本文主要是介绍【数据可视化-02】Seaborn图形实战宝典,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Seaborn介绍
Seaborn是一个基于Python的数据可视化库,它建立在matplotlib的基础之上,为统计数据的可视化提供了高级接口。Seaborn通过简洁美观的默认样式和绘图类型,使数据可视化变得更加简单和直观。它特别适用于那些想要创建具有吸引力且信息丰富的统计图形的数据科学家和数据分析师。
Seaborn的主要特点包括:
- 集成性:Seaborn与pandas数据结构紧密结合,使得数据分析和可视化可以无缝衔接。
- 美观性:Seaborn提供了精心设计的默认样式和调色板,使得图形更具吸引力。
- 统计绘图:Seaborn提供了多种统计图形,如箱线图、小提琴图、热力图等,这些图形可以直观地展示数据的分布和关系。
- 数据分布可视化:通过核密度估计(KDE)和联合图(jointplot)等工具,Seaborn可以方便地展示数据的分布和相关性。
- 高度可定制性:虽然Seaborn提供了美观的默认样式,但用户仍然可以轻松地调整图形的各个方面,以满足特定的需求。
seaborn官方给出为了常用图形的案列,具体参看seaborn官方示例文档
Seaborn是一个基于matplotlib的数据可视化Python库,它提供了一种高级界面,用于绘制有吸引力的统计图形。下面是一些使用Seaborn绘制常见图形的示例:
因为seaborn并是一个绘图库,它与DataFrame对象有很好的集成。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
sns.set(style="white",font_scale=1.5)
sns.set(rc={"axes.facecolor":"#FFFAF0","figure.facecolor":"#FFFAF0"})
sns.set_context("poster",font_scale = .7)
import warnings
warnings.filterwarnings('ignore')
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 指定默认字体:解决plot不能显示中文问题
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题pd.set_option("display.max.columns",None)iris = sns.load_dataset('iris')
tips = sns.load_dataset('tips')
titanic = sns.load_dataset('titanic')
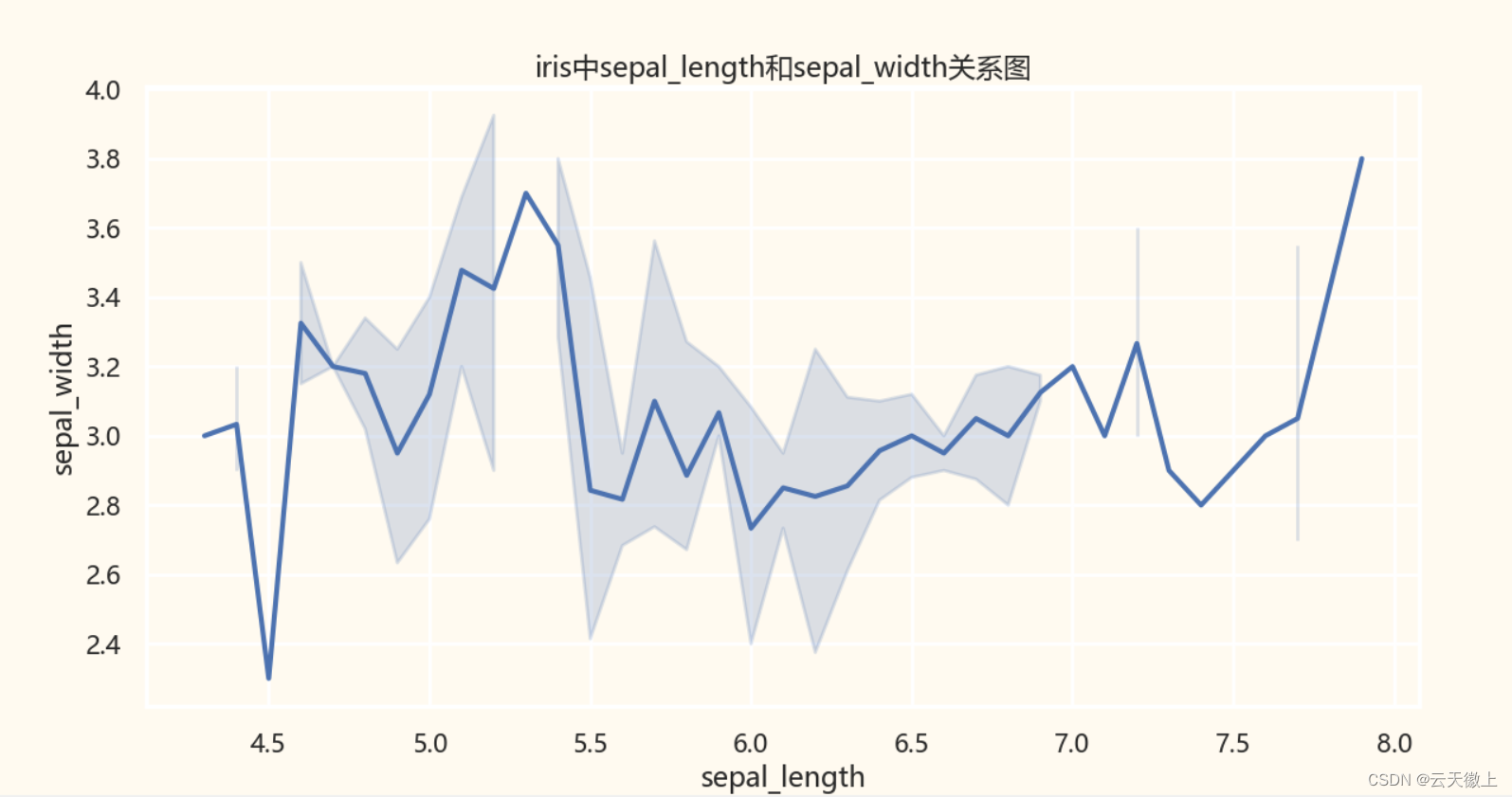
一、 折线图 (Line Plot) lineplot线型图
sns.lineplot(x='sepal_length',y='sepal_width',data=iris)
plt.title("iris中sepal_length和sepal_width关系图")
#进行分组
sns.lineplot(x='sepal_length',y='sepal_width',data=iris,hue='species')
#按性别分组
sns.lineplot(x='total_bill',y='tip',data=tips,hue='sex')# style = 'time'
sns.lineplot(x='total_bill',y='tip',data=tips,hue='sex',size='smoker',style='time')
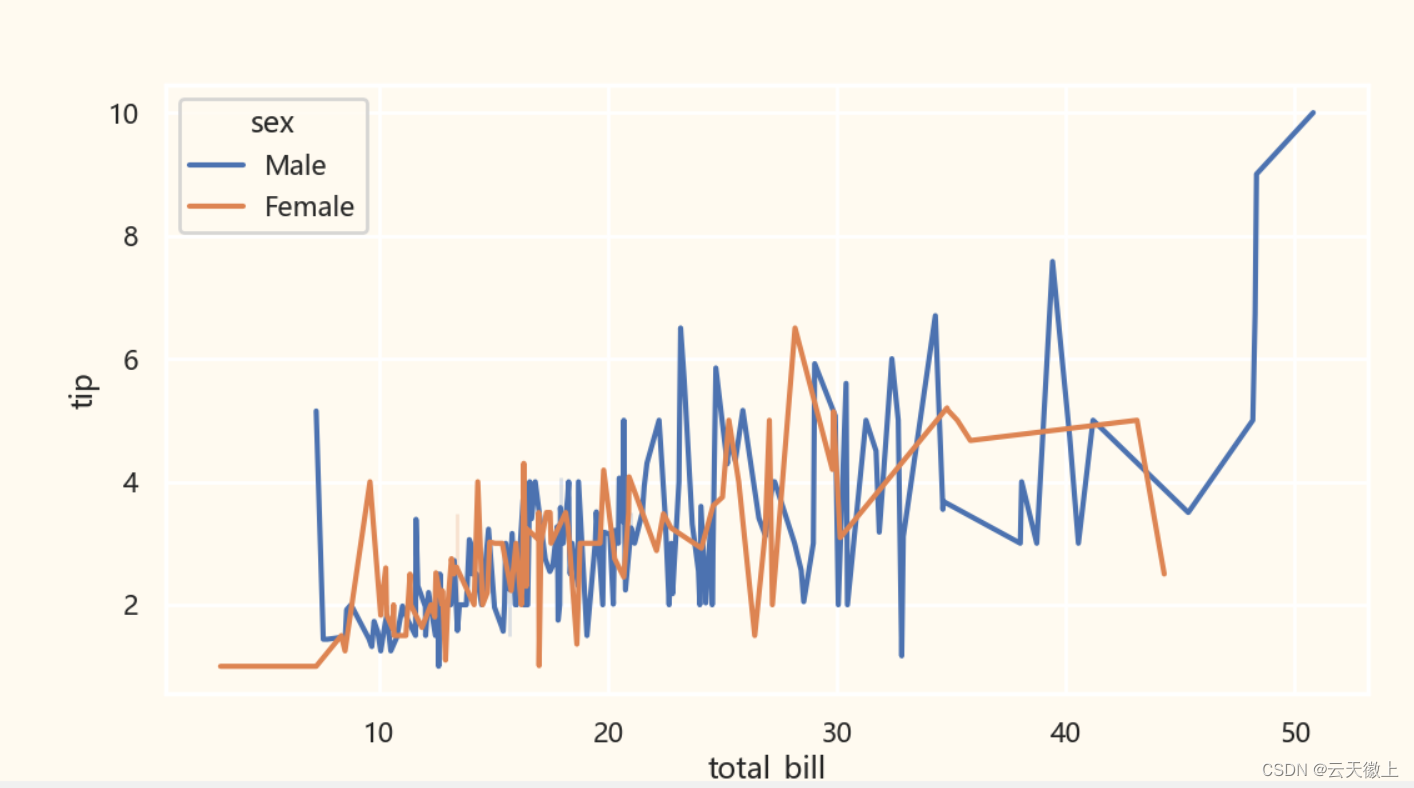
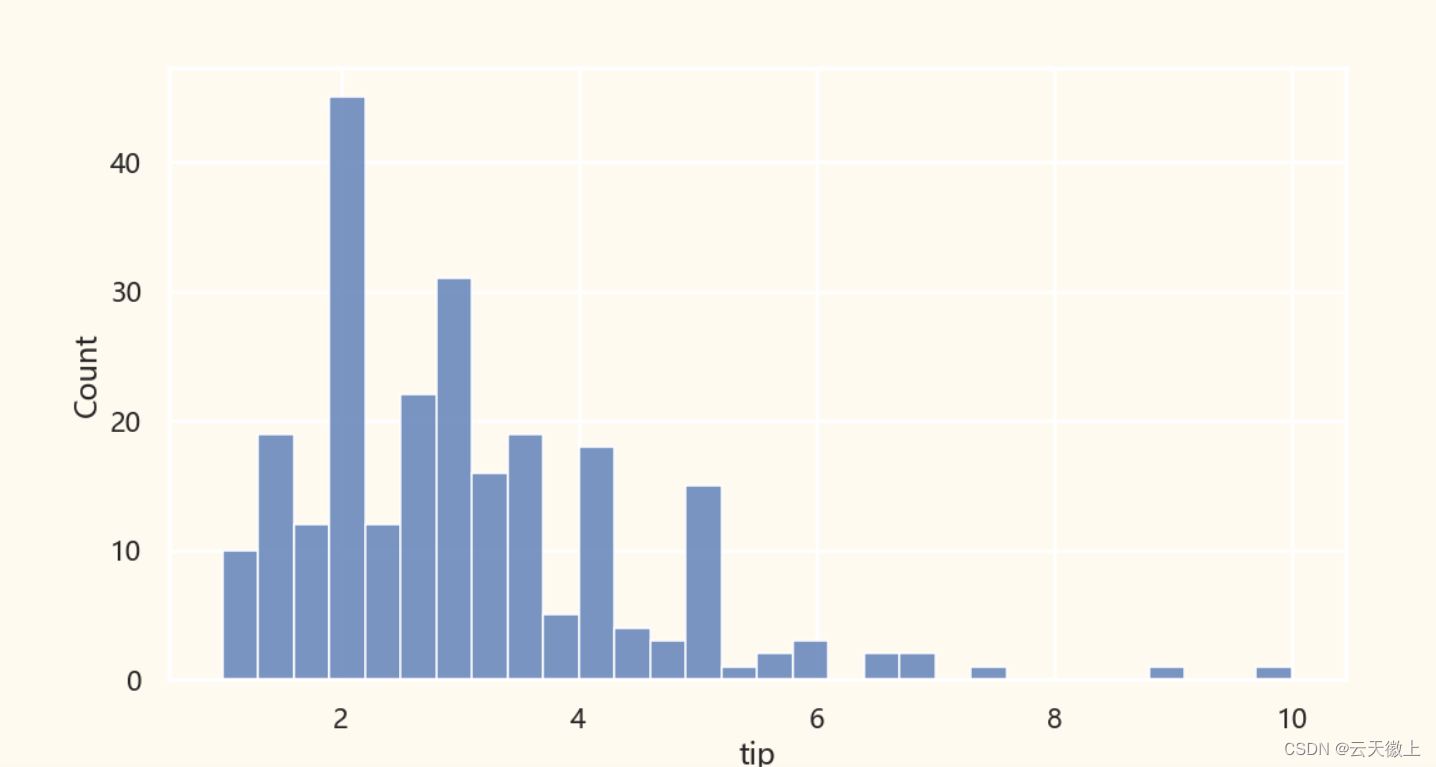
二、 直方图 (Histogram)
histplot和displot在显示一个维度时,效果时一致的;
# 使用Seaborn绘制直方图
sns.histplot(tips['tip'], bins=30)#kde 是否显示数据分布曲线 默认值是False
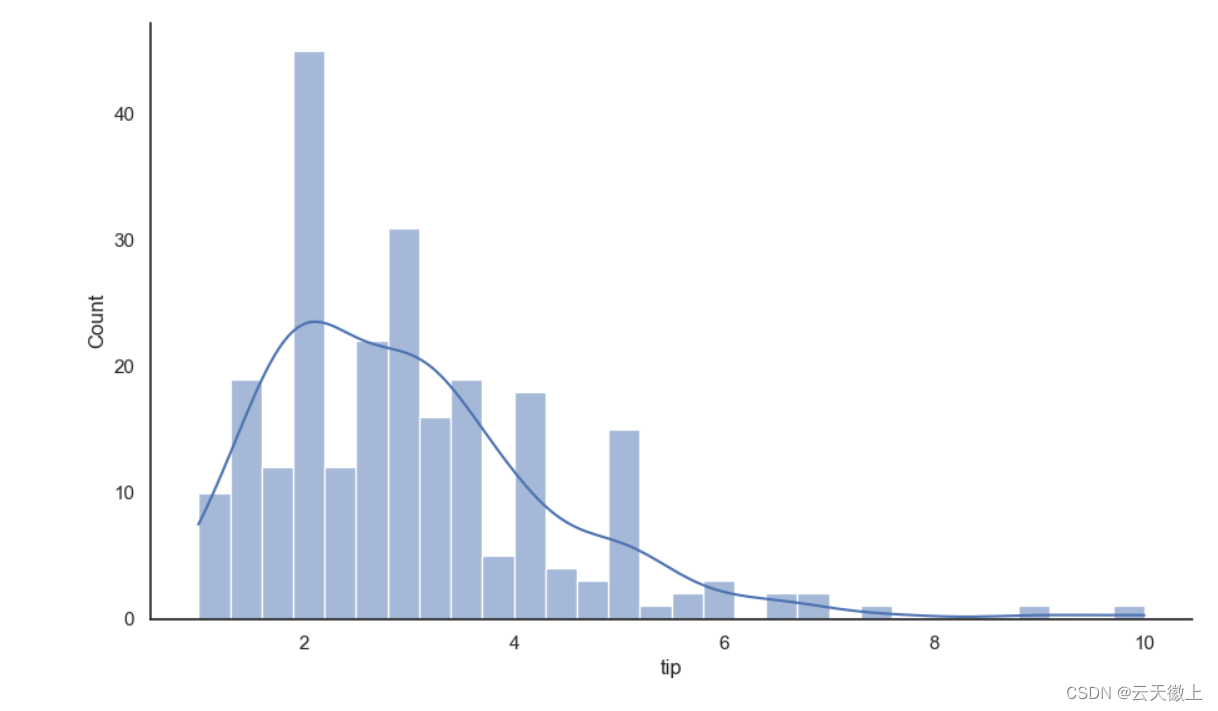
#设置风格样式
sns.set(style='white')
sns.displot(tips['tip'],bins=30,kde=True)
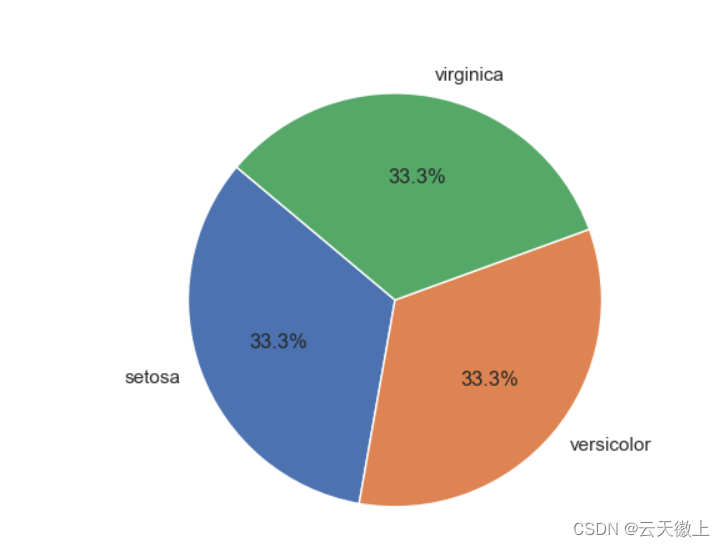
三、 饼图 (Pie Chart)
虽然Seaborn没有直接的饼图函数,但你可以使用matplotlib来绘制:
# 计算每个类别的百分比
sizes = iris['species'].value_counts(normalize=True) * 100
labels = sizes.index# 使用matplotlib绘制饼图
plt.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=140)
plt.axis('equal') # 确保饼图是圆的
plt.show()
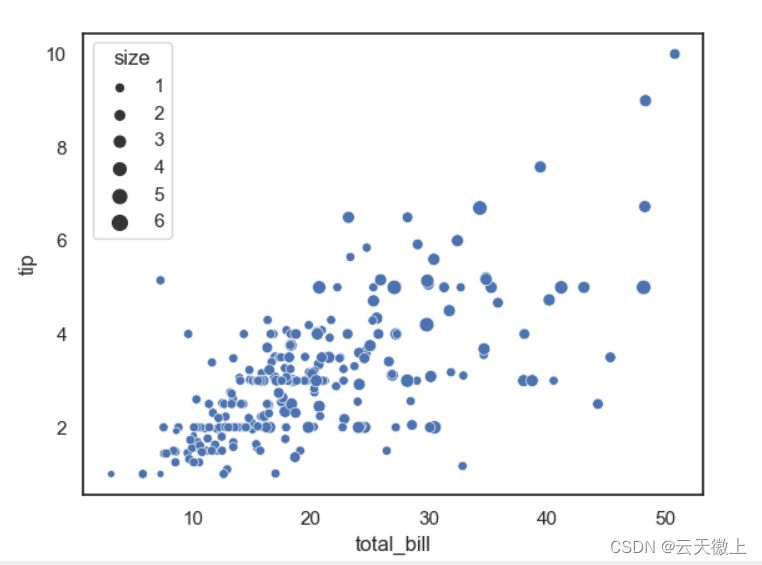
四、 散点图 (Scatter Plot)
sns.scatterplot(data=tips,x='total_bill',y='tip')
#size参数指定点的大小
sns.scatterplot(data=tips,x='total_bill',y='tip',size='size')
#hue 按是否吸烟进行分组
sns.scatterplot(data=tips,x='total_bill',y='tip',size='size',hue='smoker')
#保存图片
from matplotlib import pyplot as plt
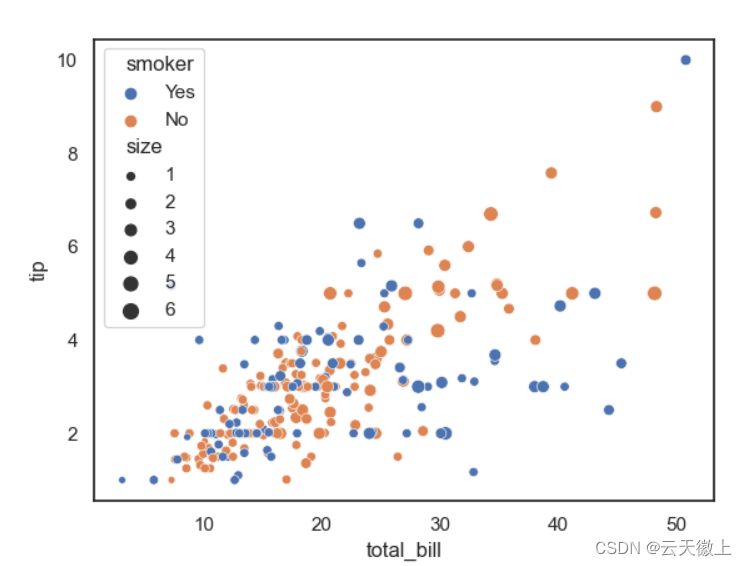
sns.scatterplot(data=tips,x='total_bill',y='tip',size='size',hue='smoker',style='time')
plt.savefig('scatterplot.jpg')
五、 柱状图/条形图barplot 堆叠柱状图 (Stacked Bar Chart)
# 使用Seaborn绘制柱状图
#绘制条形图 barplot
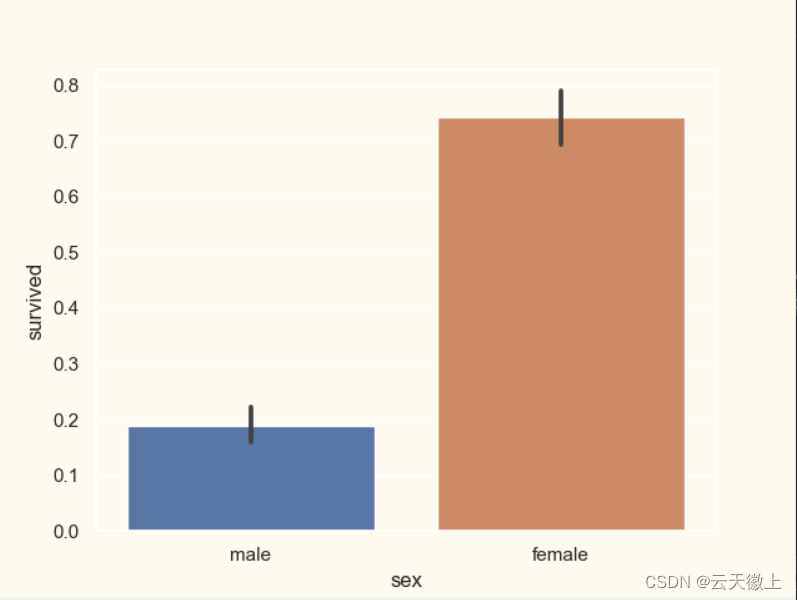
sns.barplot(x='sex',y='survived',data=titanic)
#按船舱分组
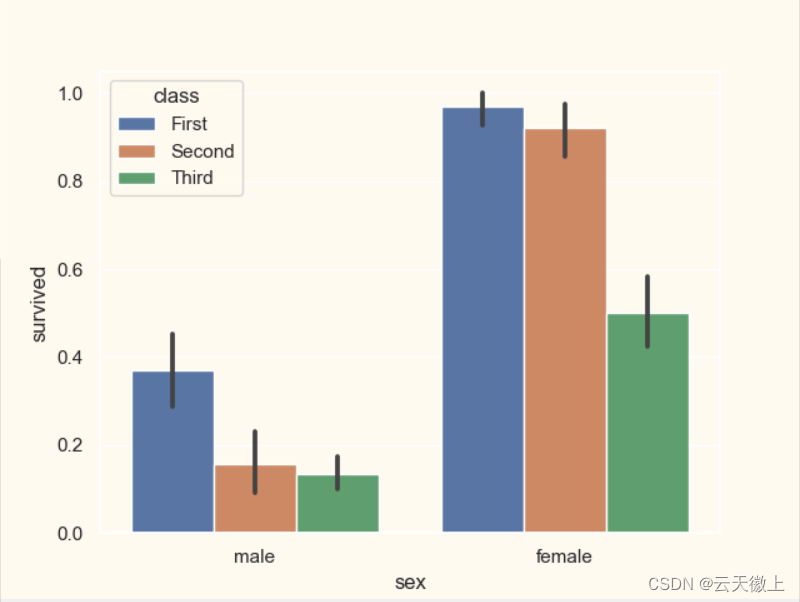
sns.barplot(x='sex',y='survived',data=titanic,hue='class')**sns.barplot(data=df, x='category', y='value')
plt.show()
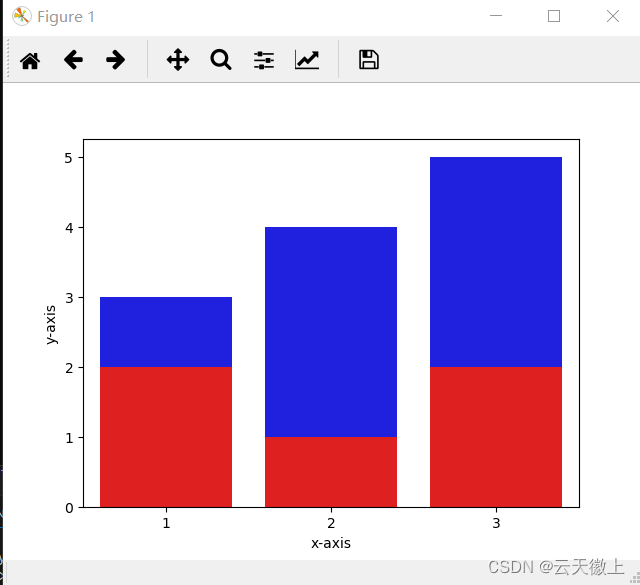
# importing all required librariesimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as plt# creating dataframedf = pd.DataFrame({'X': [1, 2, 3],'Y': [3, 4, 5],'Z': [2, 1, 2]})# creating subplotsax = plt.subplots()# plotting columnsax = sns.barplot(x=df["X"], y=df["Y"], color='b')ax = sns.barplot(x=df["X"], y=df["Z"], color='r')# renaming the axesax.set(xlabel="x-axis", ylabel="y-axis")# visualizing illustrationplt.show()
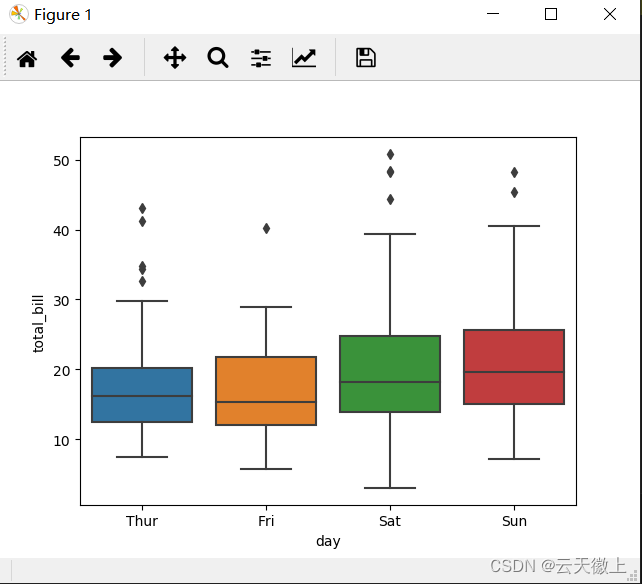
六、 箱形图 (Box Plot)
#绘制盒图 boxplot
sns.boxplot(x='day',y='total_bill',data=tips)
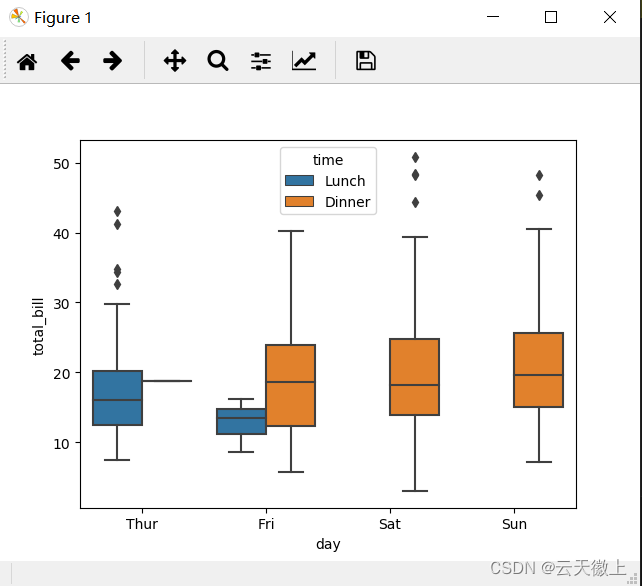
#按时间time分组
sns.boxplot(x='day',y='total_bill',data=tips,hue='time')
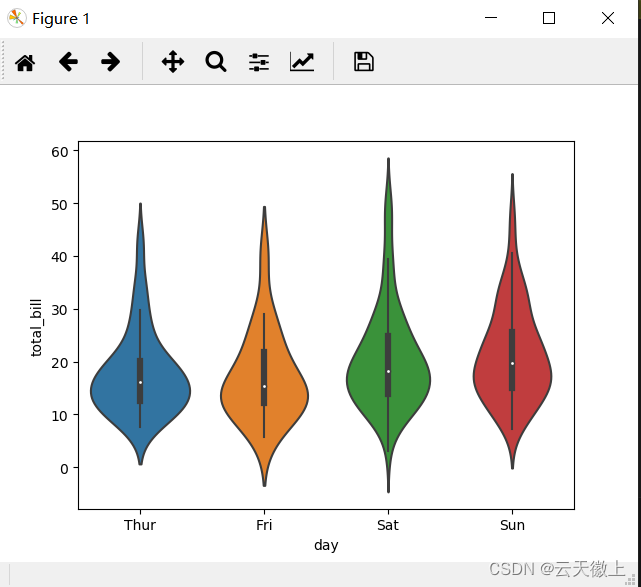
七、 小提琴图 (Violin Plot)
小提琴图是箱图和密度图的一种结合图形。左右越宽代表当前数据 量越密集。
sns.violinplot(x='day',y='total_bill',data=tips)
#按性别分组
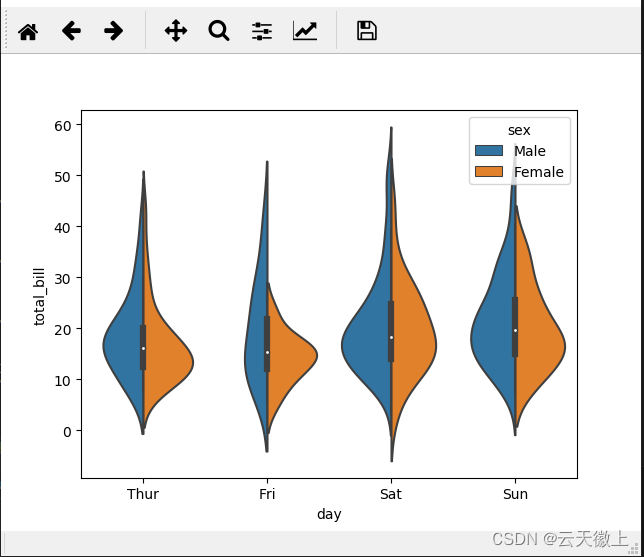
sns.violinplot(x='day',y='total_bill',data=tips,hue='sex')
#男生女生合到一块
sns.violinplot(x='day',y='total_bill',data=tips,hue='sex',split=True)
#去掉中间线
sns.violinplot(x='day',y='total_bill',data=tips,hue='sex',split=True,inner=None)
八、 ** stripplot(分布散点图)**
#绘制分布散点图 stripplot()
sns.stripplot(x='day',y='total_bill',data=tips)
#jitter 震动 默认是True
sns.stripplot(x='day',y='total_bill',data=tips,jitter=False)
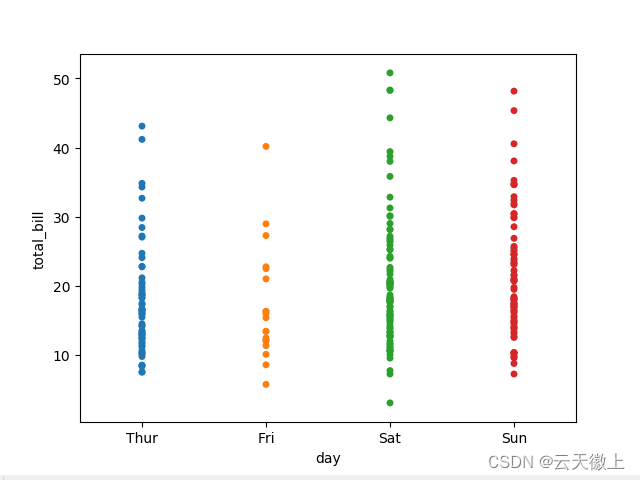
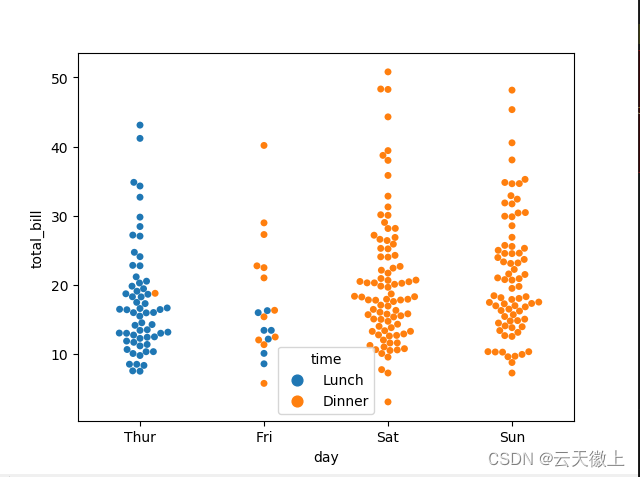
九、 swarmplot(分簇散点图)
sns.swarmplot(x='day',y='total_bill',data=tips)
#按性别分组
sns.swarmplot(x='day',y='total_bill',data=tips,hue='sex')
#按时间分组
sns.swarmplot(x='day',y='total_bill',data=tips,hue='time')
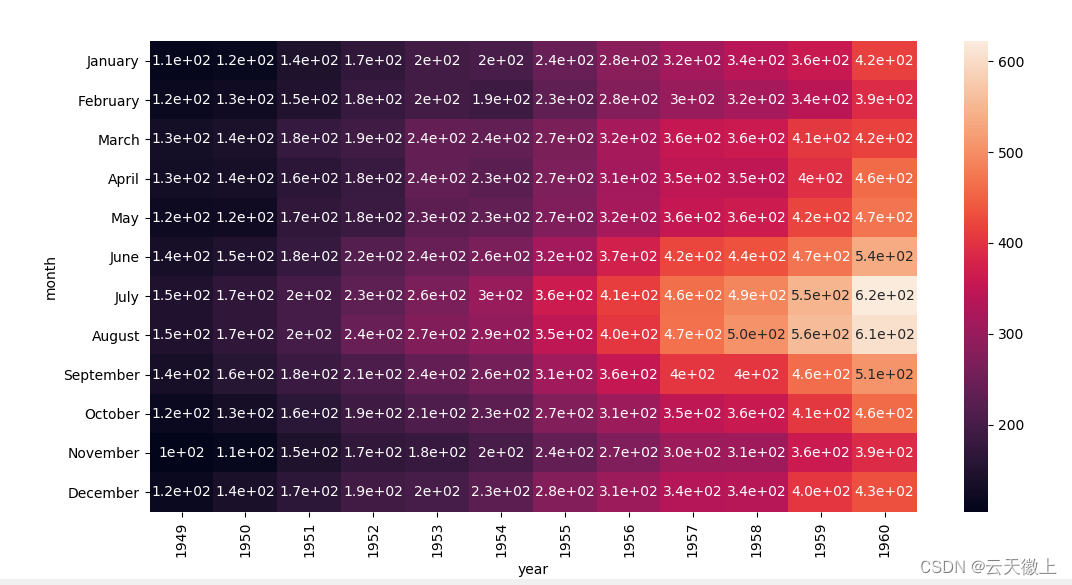
十、 热力图 (Heatmap)
热力图(heatmap)是以矩阵的形式表示,数据值在图形中以颜色 的深浅来表示数量的多少,并可以快速到到大值的与最小值所在位 置。在机器学习的分类中经常用来作混淆矩阵的比较。
#导入模块
import numpy as np
import seaborn as sns
#加载航班数据
flights = sns.load_dataset('flights')
#pivot 是DataFrame中的一个函数
data = flights.pivot('month','year','passengers')
#绘制热力图
sns.heatmap(data=data)
#参数 annot :True
sns.heatmap(data=data,annot=True)
#以整数的形式显示
sns.heatmap(data=data,annot=True,fmt='d')
#去掉右侧图例
sns.heatmap(data=data,annot=True,fmt='d',linewidths=0.5,cbar=False)
#修改色系
sns.heatmap(data=data,annot=True,fmt='d',linewidths=0.5,cbar=False,cmap='YlGnBu')
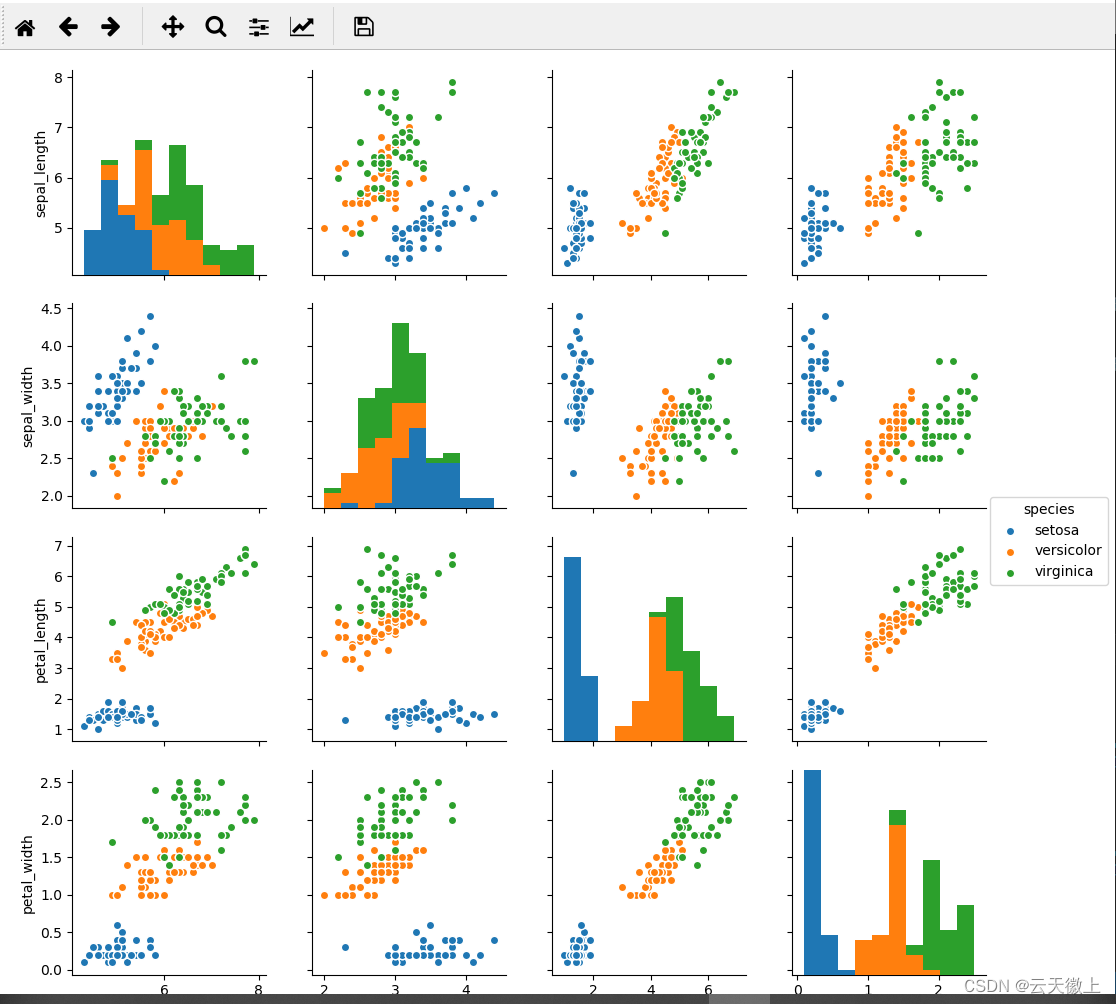
十一、 配对图 (Pair Plot)
import seaborn as sns
import matplotlib.pyplot as pltdf = sns.load_dataset('iris')# 绘制配对图
sns.pairplot(df, hue='species')
plt.show()
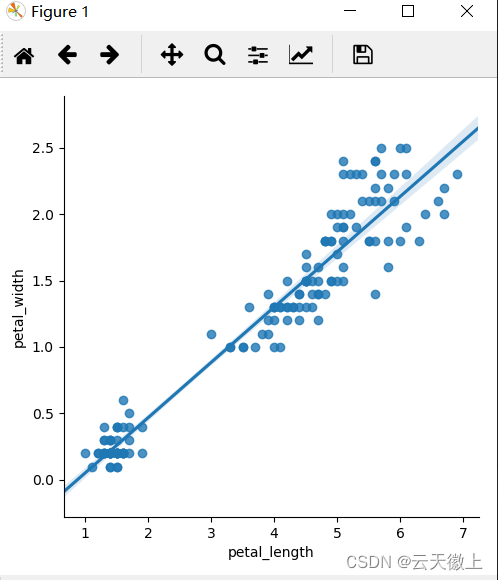
十二、 回归分析图
线性回归图通过大量数据找到模型拟合线性回归线。
#lmplot()
sns.lmplot(data=iris,x='petal_length',y='petal_width')
#regplot()
sns.regplot(data=iris,x='petal_length',y='petal_width')
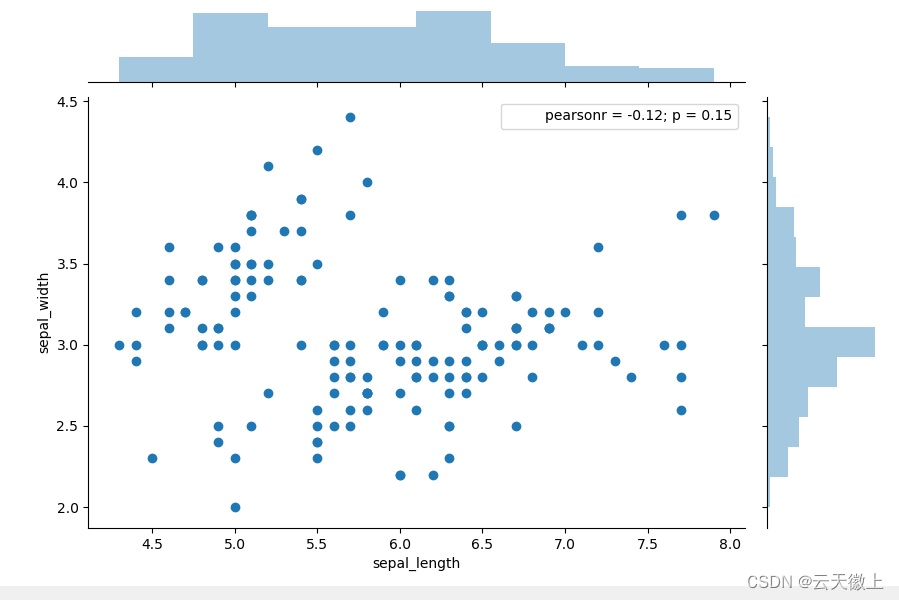
十三、 jointplot
joint意为联合,顾名思义jointplot是一个双变量分布图表接口。绘图结果主要有三部分:绘图主体用于表达两个变量对应的散点图分布,在其上侧和右侧分别体现2个变量的直方图分布
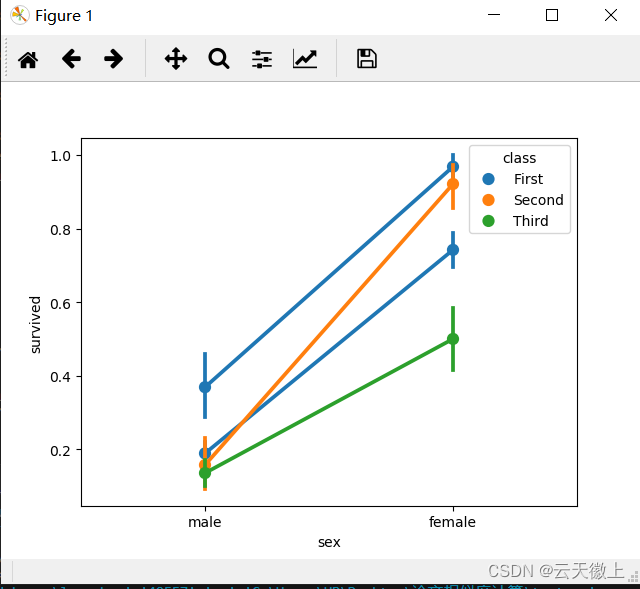
十四、 pointplot点图
#加载模块
import seaborn as sns
#加载数据
titanic = sns.load_dataset('titanic')
#绘制点图
sns.pointplot(data=titanic,x='sex',y='survived')
#hue 进行分组
sns.pointplot(data=titanic,x='sex',y='survived',hue='class')
Seaborn总结
Seaborn是一个功能强大且易于使用的数据可视化库,它特别适合数据科学家和数据分析师使用。通过Seaborn,用户可以轻松创建各种统计图形,以直观地展示数据的分布、关系和趋势。Seaborn与pandas的紧密结合使得数据分析和可视化可以无缝衔接,从而提高了工作效率。
此外,Seaborn的默认样式和调色板使得图形更具吸引力,同时也提供了高度的可定制性,用户可以根据需要调整图形的各个方面。这些特点使得Seaborn成为数据可视化领域的佼佼者之一。
然而,需要注意的是,虽然Seaborn提供了许多高级功能,但它仍然是基于matplotlib构建的。因此,对于想要深入了解数据可视化底层原理的用户来说,掌握matplotlib仍然是非常重要的。同时,Seaborn的某些高级功能可能需要一定的统计学知识才能充分理解和使用。
总之,Seaborn是一个强大而易于使用的数据可视化库,它可以帮助用户轻松地创建各种统计图形,以直观地展示数据的分布、关系和趋势。无论是数据科学家还是数据分析师,都应该掌握Seaborn的基本用法和高级功能,以提高数据分析和可视化的效率和质量。
这篇关于【数据可视化-02】Seaborn图形实战宝典的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









