本文主要是介绍spss 导入数据的时候 用于确定数据类型的值所在的百分比95%是什么意思,数据分析,医学数据分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在SPSS中,当提及“数据类型的值所在的百分比95%”时,这通常与数据的统计分布或置信区间有关,而不是直接关于数据类型的定义。
导入数据的时候需要定义数据类型,那么根据提供的数据,来定义,有时候,同一个列的数据类型不是百分百一致的。
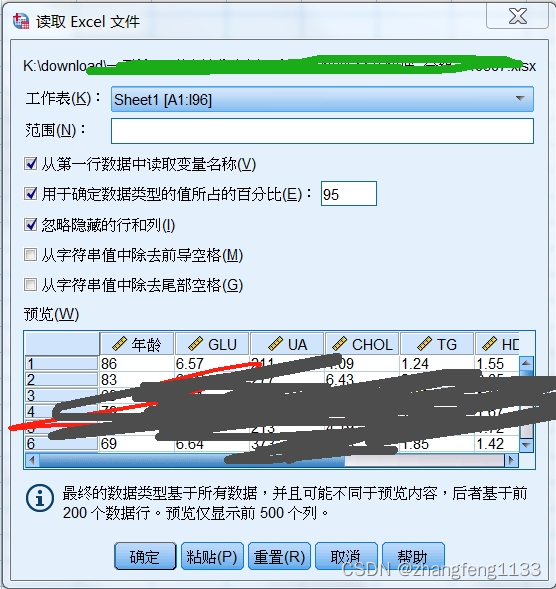
具体来说,95%的百分比可能指的是以下几个方面的内容:
-
置信区间:在统计学中,置信区间是一个范围,该范围预计会包含某个未知参数的真实值,且这个范围是基于样本数据计算得出的。例如,如果我们说某个估计量的95%置信区间是[a, b],那么我们可以有95%的置信度认为这个未知参数的真实值落在[a, b]这个范围内。
-
百分位数:百分位数是用于描述数据集中某个特定百分比的数值所对应的位置。例如,第95百分位数表示有95%的数据值小于或等于这个数。在SPSS中,你可以使用“描述统计”>“百分位数”来计算数据的百分位数。
-
频率分析:当你说“确定数据类型的值所在的百分比95%”时,可能是在描述某个特定数据类型(如某个分类变量)的某个值或类别在数据集中出现的频率达到了95%。然而,这种说法在统计学中并不常见,因为通常我们会直接给出具体的频率或百分比,而不是说“95%的百分比”。
-
数据验证或清洗:在某些情况下,你可能会对数据进行验证或清洗,以确保某个特定字段或变量的值在数据集中出现的频率或百分比符合你的预期。例如,你可能想要确保某个分类变量的某个值在数据集中出现的百分比接近或等于95%,以验证数据的完整性或准确性。
需要注意的是,SPSS本身并不直接提供“确定数据类型的值所在的百分比95%”这样的功能。你需要根据具体的分析目的和数据集来选择合适的统计方法或工具来达到你的目标。如果你有更具体的问题或需要进一步的指导,请提供更多关于你的数据和分析目标的信息。
SPSS(Statistical Package for the Social Sciences)是一款广泛使用的统计软件,用于处理和分析各种数据类型。在SPSS中,确定数据类型的值所在的百分比通常涉及数据分组和频率分析。
以下是一个基本的步骤指南,用于在SPSS中确定数据类型的值所在的百分比:
-
数据准备:首先,确保你已经将数据导入到SPSS中,并且数据已经被正确地编码和分类。
-
数据类型识别:在SPSS中,数据类型通常被分为以下几类:
- 定类数据(Nominal):按事物某种属性分类或分组,数字大小代表类别。例如:性别(男和女)。
- 定序数据(Ordinal):数据的中间级,用数字表示个体在某个有序状态中所处的位置,不能做四则运算。例如:满意度评级(1=非常不满意,5=非常满意)。
- 定距数据(Interval):表现为数值,有单位,没有绝对零点,可以做加减运算,不能做乘除运算。例如:温度。
- 定比数据(Ratio):表现为数值,可以进行加、减、乘、除运算以精确计算数据。例如:身高、体重。
-
数据分组:如果你想要根据某个定类或定序变量(如年龄)来确定其他变量的百分比分布,你可能需要先对数据进行分组。例如,你可以将年龄分为青年、中年和老年组。
-
频率分析:在SPSS中,你可以使用“频率”分析(或称为“交叉表”)来确定数据类型的值所在的百分比。具体步骤如下:
- 在菜单栏中,选择“分析”>“描述统计”>“交叉表”。
- 在弹出的对话框中,选择你要分析的变量。通常,你会选择一个行变量(如年龄组)和一个列变量(如你感兴趣的另一个变量)。
- 点击“确定”运行分析。SPSS将生成一个交叉表,显示行变量和列变量的各种组合的频率和百分比。
-
解读结果:查看SPSS生成的交叉表,你可以找到你感兴趣的变量在每个数据组(如年龄组)中的百分比分布。
-
保存和导出:如果需要,你可以将分析结果保存为SPSS数据文件或导出为其他格式(如Excel或Word),以便进一步分析或报告。
请注意,这些步骤可能会因SPSS版本和具体数据集的差异而有所不同。如果你遇到任何问题或需要更具体的指导,请参考SPSS的官方文档或寻求专业的统计咨询。
QQ 346767073 微 huazhongxiaosx
这篇关于spss 导入数据的时候 用于确定数据类型的值所在的百分比95%是什么意思,数据分析,医学数据分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






