本文主要是介绍[机器学习系列]深入探索回归决策树:从参数选择到模型可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、回归决策树的参数
二、准备数据
三、构建回归决策树
(一)拟合模型
(二)预测数据
(三)查看特征重要性
(四)查看模型拟合效果
(五) 可视化回归决策树真实值和预测值
(六)可视化决策树并保存
部分结果如下:
一、回归决策树的参数
DecisionTreeRegressor(*, criterion='mse', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, presort='deprecated', ccp_alpha=0.0)具体参数解释可参考下方链接的文档,几乎和分类决策树相差不大
sklearn.tree.DecisionTreeRegressor-scikit-learn中文社区
二、准备数据
from sklearn.datasets import load_boston
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split# 加载数据
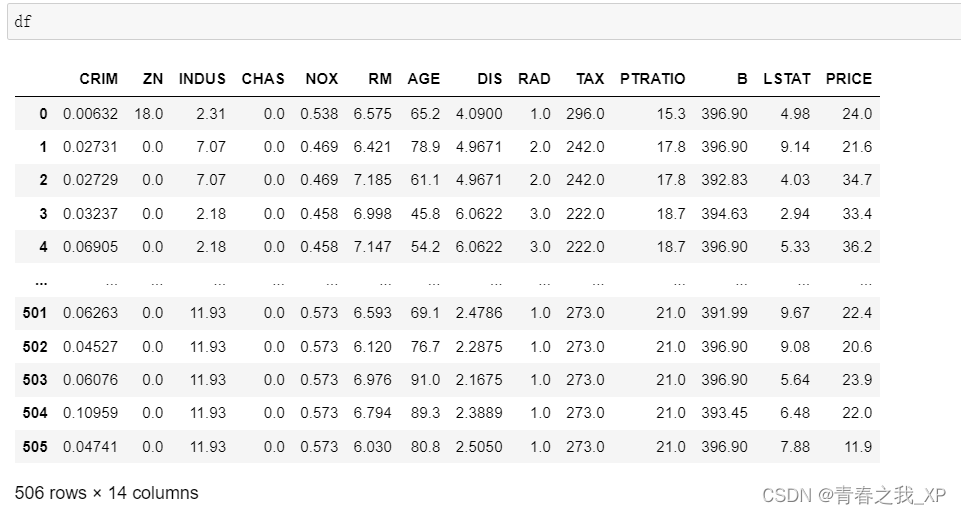
boston = load_boston()# 创建DataFrame
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['PRICE'] = boston.target# 数据特征和目标变量
X = df.drop('PRICE', axis=1)
y = df['PRICE']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 打印训练集和测试集的形状
print("训练集特征数据形状:", X_train.shape)
print("训练集目标变量形状:", y_train.shape)
print("测试集特征数据形状:", X_test.shape)
print("测试集目标变量形状:", y_test.shape)
三、构建回归决策树
(一)拟合模型
from sklearn.tree import DecisionTreeRegressor
clf=DecisionTreeRegressor()
clf = clf.fit(X_train, y_train)
(二)预测数据
y_pred=clf.predict(X_test)(三)查看特征重要性
clf.feature_importances_(四)查看模型拟合效果
from sklearn.metrics import r2_score,mean_squared_error, explained_variance_score, mean_absolute_error
print("决策树回归模型测试集R^2:",round(r2_score(y_test,y_pred)))
print("决策树回归模型测试集均方误差:",round(mean_squared_error(y_test,y_pred)))
print("决策树回归模型测试集解释方差分:",round(explained_variance_score(y_test,y_pred)))
print("决策树回归模型测试集绝对误差:",round(mean_absolute_error(y_test,y_pred)))(五) 可视化回归决策树真实值和预测值
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']# 假设X_test和y_test已经定义好了
plt.figure(figsize=(10, 6)) # 创建一个新的图形,设置大小
plt.plot(range(len(y_test)), y_test, color='blue', label='实际值') # 绘制散点图,实际值用蓝色表示
plt.plot(range(len(y_pred)), y_pred, color='red', label='预测值') # 绘制预测值的线,用红色表示
plt.title('决策树回归预测与实际值对比') # 图表标题
plt.xlabel('测试集样本') # X轴标签
plt.ylabel('值') # Y轴标签
plt.legend() # 显示图例
plt.grid(True) # 显示网格
plt.show() # 显示图表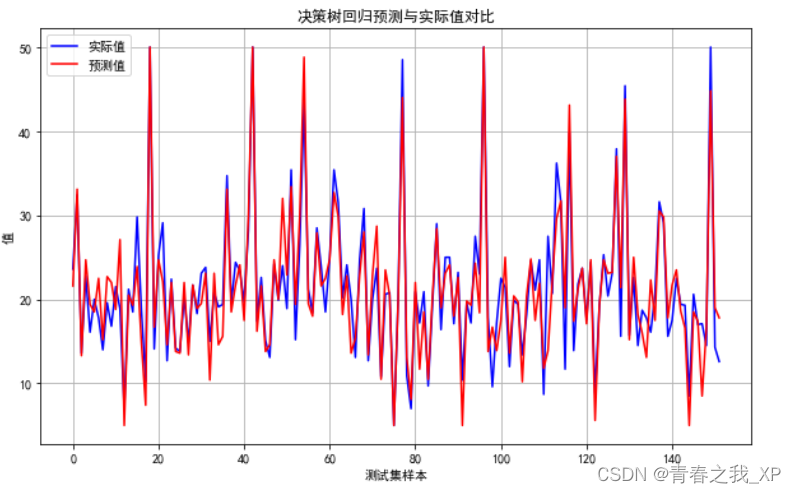
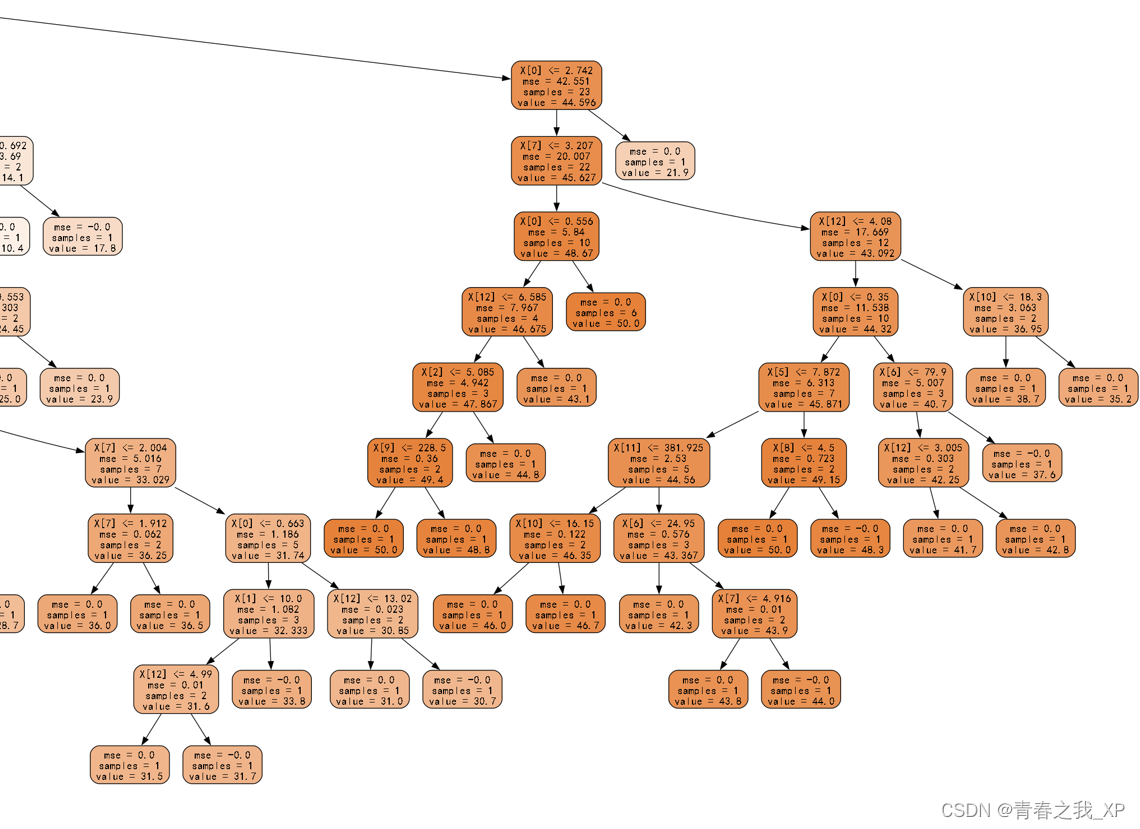
(六)可视化决策树并保存
import graphviz
from sklearn import tree
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']dot_data = tree.export_graphviz(clf,out_file = None, filled=True, rounded=True)
dot_data=dot_data.replace('helvetica', 'SimHei')
graph = graphviz.Source(dot_data)
graph.render("my_decision_tree", format='png') # 保存为png格式graph部分结果如下:
可通过控制树的深度、叶子节点等参数对决策树进行剪枝操作。可以通过网格搜索法进行参数调优。具体可参考往期博客:
决策树分类任务实战(python 代码详解)-CSDN博客
这篇关于[机器学习系列]深入探索回归决策树:从参数选择到模型可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






