本文主要是介绍大模型_DISC-MedLLM基于Baichuan-13B-Base医疗健康对话,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- DISC-MedLLM
- 介绍
- 概述
- 数据集
- 部署
- 推理流程
DISC-MedLLM
介绍
DISC-MedLLM 是一个专门针对医疗健康对话式场景而设计的医疗领域大模型,由复旦大学数据智能与社会计算实验室 (Fudan-DISC) 开发并开源。
该项目包含下列开源资源:
DISC-Med-SFT 数据集 (不包括行为偏好训练数据)
DISC-MedLLM 的模型权重
概述
DISC-MedLLM 是一个专为医疗健康对话场景而打造的领域大模型,它可以满足您的各种医疗保健需求,包括疾病问诊和治疗方案咨询等,为您提供高质量的健康支持服务。
DISC-MedLLM 有效地对齐了医疗场景下的人类偏好,弥合了通用语言模型输出与真实世界医疗对话之间的差距,这一点在实验结果中有所体现。
得益于我们以目标为导向的策略,以及基于真实医患对话数据和知识图谱,引入LLM in the loop 和 Human in the loop的多元数据构造机制,DISC-MedLLM 有以下几个特点:
- 可靠丰富的专业知识,我们以医学知识图谱作为信息源,通过采样三元组,并使用通用大模型的语言能力进行对话样本的构造。
- 多轮对话的问询能力,我们以真实咨询对话纪录作为信息源,使用大模型进行对话重建,构建过程中要求模型完全对齐对话中的医学信息。
- 对齐人类偏好的回复,病人希望在咨询的过程中获得更丰富的支撑信息和背景知识,但人类医生的回答往往简练;我们通过人工筛选,构建符合人类偏好的高质量的小规模行为微调样本,对齐病人的需求。
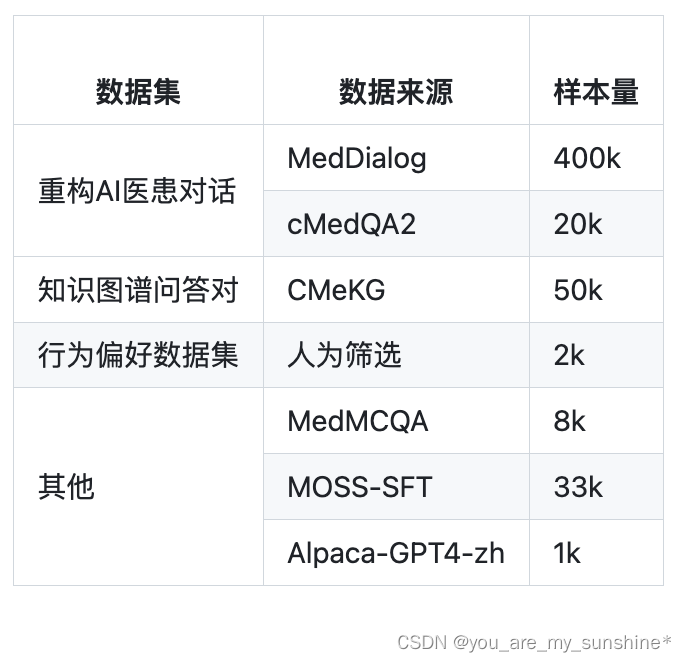
数据集
为了训练 DISC-MedLLM ,我们构建了一个高质量的数据集,命名为 DISC-Med-SFT,其中包含了超过47万个衍生于现有的医疗数据集重新构建得到的样本。我们采用了目标导向的策略,通过对于精心选择的几个数据源进行重构来得到SFT数据集。这些数据的作用在于帮助模型学习医疗领域知识,将行为模式与人类偏好对齐,并对齐真实世界在线医疗对话的分布情况。
部署
当前版本的 DISC-MedLLM 是基于Baichuan-13B-Base训练得到的。可以直接从 Hugging Face 上下载我们的模型权重
推理流程
git clone https://github.com/FudanDISC/DISC-MedLLM.gitcd DISC-MedLLMsource activateconda activate DISC-MedLLM
vi tuili.py 编辑待执行程序
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("/data/sim_chatgpt/DISC-MedLLM", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("/data/sim_chatgpt/DISC-MedLLM", device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained("/data/sim_chatgpt/DISC-MedLLM")
messages = []
messages.append({"role": "user", "content": "我感觉自己颈椎非常不舒服,每天睡醒都会头痛"})
response = model.chat(tokenizer, messages)
print(response)
python tuili.py 执行程序

学习的参考资料:
DISC-MedLLM项目地址
DISC-MedLLM—中文医疗健康助手
这篇关于大模型_DISC-MedLLM基于Baichuan-13B-Base医疗健康对话的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








