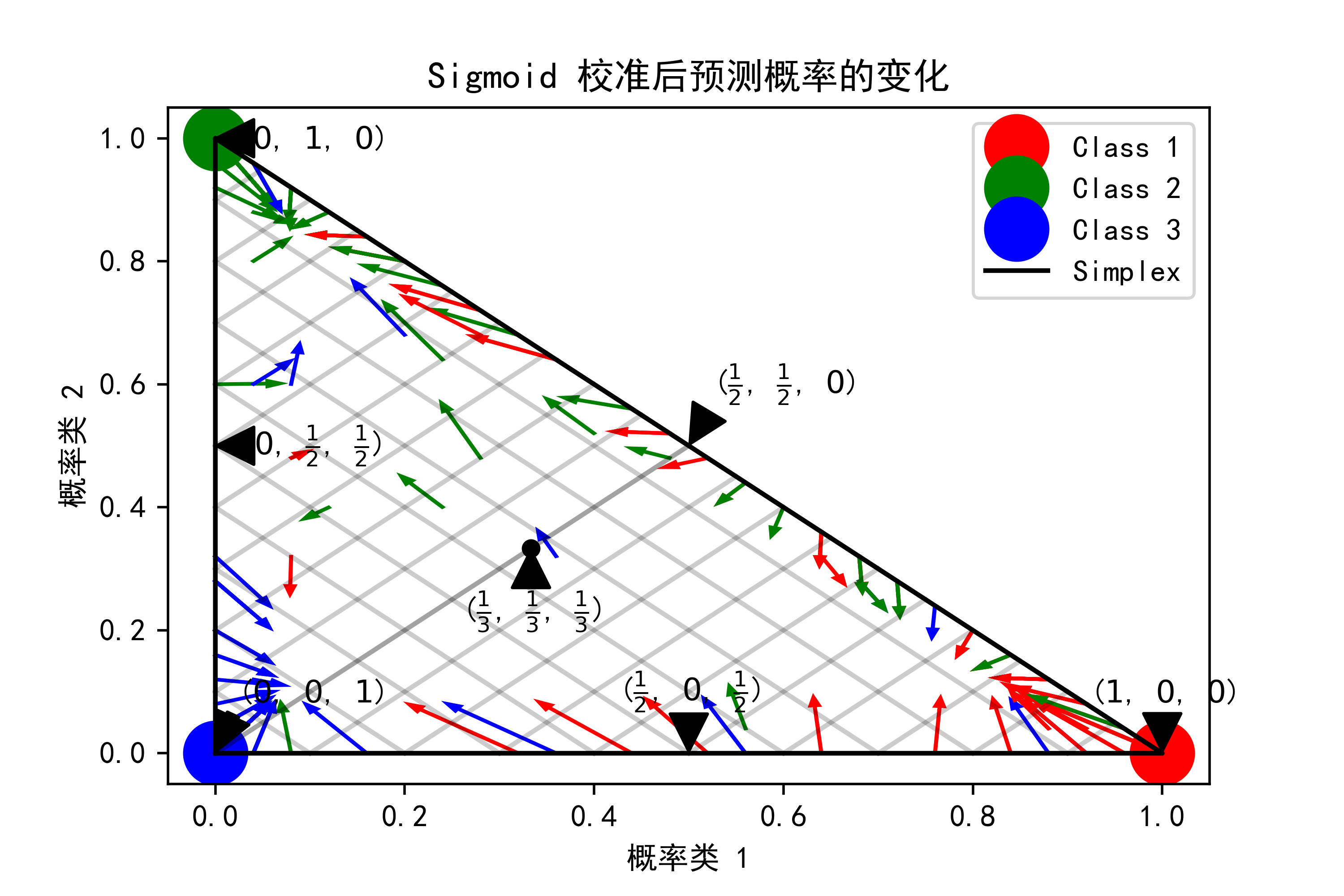
07-三分类的概率校准
在三分类问题中,我们通常希望分类器能够输出每个类别的概率。在一些情况下,分类器可能会输出未校准的概率,这些概率可能不符合我们的期望,例如,可能不是严格的概率(介于0和1之间),或者不是归一化的(所有概率之和不为1)。
sigmoid校准是一种常见的方法,用于将分类器输出的未校准概率转换为合适的概率。该方法使用sigmoid函数,将未校准的概率映射到0到1之间,同时保持概率的相对顺序。
在一个标准的2-simplex示例中,我们可以将三个类别表示为一个等边三角形的三个角。每个角表示一个类别,而三角形内的点表示所有可能的概率向量。对于三分类问题,这些概率向量位于一个平面内的三角形中。
现在,假设我们有一个未校准的分类器,它输出了一个概率向量。这个向量可能不在三角形内,或者不是归一化的。sigmoid校准将对这个向量进行操作,使其在三角形内,并且每个元素都在0到1之间,而且它们的总和为1。
举例来说,假设我们的未校准概率向量是[0.5, 0.3, 0.2],这意味着分类器认为第一类的可能性最高,第二类次之,第三类最低。我们对这个向量进行sigmoid校准后,可能得到[0.6, 0.25, 0.15],这个向量仍然保持了类别之间的相对顺序,但概率值更接近我们期望的形式。
在三分类问题中,颜色通常用来表示实例的真实类别。这样,我们可以在2-simplex上绘制这些实例,将它们分别标记为红色(1类)、绿色(2类)和蓝色(3类)。然后,我们可以用箭头表示从未校准概率向量到校准后概率向量的变化。箭头的方向和长度表示了概率向量的变化方向和幅度。
综上所述,sigmoid校准是将未校准的概率向量转换为合适的概率向量的一种方法,在三分类问题中,它可以通过在2-simplex上绘制实例和概率向量的变化来进行可视化说明。
下面以具体代码分析如何使用matplotlib绘制分类器在进行sigmoid校准后预测概率的变化。具体分析如下:
导入必要的库:代码开始时导入了matplotlib、numpy、sklearn中的make_blobs、RandomForestClassifier、CalibratedClassifierCV以及log_loss等库。
生成数据:使用make_blobs函数生成了包含1000个样本的合成数据集,其中包含3个类别。数据集被分为训练集、验证集和测试集。
1、训练未校准的随机森林分类器并评估:首先,使用600个样本的训练集和验证集来训练随机森林分类器,并在剩余的200个样本的测试集上评估分类器的性能。这个分类器没有经过校准。
2、训练随机森林分类器并进行校准:然后,使用全部600个训练样本训练随机森林分类器,并在验证集上进行校准。最后,在剩余的200个测试样本上评估校准后的分类器性能。
3、绘制预测概率变化图:利用matplotlib绘制了分类器在进行sigmoid校准后预测概率的变化情况。每个数据点的预测概率由一个箭头表示,箭头的起点是未校准分类器的预测概率,终点是校准后分类器的预测概率。根据真实标签,箭头被着色为红色、绿色或蓝色。
4、绘制单位单纯形边界和标记点:在图中绘制了单位单纯形(unit simplex)的边界,并标记了一些点,如(1/3,1/3,1/3)、(1/2,0,1/2)等。
5、输出结果:最后,输出未校准分类器和校准分类器的log-loss评分。
import matplotlib.pyplot as pltimport numpy as npfrom sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
from sklearn.calibration import CalibratedClassifierCV
from sklearn.metrics import log_lossnp.random.seed(0)# Generate data
X, y = make_blobs(n_samples=1000, random_state=42, cluster_std=5.0)
X_train, y_train = X[:600], y[:600]
X_valid, y_valid = X[600:800], y[600:800]
X_train_valid, y_train_valid = X[:800], y[:800]
X_test, y_test = X[800:], y[800:]# Train uncalibrated random forest classifier on whole train and validation
# data and evaluate on test data
clf = RandomForestClassifier(n_estimators=25)
clf.fit(X_train_valid, y_train_valid)
clf_probs = clf.predict_proba(X_test)
score = log_loss(y_test, clf_probs)# Train random forest classifier, calibrate on validation data and evaluate
# on test data
clf = RandomForestClassifier(n_estimators=25)
clf.fit(X_train, y_train)
clf_probs = clf.predict_proba(X_test)
sig_clf = CalibratedClassifierCV(clf, method="sigmoid", cv="prefit")
sig_clf.fit(X_valid, y_valid)
sig_clf_probs = sig_clf.predict_proba(X_test)
sig_score = log_loss(y_test, sig_clf_probs)# Plot changes in predicted probabilities via arrows
plt.figure()
colors = ["r", "g", "b"]
for i in range(clf_probs.shape[0]):plt.arrow(clf_probs[i, 0], clf_probs[i, 1],sig_clf_probs[i, 0] - clf_probs[i, 0],sig_clf_probs[i, 1] - clf_probs[i, 1],color=colors[y_test[i]], head_width=1e-2)# Plot perfect predictions
plt.plot([1.0], [0.0], 'ro', ms=20, label="Class 1")
plt.plot([0.0], [1.0], 'go', ms=20, label="Class 2")
plt.plot([0.0], [0.0], 'bo', ms=20, label="Class 3")# Plot boundaries of unit simplex
plt.plot([0.0, 1.0, 0.0, 0.0], [0.0, 0.0, 1.0, 0.0], 'k', label="Simplex")# Annotate points on the simplex
plt.annotate(r'($\frac{1}{3}$, $\frac{1}{3}$, $\frac{1}{3}$)',xy=(1.0/3, 1.0/3), xytext=(1.0/3, .23), xycoords='data',arrowprops=dict(facecolor='black', shrink=0.05),horizontalalignment='center', verticalalignment='center')
plt.plot([1.0/3], [1.0/3], 'ko', ms=5)
plt.annotate(r'($\frac{1}{2}$, $0$, $\frac{1}{2}$)',xy=(.5, .0), xytext=(.5, .1), xycoords='data',arrowprops=dict(facecolor='black', shrink=0.05),horizontalalignment='center', verticalalignment='center')
plt.annotate(r'($0$, $\frac{1}{2}$, $\frac{1}{2}$)',xy=(.0, .5), xytext=(.1, .5), xycoords='data',arrowprops=dict(facecolor='black', shrink=0.05),horizontalalignment='center', verticalalignment='center')
plt.annotate(r'($\frac{1}{2}$, $\frac{1}{2}$, $0$)',xy=(.5, .5), xytext=(.6, .6), xycoords='data',arrowprops=dict(facecolor='black', shrink=0.05),horizontalalignment='center', verticalalignment='center')
plt.annotate(r'($0$, $0$, $1$)',xy=(0, 0), xytext=(.1, .1), xycoords='data',arrowprops=dict(facecolor='black', shrink=0.05),horizontalalignment='center', verticalalignment='center')
plt.annotate(r'($1$, $0$, $0$)',xy=(1, 0), xytext=(1, .1), xycoords='data',arrowprops=dict(facecolor='black', shrink=0.05),horizontalalignment='center', verticalalignment='center')
plt.annotate(r'($0$, $1$, $0$)',xy=(0, 1), xytext=(.1, 1), xycoords='data',arrowprops=dict(facecolor='black', shrink=0.05),horizontalalignment='center', verticalalignment='center')
# Add grid
plt.grid(False)
for x in [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]:plt.plot([0, x], [x, 0], 'k', alpha=0.2)plt.plot([0, 0 + (1-x)/2], [x, x + (1-x)/2], 'k', alpha=0.2)plt.plot([x, x + (1-x)/2], [0, 0 + (1-x)/2], 'k', alpha=0.2)plt.title("Sigmoid 校准后预测概率的变化")
plt.xlabel("概率类 1")
plt.ylabel("概率类 2")
plt.xlim(-0.05, 1.05)
plt.ylim(-0.05, 1.05)
plt.legend(loc="best")print("Log-loss of")
print(" * 在 800 个数据点上训练的未校准分类器: %.3f "% score)
print(" * 分类器在 600 个数据点上训练并校准 ""200 个数据点: %.3f" % sig_score)plt.savefig("../1.png", dpi=500)
plt.show()实例运行结果如下图所示:箭头的方向和长度表示了每个样本的预测概率变化。完美预测的点分别位于三个类别的理想概率位置,而单纯形边界显示了可行的概率组合。注释点说明了单纯形的一些重要位置,如各类别的均等概率和极端情况下的概率。
总结
综上所述,Scikit-Learn 提供了丰富的集群化和校准功能,可以帮助用户进行无监督学习任务的分析和预测,并且通过校准可以提高模型输出的准确性和可靠性。
这篇关于[机器学习-04] Scikit-Learn机器学习工具包进阶指南:集群化与校准功能实战【2024最新】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





