baichuan专题

大模型_DISC-MedLLM基于Baichuan-13B-Base医疗健康对话
文章目录 DISC-MedLLM介绍概述数据集部署推理流程 DISC-MedLLM 介绍 DISC-MedLLM 是一个专门针对医疗健康对话式场景而设计的医疗领域大模型,由复旦大学数据智能与社会计算实验室 (Fudan-DISC) 开发并开源。 该项目包含下列开源资源: DISC-Med-SFT 数据集 (不包括行为偏好训练数据) DISC-MedLLM 的模型权重

LLM长度外推——位置插值(llama/baichuan)
位置插值(position Interpolation, PI)通过将超出训练长度的位置索引等比例缩小,映射到模型已经学习的位置范围内,实现长度外推。 好处是不用重新训练,直接在推理时加入。 llama的实现方式 论文提出 Extending Context Window of Large Language Models via Positional Interpolation llama采用

Baichuan-7B-chat WebDemo 部署调用
Baichuan-7B-chat WebDemo 部署调用 Baichuan2 介绍 Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练。在多个权威的中文、英文和多语言的通用、领域 benchmark 上取得同尺寸最佳的效果。 环境准备 在autodl平台中租一个3090等24G显存的显卡机器,如下图所示镜像选择PyTorch–>

【Langchain】+ 【baichuan】实现领域知识库【RAG】问答系统
本项目使用Langchain 和 baichuan 大模型, 结合领域百科词条数据(用xlsx保存),简单地实现了领域百科问答实现。 from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitterfrom langchain_community.embeddings import
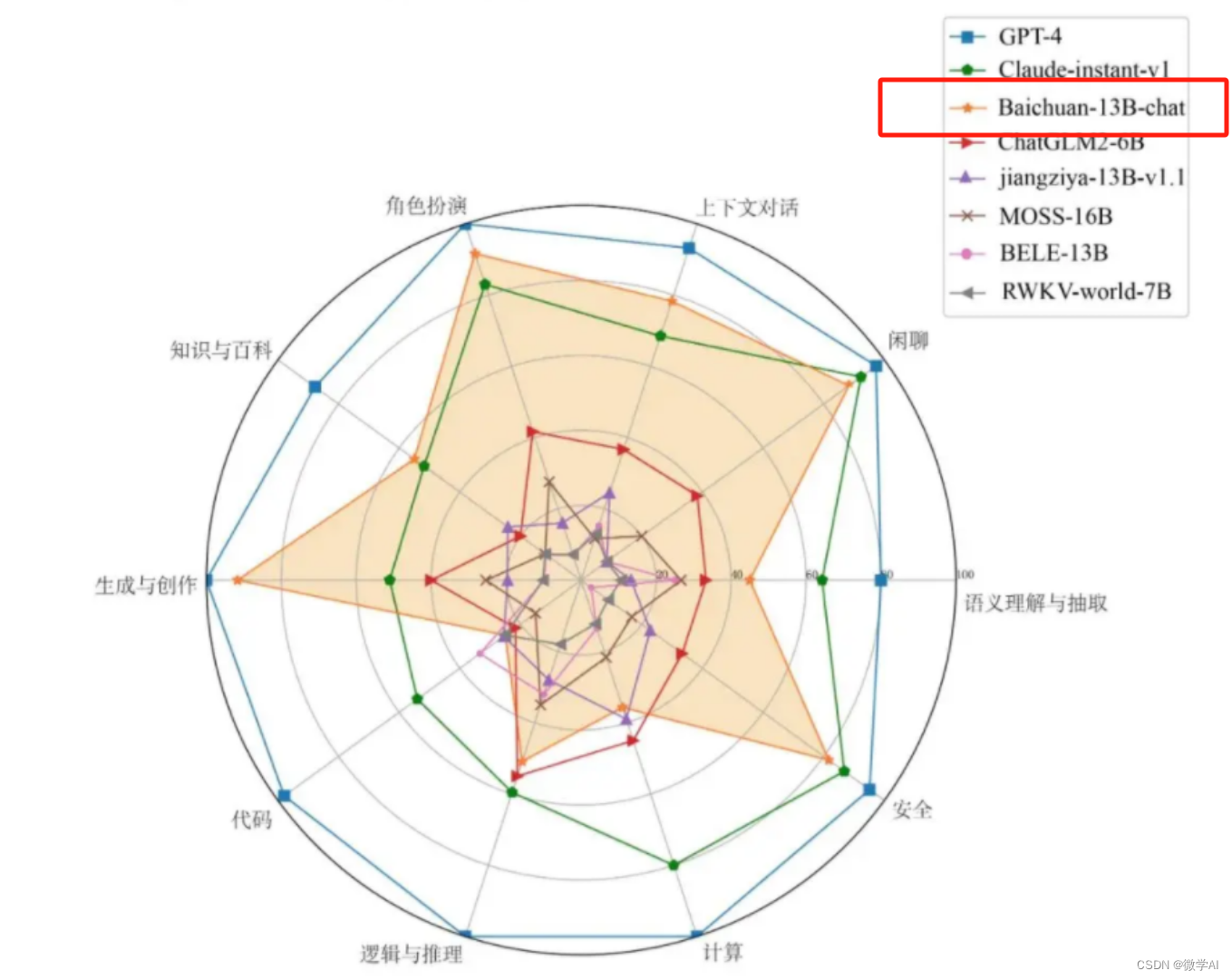
大模型的实践应用5-百川大模型(Baichuan-13B)的模型搭建与模型代码详细介绍,以及快速使用方法
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用5-百川大模型(Baichuan-13B)的模型搭建与模型代码详细介绍,以及快速使用方法。 Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。本次发布包含有预训练 (Baichuan-13B-Base)