本文主要是介绍用户画像篇·手撕KNN算法(K近邻),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1、KNN模型
- 2、样本数据
- (1)经验样本
- (2)待分类数据
- 3、需求:使用KNN算法思想,对待分类数据进行分类
- (1)思想:近朱者赤近墨者黑
- (2)代码开干
- 4、总结
- 用到的知识
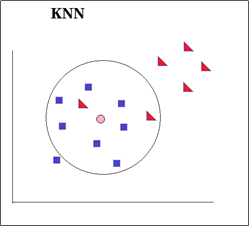
1、KNN模型
2、样本数据
(1)经验样本
label,f1,f2,f3,f4,f5
0,10,20,30,40,30
0,12,22,29,42,35
0,11,21,31,40,34
0,13,22,30,42,32
0,12,22,32,41,33
0,10,21,33,45,35
1,30,11,21,40,34
1,33,10,20,43,30
1,30,12,23,40,33
1,32,10,20,42,33
1,30,13,20,42,30
1,30,09,22,41,32
(2)待分类数据
id,f1,f2,f3,f4,f5
1,11,21,31,44,32
2,14,26,32,39,30
3,32,14,21,42,32
4,34,12,22,42,34
5,34,12,22,42,34
3、需求:使用KNN算法思想,对待分类数据进行分类
(1)思想:近朱者赤近墨者黑
将每一个未知类别的向量,去跟上面样本集中的所有向量求一次距离,然后,找到离它最近5个特征向量,然后看这5个最近的特征向量中哪一种类别占比更多,那就认为,这个未知向量就属于该类别
(2)代码开干
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.linalg
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.types.{DataTypes, StructField, StructType}import scala.collection.mutableobject KNNClassifyArithmetic {def main(args: Array[String]): Unit = {//设定打印日志的等级val logger: Logger = Logger.getLogger(this.getClass.getName)logger.setLevel(Level.DEBUG)Logger.getLogger("org.apache.spark").setLevel(Level.WARN)//创建spark对象val spark: SparkSession = SparkSession.builder().appName(this.getClass.getSimpleName).master("local[*]").getOrCreate()logger.debug("sparkSql入口创建完成")import spark.implicits._// 1、读取经验样本数据val schema1 = StructType(Array[StructField](StructField("label", DataTypes.StringType),StructField("f1", DataTypes.DoubleType),StructField("f2", DataTypes.DoubleType),StructField("f3", DataTypes.DoubleType),StructField("f4", DataTypes.DoubleType),StructField("f5", DataTypes.DoubleType)))val simpleDF: DataFrame = spark.read.option("header", true) //设定为有头信息的csv文件.schema(schema1).csv("userProfile/data/knn/sample/sample.csv")logger.debug("样本数据加载完成,分区数为: " + simpleDF.rdd.partitions.size)// 2、读取待分析样本数据val schema2 = StructType(Array(StructField("id", DataTypes.StringType),StructField("b1", DataTypes.DoubleType),StructField("b2", DataTypes.DoubleType),StructField("b3", DataTypes.DoubleType),StructField("b4", DataTypes.DoubleType),StructField("b5", DataTypes.DoubleType)))val ClassifyDF: DataFrame = spark.read.option("header", true) //设定为有头信息的csv文件.schema(schema2).csv("userProfile/data/knn/to_classify/to_classify.csv")logger.debug("待分类数据加载完成,分区数为: " + ClassifyDF.rdd.partitions.size)// 3、crossJoin 将样本数据和待分析数据做笛卡尔积连接val cjDF: DataFrame = ClassifyDF.crossJoin(simpleDF)logger.debug("待分类数据 cross join 样本数据完成,分区数为: " + cjDF.rdd.partitions.size)/** 笛卡尔积数据如下:|+---+----+----+----+----+----+-----+----+----+----+----+----+||id |b1 |b2 |b3 |b4 |b5 |label|f1 |f2 |f3 |f4 |f5 ||+---+----+----+----+----+----+-----+----+----+----+----+----+||1 |11.0|21.0|31.0|44.0|32.0|0 |10.0|20.0|30.0|40.0|30.0|||2 |14.0|26.0|32.0|39.0|30.0|0 |10.0|20.0|30.0|40.0|30.0|||3 |32.0|14.0|21.0|42.0|32.0|0 |10.0|20.0|30.0|40.0|30.0|||4 |34.0|12.0|22.0|42.0|34.0|0 |10.0|20.0|30.0|40.0|30.0|||5 |34.0|12.0|22.0|42.0|34.0|0 |10.0|20.0|30.0|40.0|30.0|||1 |11.0|21.0|31.0|44.0|32.0|0 |12.0|22.0|29.0|42.0|35.0|||2 |14.0|26.0|32.0|39.0|30.0|0 |12.0|22.0|29.0|42.0|35.0|||3 |32.0|14.0|21.0|42.0|32.0|0 |12.0|22.0|29.0|42.0|35.0|||4 |34.0|12.0|22.0|42.0|34.0|0 |12.0|22.0|29.0|42.0|35.0|||5 |34.0|12.0|22.0|42.0|34.0|0 |12.0|22.0|29.0|42.0|35.0|| ........................|+---+----+----+----+----+----+-----+----+----+----+----+----+*/import org.apache.spark.sql.functions._// 4、计算样本向量和未知类别向量的欧氏距离// ① 先定义一个计算欧氏距离的函数:自定义udfval eudi = udf((arr1: mutable.WrappedArray[Double], arr2: mutable.WrappedArray[Double]) => {//需要Array[Double]类型的。下面eudi中array类型为mutable.WrappedArray,所以上面也定义这样的val v1: linalg.Vector = Vectors.dense(arr1.toArray)val v2: linalg.Vector = Vectors.dense(arr2.toArray)val distance: Double = Vectors.sqdist(v1, v2)distance})// ② 将函数传入计算val distDF: DataFrame = cjDF.select('label,'id,eudi(array('f1, 'f2, 'f3, 'f4, 'f5), array('b1, 'b2, 'b3, 'b4, 'b5)) as "dist")/** 数据如下:* +-----+---+-----+* |label|id |dist |* +-----+---+-----+* |0 |1 |23.0 |* |0 |2 |57.0 |* |0 |3 |609.0|* |0 |4 |724.0|* |0 |5 |724.0|* |0 |1 |19.0 |* |0 |2 |63.0 |* |0 |3 |537.0|* |0 |4 |634.0|* |0 |5 |634.0|* |0 |1 |20.0 |* |0 |2 |52.0 |* | ........... |* +-----+---+-----+*/// 5、取出每个未知人中,5个最近的欧式距离以及类别distDF.createTempView("tmp1")val tmpDF: DataFrame = spark.sql("""|select|label,|id,|dist|from|(| select| label,| id,| dist,| row_number() over(partition by id order by dist) as rn| from| tmp1|)t|where rn <= 5|""".stripMargin)/** 数据如下:* +-----+---+----+* |label|id |dist|* +-----+---+----+* |0 |1 |10.0|* |0 |1 |13.0|* |1 |1 |15.0|* |0 |1 |19.0|* |0 |1 |20.0|* |1 |4 |13.0|* |1 |4 |22.0|* |1 |4 |22.0|* |1 |4 |26.0|* |1 |4 |30.0|* |0 |2 |33.0|* |0 |2 |34.0|* |0 |2 |52.0|* |0 |2 |57.0|* |0 |2 |63.0|* | ........ |* +-----+---+----+*/// 6、计算在5个最近的欧式距离中,数量最多的那个类别tmpDF.createTempView("tmp2")spark.sql("""|select|label,|id,|count(1) as cons|from|tmp2|group by label, id|having cons > 2|""".stripMargin).drop("cons").orderBy("id").show(20, false)/** 最终结果:* +-----+---+* |label|id |* +-----+---+* |0 |1 |* |0 |2 |* |1 |3 |* |1 |4 |* |1 |5 |* +-----+---+*/spark.close()}
}
4、总结
用到的知识
(1)log4j打印日志的使用和打印等级的设定
(2)DataFrame的创建方式、自定义schema
(3)SparkSql中自定义UDF函数
(4)欧氏距离的计算、原理(欧几里得公式)
这篇关于用户画像篇·手撕KNN算法(K近邻)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









