13b专题

【文末附gpt升级秘笈】关于论文“7B?13B?175B?解读大模型的参数的论文
论文大纲 引言 简要介绍大模型(深度学习模型)的概念及其在各个领域的应用。阐述参数(Parameters)在大模型中的重要性,以及它们如何影响模型的性能。引出主题:探讨7B、13B、175B等参数规模的大模型。 第一部分:大模型的参数规模 定义“B”代表的意义(Billion/十亿)。解释7B、13B、175B等参数规模的具体含义和计算方法。举例说明这些参数规模的大模型(如GPT系列、BE

7B?13B?175B?解读大模型的参数
大模型也是有大有小的,它们的大小靠参数数量来度量。GPT-3就有1750亿个参数,而Grok-1更是不得了,有3140亿个参数。当然,也有像Llama这样身材苗条一点的,参数数量在70亿到700亿之间。 这里说的70B可不是指训练数据的数量,而是指模型中那些密密麻麻的参数。这些参数就像是一个个小小的“脑细胞”,越多就能让模型更聪明,更能理解数据中那些错综复杂的关系。有了这些“脑细胞”,模型在处

大模型_DISC-MedLLM基于Baichuan-13B-Base医疗健康对话
文章目录 DISC-MedLLM介绍概述数据集部署推理流程 DISC-MedLLM 介绍 DISC-MedLLM 是一个专门针对医疗健康对话式场景而设计的医疗领域大模型,由复旦大学数据智能与社会计算实验室 (Fudan-DISC) 开发并开源。 该项目包含下列开源资源: DISC-Med-SFT 数据集 (不包括行为偏好训练数据) DISC-MedLLM 的模型权重
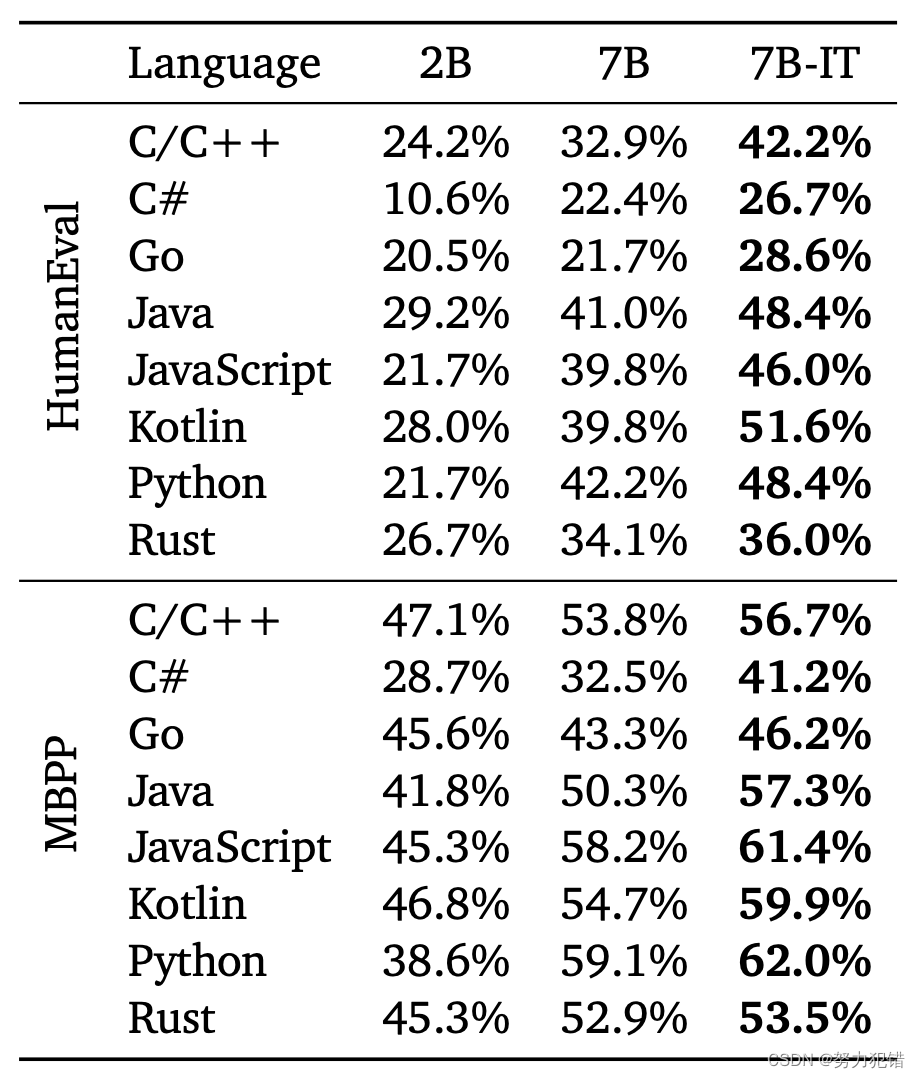
Google 发布 CodeGemma 7B,8K上下文,性能超CodeLlama 13B
CodeGemma简介 CodeGemma模型是谷歌的社区开放编程模型,专门针对代码领域进行优化。一系列功能强大的轻量级模型,能够执行多种编程任务,如中间代码填充、代码生成、自然语言理解、数学推理和指令遵循。CodeGemma模型是在大约500B个主要为英语、数学和代码的数据上进行了进一步训练,以提高逻辑和数学推理能力,适用于代码补全和代码生成编程任务。 Huggingface模型下载:ht
科大讯飞星火开源大模型iFlytekSpark-13B GPU版部署方法
星火大模型的主页:iFlytekSpark-13B: 讯飞星火开源-13B(iFlytekSpark-13B)拥有130亿参数,新一代认知大模型,一经发布,众多科研院所和高校便期待科大讯飞能够开源。 为了让大家使用的更加方便,科大讯飞增加了更多的数据,并针对工具链进行了优化。此次正式开源拥有130亿参数的iFlytekSpark-13B模型(讯飞星火开源-13B),也是首个基于全国产化算力平台“飞

Google 发布 CodeGemma:7B 力压 CodeLLaMa-13B
刚刚发布!Google 带来了新的 Gemma 家族成员,CodeGemma,这是基于预训练的 Gemma-2B 和 Gemma-7B 的代码生成模型。 其上下文窗口长度为8K,在另外 500 B 个主要由英语、数学和代码组成的 token 上进行了训练,改进了逻辑和数学推理能力,适合代码生成任务。 GPT-3.5研究测试: https://hujiaoai.cn GPT-4研究测试: ht

清华系2B模型杀出,性能吊打LLaMA-13B,170万tokens仅需1块钱
清华系面壁智能开始卷小模型了:14 天实现用 2B 模型超越 7B、13B,170 万 tokens 仅花 1 块钱 2 月 1 日,面壁智能与清华大学自然语言处理实验室共同开源了系列端侧语言大模型 MiniCPM,主体语言模型 MiniCPM-2B 仅有 24 亿(2.4B)的非词嵌入参数量。 在综合性榜单上与 Mistral-7B 相近,在中文、数学、代码能力表现更优,整体性能超越

七月论文审稿GPT第2.5和第3版:分别微调GPT3.5、Llama2 13B以扩大对GPT4的优势
前言 自去年7月份我带队成立大模型项目团队以来,我司至今已有5个项目组,其中 第一个项目组的AIGC模特生成系统已经上线在七月官网第二项目组的论文审稿GPT则将在今年3 4月份对外上线发布第三项目组的RAG知识库问答第1版则在春节之前已就绪至于第四、第五项目组的大模型机器人、Agent则正在迭代中 所有项目均为会对外上线发布的商用项目,而论文审稿GPT至今在过去的半年已经迭代两个版本,其中第
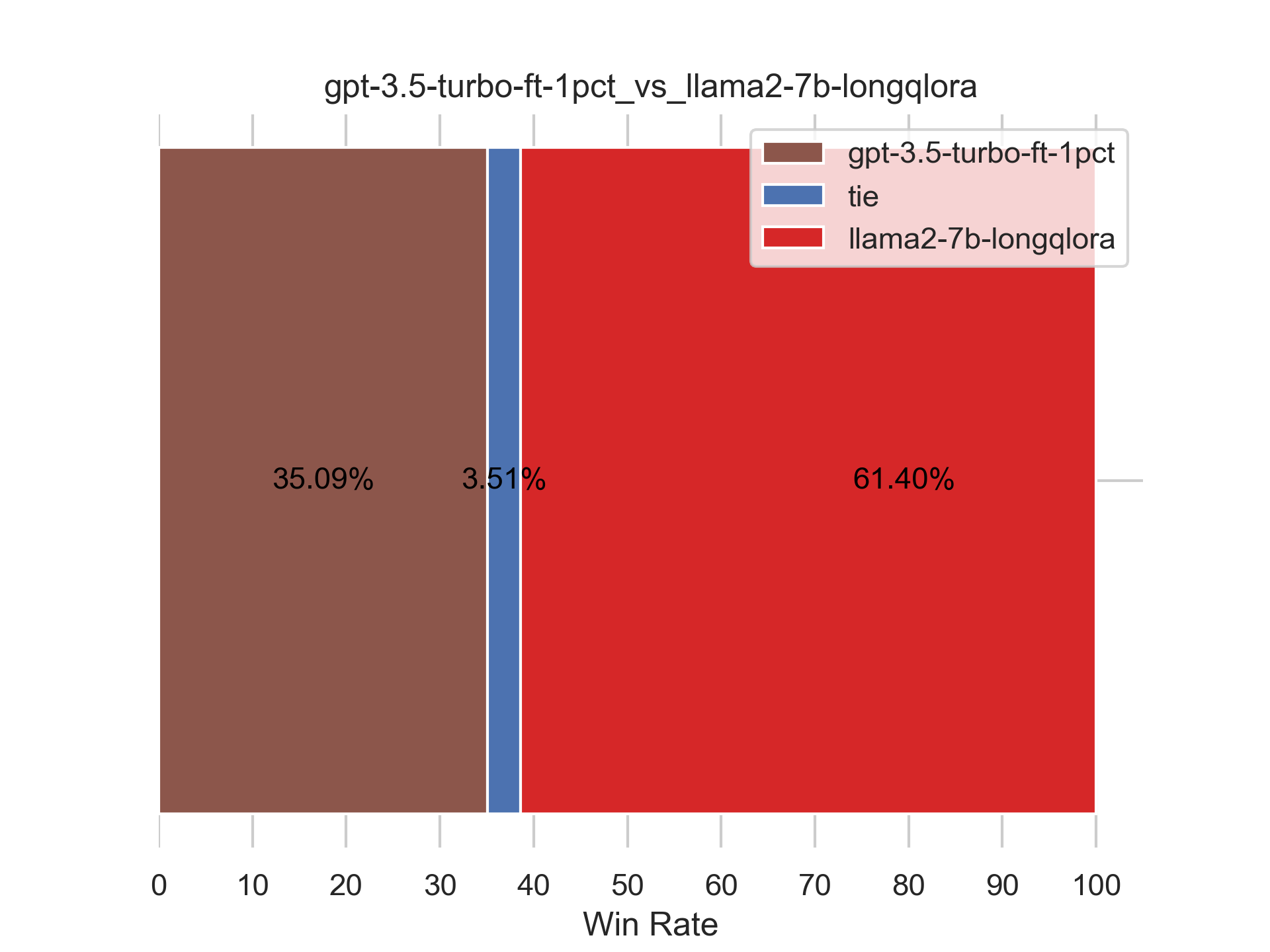
七月论文审稿GPT第2.5和第3版:分别微调GPT3.5、Llama2 13B以扩大对GPT4的优势
前言 自去年7月份我带队成立大模型项目团队以来,我司至今已有5个项目组,其中 第一个项目组的AIGC模特生成系统已经上线在七月官网第二项目组的论文审稿GPT则将在今年3 4月份对外上线发布第三项目组的RAG知识库问答第1版则在春节之前已就绪至于第四、第五项目组的大模型机器人、Agent则正在迭代中 所有项目均为会对外上线发布的商用项目,而论文审稿GPT至今在过去的半年已经迭代两个版本,其中第
七月论文审稿GPT第2.5版:微调GPT3.5 turbo 16K和llama2 13B以扩大对GPT4的优势
前言 自去年7月份我带队成立大模型项目团队以来,我司至今已有5个项目组,其中 第一个项目组的AIGC模特生成系统已经上线在七月官网第二项目组的论文审稿GPT则将在今年3 4月份对外上线发布第三项目组的RAG知识库问答第1版则在春节之前已就绪至于第四、第五项目组的大模型机器人、Agent则正在迭代中 所有项目均为会对外上线发布的商用项目,而论文审稿GPT至今在过去的半年已经迭代两个版本,其中第

浙大发布Agent学习框架,13B 模型达到 ChatGPT 水平!
2023 年下半年,AI Agent 正式开启「大模型下半场」。 自“人工智能”这门学科创立之初,一种可以“观察世界”-“思考推理”-“做出行动”-“反思学习”的人造代理就是构建通用人工智能的终极目标之一。而基于大模型的 AI Agent 借助大模型强大的推理判断能力,为 AI Agent 的发展开启了一扇新的大门。 以 LangChain 的底层思想 ReACT 为例,大模型 Age
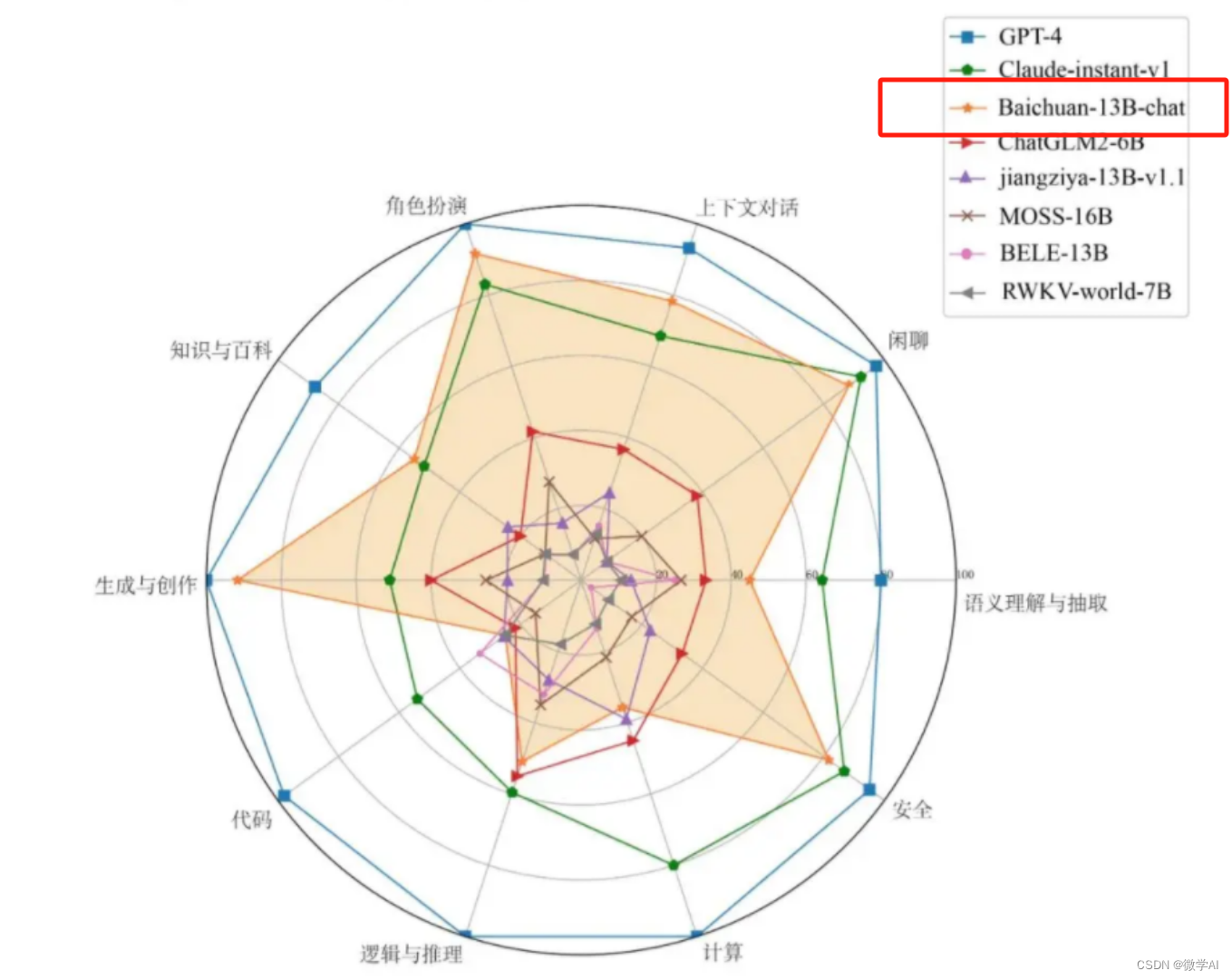
大模型的实践应用5-百川大模型(Baichuan-13B)的模型搭建与模型代码详细介绍,以及快速使用方法
大家好,我是微学AI,今天给大家介绍一下大模型的实践应用5-百川大模型(Baichuan-13B)的模型搭建与模型代码详细介绍,以及快速使用方法。 Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。本次发布包含有预训练 (Baichuan-13B-Base)