本文主要是介绍dimension reduce(梯度下降)self-organizing maps(自组织映射),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使数据集的维度减小可以简化问题,带来优化
如更快的处理时间、虚拟化高维度的数据集、抗噪音、增强其他数据挖掘算法
线性降维(Linear dimension reduce)
main linear components能使数据在这一轴的变化范围最大
1-st component是使数据在这一维变化最大的轴方向
2-nd component是当投影到1-st component方向时数据范围最大的轴方向(一般与1-st component的方向垂直)
如图,将一个四维的数据集减小维度到二维的图形转换过程
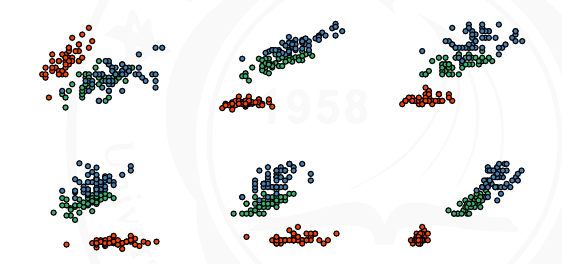
主成分分析(principal component analysis)
主成分分析是找到main linear component的方法,其主要步骤如下:

Self-Organizing Maps
自组织映射是一种简单有效的方法:
1、将数据从到维度降到低维度映射
2、把相似的数据放置在相近位置,无关数据之间的位置较远
3、一种广泛采用的处理复杂类型数据的方法
自组织映射的基本原理:
由n个点组成的map space&#x
这篇关于dimension reduce(梯度下降)self-organizing maps(自组织映射)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



