本文主要是介绍Sarcasm detection论文解析 |使用 BERT 进行中间任务迁移学习的刺检测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文地址
论文地址:https://www.mdpi.com/2227-7390/10/5/844#/
github:edosavini/TransferBertSarcasm (github.com)
论文首页

笔记框架
使用 BERT 进行中间任务迁移学习的讽刺检测
📅出版年份:2022
📖出版期刊:Mathematics
📈影响因子:2.4
🧑文章作者:Savini Edoardo,Caragea Cornelia
📍 期刊分区:Number: 5 Publisher: Multidisciplinary Digital Publishing Institute JCR分区: Q1 中科院分区升级版: 数学3区 中科院分区基础版: 数学2区 影响因子: 2.4 5年影响因子: 2.3 南农高质量: A
🔎 摘要:
讽刺检测在自然语言处理中发挥着重要作用,因为它可以影响许多应用程序的性能,包括情感分析、意见挖掘和立场检测。尽管讽刺检测取得了实质性进展,但研究结果分散在数据集和研究中。在本文中,我们调查了当前的最新技术,并提出了基于 BERT 预训练语言模型的讽刺检测的强大基线。我们通过在目标任务上微调之前对相关中间任务进行微调来进一步改进我们的 BERT 模型。具体来说,依靠讽刺与(隐含的负面)情绪和情感之间的相关性,我们探索了一种迁移学习(Transfer Learning)框架,该框架使用情感分类和情感检测作为单独的中间任务,将知识注入讽刺检测的目标任务中。在具有不同特征的三个数据集上的实验结果表明,基于 BERT 的模型优于许多先前的模型。
🌐 研究目的:
我们的目的是分析 BERT 和使用 BERT 的中间任务迁移学习在讽刺检测任务上的有效性,并找到一个能够准确预测从论坛到微博等多种社交平台中讽刺的神经框架。
📰 研究背景:
尽管讽刺检测取得了实质性进展,但研究结果分散在数据集和研究中。
🔬 研究方法:
基于 BERT 预训练语言模型,探索了一种迁移学习(Transfer Learning)框架
🔩 模型架构:
BERT预训练语言模型
我们在我们的目标任务(即讽刺检测)上对 HuggingFace Transformers 库 [36] 中的 BERT bert-base-uncased 进行了微调,在顶部添加了一个线性层作为句子分类器,该分类器使用与 [ 相对应的最终隐藏状态CLS] 令牌。
中级任务迁移学习
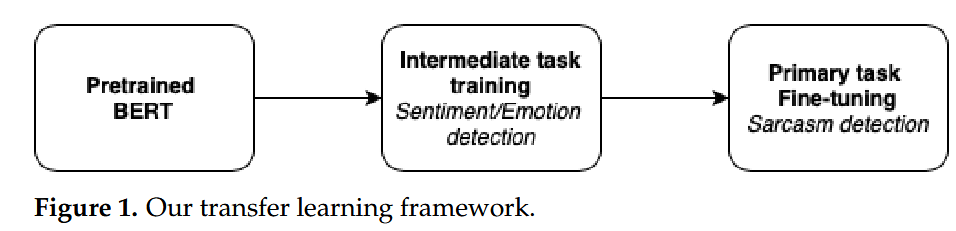
我们提议从情感分类和情感检测这两个相关的中间任务中探索迁移学习,以了解我们能否进一步提高 BERT 模型在讽刺语检测目标任务上的性能。
-
目标任务
-
中间任务
标准神经网络模型
BiLSTM
使用隐藏维度为 100 的单层 BiLSTM [40] 来获取每个 token 的特征,然后对特征进行均值池化,然后是全连接层和 softmax。
我们注意到,我们的数据集之前的工作中通常使用 CNN。当之前的工作中不可用时,我们使用了[41]中的超参数设置。
CNN
我们注意到,我们的数据集之前的工作中通常使用 CNN。当之前的工作中不可用时,我们使用了[41]中的超参数设置。
🧪 实验:
📇 数据集:
数据集来自互联网争论语料库 (IAC) [11]、Reddit [18] 和 Twitter [7]。
EmoNet
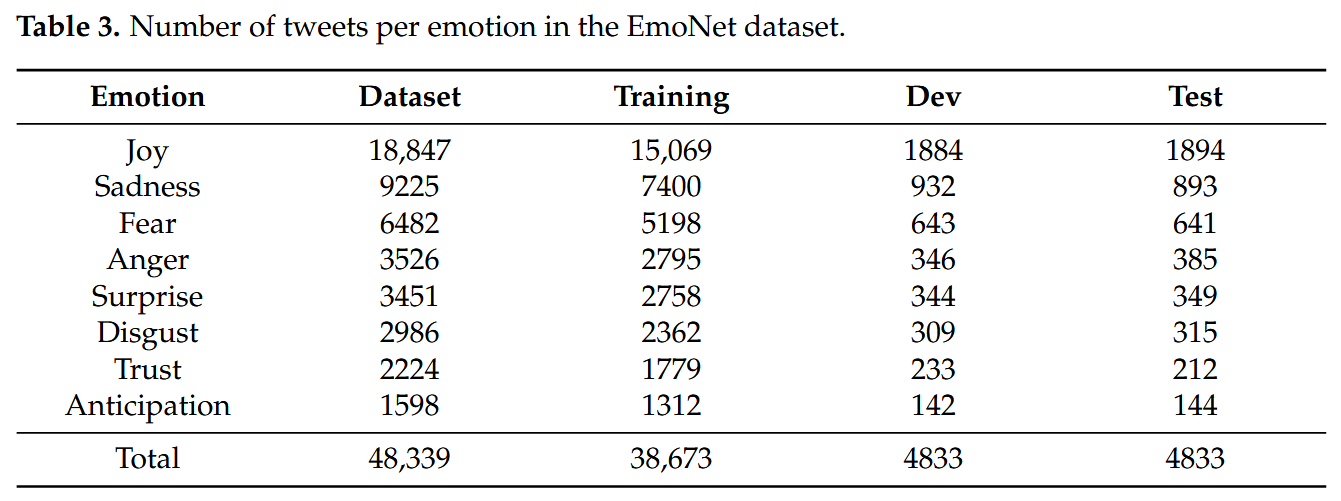 EmoNet [38] 是一个 Twitter 数据集,由使用 Plutchik-24 情感集的远程监督自动注释的推文组成。
EmoNet [38] 是一个 Twitter 数据集,由使用 Plutchik-24 情感集的远程监督自动注释的推文组成。
Sarcasm V2 Corpus.
对于我们的方法,我们将 Gen 数据集随机分为 90% 的训练集和 10% 的测试集。然后,我们将临时训练集分为 80% 训练集和 20% 验证集。
五折交叉验证

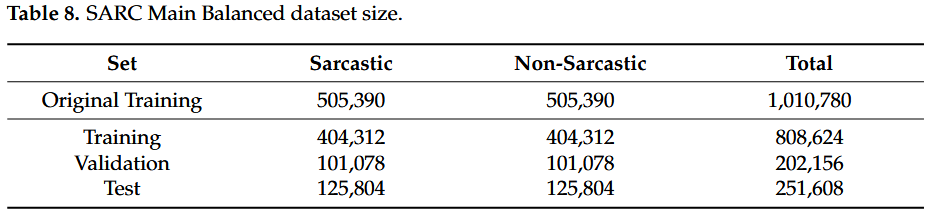
Reddit Corpus (SARC)
将原始训练集分为 80% 训练和 20% 验证。
SARCTwitter
我们决定将数据集随机分割五次,保持讽刺和非讽刺推文之间的比例不变(与原始集中相同)。
我们将最初的 994 条推文分为 90% 的训练集和 10% 的测试集。然后,我们再次将获得的训练集分为 80% 训练和 20% 验证,始终保持标签之间的比例不变(见表 9)

📏 评估指标:
📉 优化器&超参数:
批量大小16
AdaGrad 优化器 [44],将梯度裁剪阈值设置为 5.0。
一旦验证集上的平均 F1 在一些连续的 epoch 后停止增长(耐心设置为 5),训练就会停止(对于目标任务和中间任务)
💻 实验设备:
我们使用 AllenNLP 库 [42] 和 HuggingFace Transformers 库 [36] 来实现我们的模型。
们在 PyTorch 环境中使用 AWS 平台、EC2 实例(Ubuntu 深度学习 AMI)和一个 GPU。
📊 消融实验:
📋 实验结果:
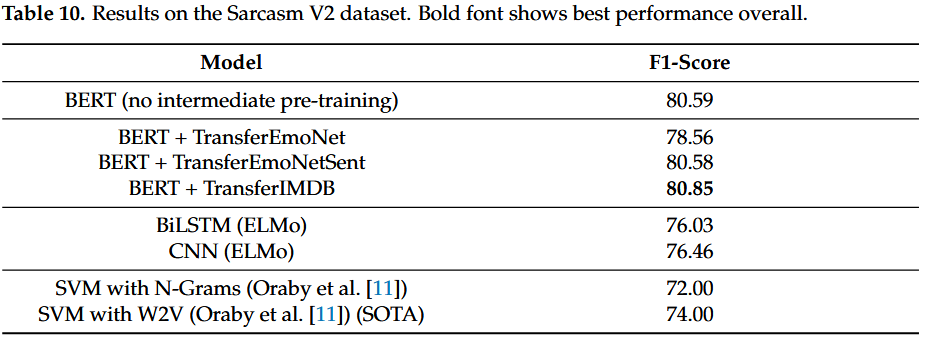
Sarcasm V2 Corpus.
表 10 中的结果表明,我们所有的实验都优于 Sarcasm V2 语料库的现有最新技术。
除 TransferEmoNet 之外的传输模型都达到了类似的结果。
Reddit Corpus (SARC)
该表分为两部分:第一部分包含在不使用任何附加信息的情况下对句子本身进行的所有实验,而第二部分包含利用作者的个性特征的模型的性能评论。
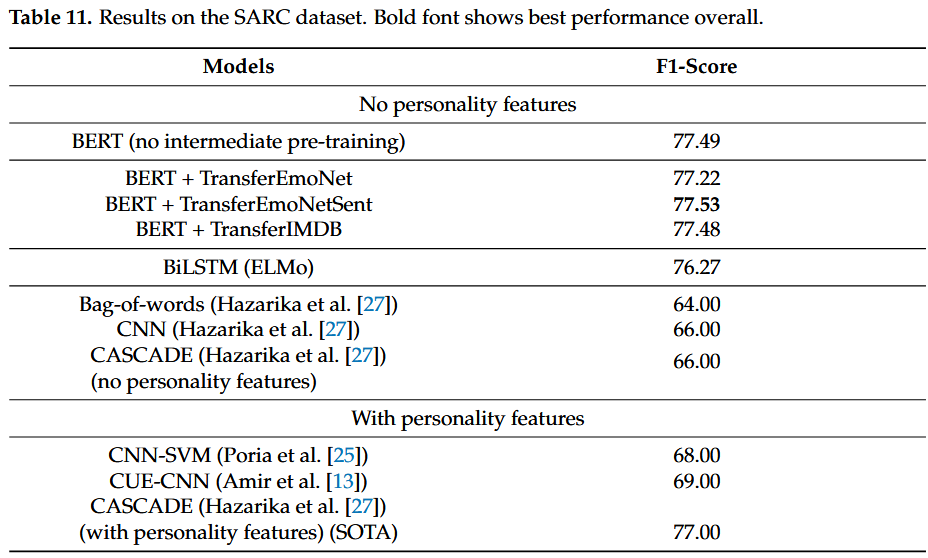
我们可以注意到,在表的第一部分中,我们所有的模型都比所有其他先前的工作表现至少 10%,证实了通过预先训练的语言模型用于讽刺预测任务捕获语义的功效。
然而,来自 EmoNet 的情感信息略微提高了简单 BERT 分类的效率,使我们的 TransferEmoNetSent 模型成为 SARC 数据集上新的最先进的性能。
SARCTwitter
我们所有的模型都比之前最先进的模型至少高出 5%。
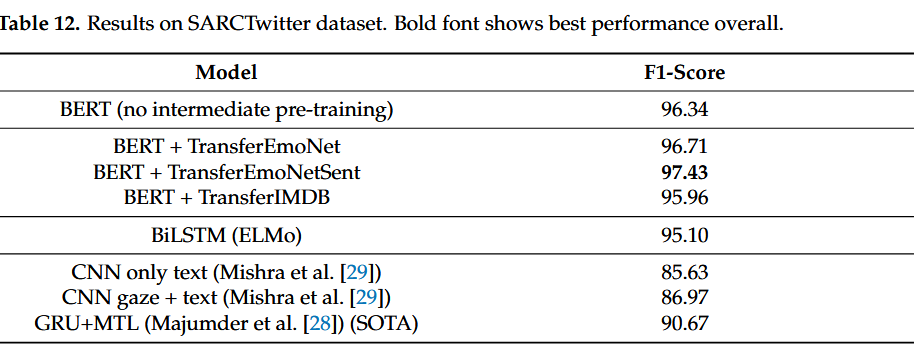
这些结果证实了之前实验的模式,证明了讽刺和情绪之间的相关性,并且还表明极化的情绪信息可以帮助主要/目标任务从情绪电荷更明确的数据集中进行转移,例如注释的 EmoNet使用词汇表面模式进行远程监督[38]。
🚩 研究结论:
我们展示了讽刺性言论本身是如何自动识别并具有良好的性能,甚至无需进一步使用上下文信息。
我们还探索了一种迁移学习框架,以利用讽刺与文本中传达的情绪或情感之间的相关性,并发现对相关任务进行中间任务训练可以提高基本 BERT 模型的有效性。
我们在三个数据集上建立了新的最先进的讽刺检测结果。具体来说,与之前的讽刺检测工作相比,基于 BERT 的模型(有或没有中间任务迁移学习)的性能提升非常显着,高达 11.53%。
我们发现,仅使用消息内容的 BERT 模型比利用作者历史中附加信息(在之前的工作中编码为个性特征)的模型表现更好。我们发现这个结果非常显着。
此外,如果目标任务(讽刺检测)的数据集大小很小,那么中间任务迁移学习(以情感作为中间任务)可以进一步提高性能。
📝 总结
💡 创新点:
依靠讽刺与(隐含的负面)情绪和情感之间的相关性,我们探索了一种迁移学习框架,该框架使用情感分类和情感检测作为单独的中间任务,将知识注入讽刺检测的目标任务中。
我们基于 BERT 预训练语言模型为此任务建立了强大的基线。我们的分析基于对三个不同大小(从小数据集到大数据集)的讽刺数据集进行的实验结果。
受现有讽刺研究 [6] 的启发,我们使用不同的中间任务(从一般推文中进行细粒度的情绪检测,通过将上述数据集中的情绪极化为积极和消极情绪来进行粗粒度的情绪极性,以及电影评论的情绪分类)。
对于我们的方法,我们将 Gen 数据集随机分为 90% 的训练集和 10% 的测试集。然后,我们将临时训练集分为 80% 训练集和 20% 验证集。
⚠ 局限性:
🔧 改进方法:
🖍️ 知识补充:
BERT 预训练语言模型 [16] 突破了许多自然语言理解任务的性能界限。
TransferEmoNet 的较低性能可以通过 IAC 中稀缺的情感分布来解释。
事实上,讽刺V2的评论主要是对辩论的回应,其中恐惧和期待等情绪很少见。
像 Reddit 这样的中间任务的社交平台在内容、表现力和话题上都有很大的不同。例如,SARC 评论的长度可以从 3/4 个单词到数百个单词不等,而 IMDB 电影评论通常更长,由多个句子组成,而 EmoNet 推文通常仅由一两个句子组成。此外,在 EmoNet 上,情绪模式更加明显,因为人们更倾向于在 Twitter 上描述自己的情绪状态。
在 SARC 中,可能也是因为所涵盖的主题(例如政治、电子游戏),情感模式更加隐晦且难以察觉。
此外,如果目标任务(讽刺检测)的数据集大小很小,那么中间任务迁移学习(以情感作为中间任务)可以进一步提高性能。
💬 讨论:
这篇关于Sarcasm detection论文解析 |使用 BERT 进行中间任务迁移学习的刺检测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




