本文主要是介绍(论文阅读-多目标优化器)Multi-Objective Parametric Query Optimization,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
摘要
一、简介
1.1 State-of-the-Art
1.2 贡献和大纲
二、定义
三、相关工作
四、问题分析
4.1 分析
4.2 算法设计影响
五、通用算法
5.1 算法概述
5.2 完备性证明
六、分段线性代价函数算法
6.1 数据结构
6.2 基本运算实现
6.3 复杂度分析
七、实验评估
八、总结
摘要
经典查询优化根据一个成本度量cost metric来比较查询计划,并将每个计划与一个固定的成本值关联起来。在本文中,我们引入了多目标参数查询优化(Multi-Objective Parametric Query, MPQ)问题,该问题根据多个成本度量比较查询计划,并将给定计划在指定度量上的成本建模为一个依赖于多个参数的函数。例如,一个实例的成本指标可以包括执行时间或货币费用;参数可以表示在优化时未指定的查询谓词的选择性。
MPQ对参数查询优化(允许多个参数,但只允许一个代价度量),和多目标客观查询优化(允许多个代价度量,但不允许参数)进行了泛化。我们正式地分析了新的MPQ问题,并说明了现有算法不适用的原因。提出了一种基于分段线性计划代价函数的广义MPQ算法和一种专门的MPQ算法。我们证明了两种算法都能找到所有相关的查询计划,并通过实验评估了我们的第二种算法在云计算场景中的性能。
一、简介
经典查询优化(Classical Query Optimization, CQ)将查询计划的代价建模为标量代价值c∈R。优化的目标是找到给定查询的代价最小的计划。多目标查询优化(MQ)[14,22,31]将经典模型泛化,并根据多个成本度量将每个查询计划与描述该计划成本的成本向量c∈Rn关联起来。优化目标是找到一组都是帕累托最优的查询计划,这意味着根据所有成本度量,没有其他计划在同一时间具有更好的成本。参数化查询优化(PQ)[13,17,7]以不同的方式泛化了经典模型,并将每个查询计划与代价函数c: Rn→R联系起来,将计划的代价描述为优化时值未知的多个参数的函数。
MPQ同时泛化并统一了MQ和PQ cost model,通过将一个查询计划的cost用一个向量值函数c:Rn -> R来表示。这允许了对于多参数和多个cost metrics进行建模,以下场景进行了具体说明。
场景1:云提供商允许用户通过Web界面查询大型科学数据集。查询处理发生在云端。用户通过类似 SELECT * FROM Table1 WHERE P1 AND P2的模板查询,P1和P2代表了未指定的谓词;用户通过在web交互界面上指定这些谓词来提交查询。云端的查询处理时间通常在接受更高计费的时候可以缩短。因此,在提交查询之后,用户可以看到执行时间和费用之间可能的权衡(通过可选查询计划实现),并可以选择他们喜欢的tradeoff。为了加速这个过程,云服务商会在预处理阶段为每个查询模板计算所有相关的查询计划。谓词的选择性在预处理阶段时是未知的,必须表示为参数,执行时间和费用是两个cost metircs。如果一个查询计划在参数空间中至少有一个点,在这个点上它的时间-费用权衡是帕累托最优的,这意味着没有一个备选计划能同时具备更低的费用和更低的处理时间,这也说明了这个查询计划是相关的。图1说明了此场景中的预处理结果(对于2个未指定谓词的场景)。
场景2:嵌入式的SQL查询是PQ的一个经典用例。为了避免运行时的查询优化开销,对于给定的查询模板,所有潜在相关的查询计划都会被提前计算。参数会对未指定的谓词的选择性或是运行时的可用buffer空间进行建模。在传统设置中,执行时间是唯一的成本度量。在近似查询处理的上下文中,执行时间可以和结果精度进行权衡。在这种情况下,优化时必须同时考虑执行时间和结果精度两个指标。在运行时对最优查询计划的选择不仅基于具体的参数值,还基于确定结果精度和执行时间之间的最佳折衷的策略。例如,基于当前系统负载或特定调用的最小精度的要求。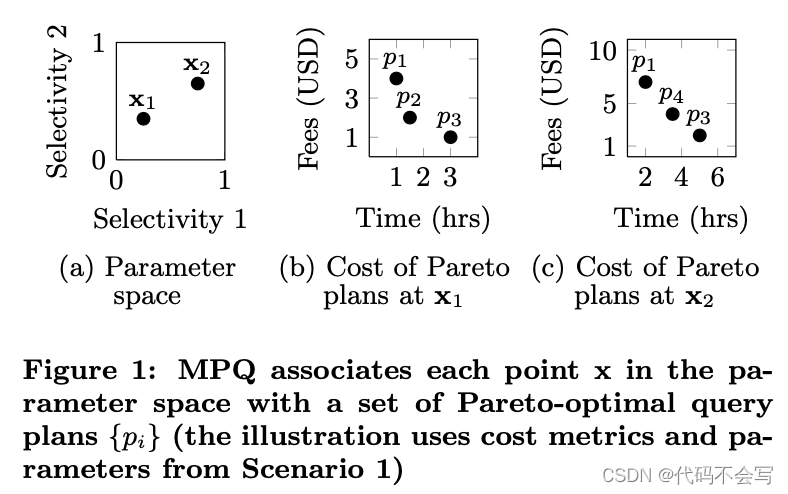
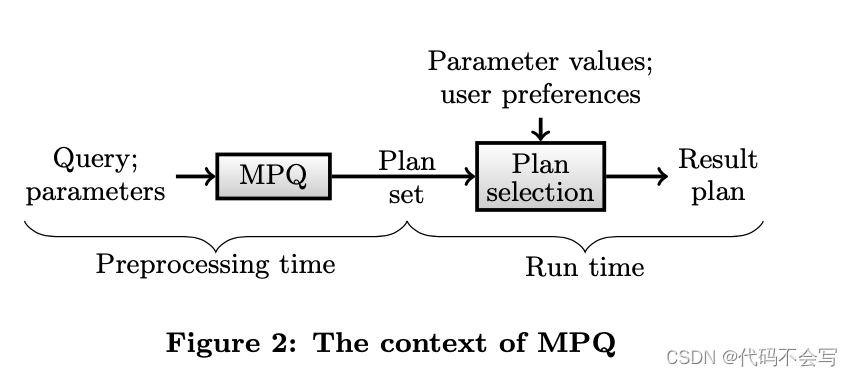
在上面的场景例子中描述的查询优化会去考虑多个参数和多个成本度量;这是一种新的查询优化,我们称之为MPQ。图2展示了MPQ的context:MPQ在运行之前发生,MPQ的输入是一个和参数相关的查询。参数可以标识影响查询计划成本且在优化时未知的任何数值。MPQ的目标是生成一组完成的相关方案,其含义是一个集合,该集合包含每个可能的执行计划p,和参数空间x中的每个点的方案p*,使得根据每个成本度量,p*的成本最多与p在x处的成本相同。它的目标是为参数空间中的所有点找到一组帕累托最优查询计划。与PQ一样,所有相关的查询计划都是预先生成的,因此在运行时不需要进行查询优化。
1.1 State-of-the-Art
MPQ是MQ和PQ的泛化。将现存的MQ或是PQ算法直接应用到MPQ上是不可能的,因为PQ算法只支持一个成本度量,而MQ算法不支持参数。乍一看,将成本度量建模作为参数似乎是可能的;如果除了一个成本度量之外其他所有的成本度量都可以表示为参数,那么PQ算法就可以应用。例如,当我们尝试将场景1中的费用作为参数来建模(这样执行时间就成为了谓词选择性和费用预算的函数),然而这样会导致以下问题:首先,现存的PQ算法通常会假设每个参数的值域是提前知道的。这对于谓词选择性或是可用的buffer空间来说是可以实现的,但对于费用来说却不是,因为为给定查询寻找最小执行费用本来就是一个硬优化问题。其次,成本度量和参数有不同的语义:例如,假设给定查询的备选查询计划的执行费用在1到10美元之间,定价为5美元的计划p的执行时间比所有收费较高的计划都要短。MPQ的结果集应该只包含p,而不包含更昂贵的计划,因为p总是比它们更可取。然而,PQ算法(如[13,17])会为每个可能的成本值在6到10美元之间生成执行时间最短的方案,因为经典PQ算法的目标是通过最优方案覆盖整个参数空间(而MPQ算法的目标不是覆盖整个成本空间)。PQ的结果集可以比MPQ的结果集大任意一个因数,结果集的大小与优化时间有关。由于参数域通常被假设为连通区间,而成本值可能在总成本范围内分布稀疏,因此会产生其他问题。总而言之,通过将成本度量作为参数建模,将MPQ问题转换为PQ问题似乎不合适。PQ算法的一个流行分支将PQ问题分解为多个非参数CQ问题;然而,不可能类比地将一个MPQ问题分解为多个非参数MQ问题,原因在第4节中概述。更多相关工作将在第3节中讨论。
1.2 贡献和大纲
在提供细节前,我们总结了我们的贡献,如下:
-
我们用分段线性(PWL)计划成本函数正式地分析了MPQ问题。我们特别指出,MPQ问题对于PQ问题的某些基本性质没有等价的内容,这些基本性质启发了基于参数空间分解的一类广泛的PQ算法的设计。
-
我们提出了MPQ的第一个算法;这些算法可以同时处理多个成本度量和参数化的成本函数。我们提出了一个通用的MPQ算法,可以处理任意的计划成本函数,以及一个专有化的PWL成本函数。
-
我们对我们的算法进行了正式的分析,并表明这两种算法都保证生成所有相关的查询计划。我们在一个类似于例1中所介绍的示例场景中对PWL代价函数的算法进行了实验评估。
第二章介绍了正式的模型,第三章讨论了相关工作。我们再第四章分析了MPQ的问题并展示了它和PQ在几个重要方面的差异。第五章提出并分析了相关区域修剪算法(Relevance Region Pruning Algorithm, RRPA)。这是一种通用的MPQ算法,可以处理任意的计划成本函数。许多CQ、MQ和PQ的算法都是基于动态规划,为基础不断增加的join table set进行查询计划的生成和剪枝。这个修剪功能与之前的方法不同:每个查询计划都与与其相关的参数空间中的一个区域(相关区域,缩写为RR)相关联。在修剪过程中,通过与备选方案的比较,该区域不断缩小。一旦RR空了,计划就被砍掉了。我们证明了RRPA可以保证为任意查询生成所有相关的查询计划。
RRPA基础操作的实现,例如添加cost function,和对相关区域RPs进行交集,依赖于cost function的类型。PQ的大多数工作集中在线性的linear或是分段线性PWL的cost function,这种函数可以被有效地存储和计算。线性函数对实际执行计划的cost的近似通常不佳,而分段线性PWL函数可以对任意cost function进行任意程度的近似。因此我们将重点放在PWL cost function上,并提出了PWL-RRPA,一种针对于PWL function的特定相关区域修剪算法RRPA。在第六章,我们证明了在PWL-RRPA执行过程中的所有区域RRs都归属于一类有限的形状,并提出了一种数据结构来表示cost functions和RPs。我们提供了伪代码,用于在这些数据结构上有效地实现PWL-RRPA的所有基本操作,并分析了结果的复杂性。在云计算场景中对PWL-RRPA进行了实验评估;结果将在第7节中讨论。
二、定义
一个查询可以用一个需要被join的table集合Q来表示。一个查询计划指定了join的顺序和执行scan和join操作的算子。符号O代表可用的算子集合。假设p1和p2是两个对不相交的表集合执行join的执行计划,且o∈O,是一个join算子。函数Combine(p1, p2, o) 指定了将p1和p2的结果用算子o执行join的查询计划。p1和p2被称为最终执行计划的sub-plans。函数P(Q)代表查询Q的所有可能的执行计划。一个查询计划的执行cost依赖于参数,参数的具体值在查询优化阶段是未知的。参数代表查询执行时的谓词选择性或是可用的buffer空间数量。固定参数集合的参数值用一个向量x来表示。参数空间X是可能的参数向量的集合。查询计划根据一个cost metrics的集合M进行比较,这些cost metrics具有可用的分析成本模型。假设p是一个查询计划,x是一个参数向量。cost function c(p,x)确定了在参数向量x条件下的计划p的成本。cost function会输出一个向量c,它对于每个cost metric都具有一个值。假设m∈M,是一个cost metric,那么c^m代表这个metrc的cost value。符号c(p)为一个常量计划p指定了cost function,使得c(p)(x) := c(p, x)。
EXAMPLE 1:这个例子基于场景1.考虑一个查询模板,包含3个在运行时才能指定的谓词。这三个谓词的选择性是三个参数,每个参数的值域是一个连续空间[0,1]。这三个谓词的参数合在一起能被描述为一个三维vector(eg, x = (0.1, 0.5, 0.2),代表第一个谓词选择性是10%,第二个是50%,第三个是20%)。参数空间包含所有可能的参数向量,它是一个三维的空间X=[0,1]^3 ∈ R3。一个固定查询的cost依赖于谓词的选择性,且它基于2个cost metrics:执行时间和费用,因此M ={time, fees}。这两个cost metrics的值域分别都是一个集合R+∈R,其值为非负实数。一个确定集合p的cost function c(p)将三维参数向量映射为二维代价向量:c(p): X -> R2+。
执行计划中值越高越好的质量度量(例如,场景2中的结果精度)总是可以转换为值越低越好的成本度量(例如,将结果精度θ∈[0,1]替换为精度损失1-θ)。假设p1和p2是产生相同结果的2个查询计划。执行计划p1在参数空间的所有点上都优于执行计划p2,其中p1在每个成本度量上都不高于p2。函数Dom(p1,p2)⊆X会产生p1优于p2的参数空间域:
Dom(p1,p2) = {x ∈ X|∀m ∈ M : cm(p1,x) ≤ cm(p2,x)}
计划p1和p2在其成本相当的参数空间区域内相互支配。 在参数空间的所有点上,计划p1严格支配计划p2,在这些点上,p1支配p2而不具有等价成本。 函数StD(p1, p2)⊆Dom(p1, p2)得出p1严格支配p2的参数空间区域。
StD(p1, p2) = Dom(p1, p2) \ {x ∈ X|c(p1, x) = c(p2, x)}
一个执行计划在PQ中的最优区域是,在该区域中没有其他方案的代价更低。与多目标最优区域相似的是帕累托区域。执行计划p的帕累托区域pReg(p) ⊆ X即为满足参数空间区域中,没有P(Q)中的其他执行计划可以在和p产出同样结果的前提下优于p:

参数化最优执行计划集合是在PQ中,包含至少一个在参数空间各个点上最优的执行计划的执行计划集合。(到底是一个计划只需要在一个点上最优,还是必须在各个点都是最优???)多目标模拟是一个帕累托计划集(PPS); 如果一个集合P⊆ P(Q) ,如果它满足对于每一个可能的执行计划p*∈ P(Q)和每一个参数向量x∈X,都包含至少一个执行计划能基于x优于p*,那么我们称P为帕累托集合集PPS。
∀p∗ ∈P(Q)∀x∈X∃p∈P :x∈Dom(p,p∗)
EXAMPLE 2:假设p1、p2和p3是同一个查询的3个执行计划。假设只有一个参数σ ∈ [0, 1](X = [0,1]),它代表了一个未知谓词的选择率。需要考虑时间和费用两个成本度量:M={times, fess}。执行计划有如下的成本函数c-time(p1) = 2σ, c-fees(p1) = 3, c-time(p2) = 0.5+σ, c-fees(p2) = 2,p3的成本函数和p2相同。它们之间存在如下的关系:执行计划p2和p3在整个参数空间中互相支配:Dom(p2, p3) = Dom(p3, p2) = [0, 1]。执行计划p2在σ > 0.5时优于p1。p1的帕累托域为选择率区间[0, 0.5]。p1和p3的帕累托域是整个参数空间。{p1, p2}和{p2, p3}都可以组成一个PPS。
帕累托计划指PPS中的一个计划。PPS中的相关映射(RM) P将每个帕累托计划映射到参数空间中的相关区域(RR),这样当我们需要为参数空间点x∈x找到最佳方案时,我们可以将注意力限制在相关区域RR包含x的计划上:
∀p∗ ∈P(Q)∀x∈X∃p∈P :x∈relM(p)∩Dom(p,p∗)
一个执行计划的相关区域RR和它的帕累托域可能是不同的。Section 5中提出的算法使用了相关映射RMs,并忽略了一些具有空的相关区域RRs的执行计划。多目标参数查询优化(MPQ)问题是本文研究的重点。一个MPQ问题,被一个查询Q、一个参数空间X和一组成本度量M共同定义。Q的任一个PPS都是MPQ问题的一个解。
我们引入了MPQ的一个受限变量,下面的定义是先决条件。一个m维凸多面体是Rm中的点的集合,其中:i) 是凸的,也就是说凸多面体中的任意两点由一条完全位于凸多面体内的线段连接;ii) 对应于一个有限的半空间集合的交集,一个半空间是

形式的线性不等式的解的集合,w,x∈Rm和b∈R。Figure3展示了一个凸多面体是如何有3个R2的半空间构成的。一个执行计划的代价函数c(p,x)在整个参数空间内是线性的,前提是如果对于每一个代价度量m∈M,有一个权重向量Wm和一个常量bm∈R,使得对每一个x∈X,都有

。如果参数空间可以被分为多个凸多面体,c(p,x)在每个多面体中都是线性的,那么这个代价函数是分段线性PWL的。PWL函数具有很高的实际意义,因为它们可以近似任意的函数[18]。大多数关于PQ的工作(例如,[13,17])通过假设线性或PWL成本函数来限制PQ问题。与此类似,我们引入MPQ问题的一个限制性变体:PWL-MPQ假设所有向量值的成本函数都是PWL,并且参数空间本身形成一个凸多面体(这是PQ的一个标准假设[17])。第4节分析了PWL-MPQ问题,第6节介绍了一个相应的优化算法。该算法利用了PWL-MPQ中的参数空间可以被划分为计划集P的线性区域的特点:线性区域是参数空间中的一个凸多角形,P中的所有计划都有线性成本函数。
三、相关工作
我们在Section 1.1中介绍了4种不同的查询优化变体(CQ、PQ、MQ、MPQ),并论证了现有算法不能应用于MPQ的原因。现在我们来讨论PQ和MQ的相关工作的细节点。
PQ算法将查询计划和代价函数关联,而不是代价值。代价函数依赖于标识实例谓词选择性的参数。PQ中的目标通常是生成一个执行计划集合,其对每一个可能的参数值组合都包含一个最优计划。许多PQ中的工作是基于参数空间分解的。他们反复调用一个标准的优化器来生成固定参数值的最优计划(如果参数值是固定的,那么查询计划的成本又可以被建模为一个常量值),以便将参数空间分解为单个计划是最优的区域。我们可以在Section 4中看到为什么类似的方法在MPQ中失败。PQ算法的另一个分支是基于动态规划,类似于Selinger[26]的CQ算法。它们是专门针对PQ的,因为它们在修剪过程中只考虑一个成本度量(有些方法除了考虑执行时间外还考虑鲁棒性[4,1],但鲁棒性是直接从执行时间推导出来的,而不是一个独立的成本指标),并且使用数据结构和相应的操作函数,这些数据结构和函数是针对PQ而不是MPQ中的假设的(例如。许多PQ算法将计划最优的参数空间重新建模为凸多边形,这对具有PWL成本函数的PQ有效,但对具有PWL成本函数的MPQ无效,如第4节所示)。在MPQ场景中使用PQ算法要求对于一个成本度量来说的最优执行计划总是能保证对其他所有成本度量都是最优的。这种情况是不现实的;由于许多相关的成本指标是反相关的(例如,近似查询处理中的结果精度和处理时间[3]),更是如此。Ioannidis等人[19]对PQ使用了随机算法;他们不支持多种成本度量。与本文介绍的算法不同,随机算法不能为生成完整的计划集提供正式的最坏情况保证。经典的PQ通过生成所有可能相关的计划来处理未知的参数值。其他方法定义参数值的概率分布,目的是生成一个鲁棒性的计划[4,1]或一个最小化预期成本的计划[10]。与此相反,经典PQ的目标是在运行时出现新信息的场景,在选择计划时应考虑这些信息。
MQ算法将查询计划在多个成本度量上进行对比。目标是根据用户的偏好,找到一个代表冲突指标之间最佳折衷的计划。Selinger的单目标查询优化算法已被推广到MQ[14, 31]:在修剪过程中,根据多个成本指标对产生相同结果的计划进行比较,不符合帕累托最优的计划被丢弃。后一种方法可以处理广泛的成本度量,但不支持参数。其他的MQ算法是针对成本指标和用户偏好函数的特定组合而定制的,允许有效的修剪[21, 32, 2, 3]。他们只允许在成本指标中,将查询计划的成本计算为其子计划成本的加权和[32];然而,这在许多相关场景中是不可能的(例如,如果一个计划的执行时间等于其子计划的执行时间的最大值,如果它们是平行执行的)。这些方法都不支持参数。我们在本文中提出的算法只对成本度量进行了最小的限制(见第5.2节),并允许参数,这是解决MPQ问题所需要的。然而,MQ算法的另一个分支将多目标优化与join ordering分开;例如,它们首先产生一个时间最优的join tree,然后在该树中配置考虑多个成本指标的运算符[15, 24]。这样的方法不适用于MPQ,因为找到一个对所有参数值都最优的join tree是不现实的(诸如谓词选择性之类的参数显然对最优连接顺序有很大影响)。多目标数据流优化的算法[27, 28, 22]并不适用于有连接重排的查询优化。
四、问题分析
本章我们来分析新引入的MPQ问题。PQ问题(ie. 只有一个成本度量的MPQ问题)已经在前面的工作中被分析了。MPQ问题是PQ问题的泛化,因此下面的分析主要是指出PQ问题和MPQ问题之间的区别。我们将在Section 4.1中看到有多个成本度量,而不是一个,会改变许多基本问题属性。这对于我们将在Section 4.2中讨论的MPQ算法的设计有重大影响。
4.1 分析
大多数PQ的工作会假设成本函数是分段线性PWL的。我们在下面做相同的假设。我们在PQ和MPQ之间的比较主要集中在PQ所具有的三个问题属性上。这三个问题的属性已经被称为PQ的指导原则[12],因为许多PQ算法以这样或那样的方式利用它们[13, 17, 12],假设它们在整个参数空间[13, 17]或至少在宽泛的空间[12]中成立。我们将看到,这些指导原则对MPQ不再适用,这使得许多成功的PQ方法不适用于MPQ。表1总结了PQ和MPQ之间的区别。左边一栏包含Ganguly[13]所证明的关于PQ的陈述;右边一栏包含接下来要证明的关于MPQ的适应性陈述。所有的陈述都是指线性区域(参数空间中的凸多面体,其中所有比较的成本函数对每个成本度量都是线性的)。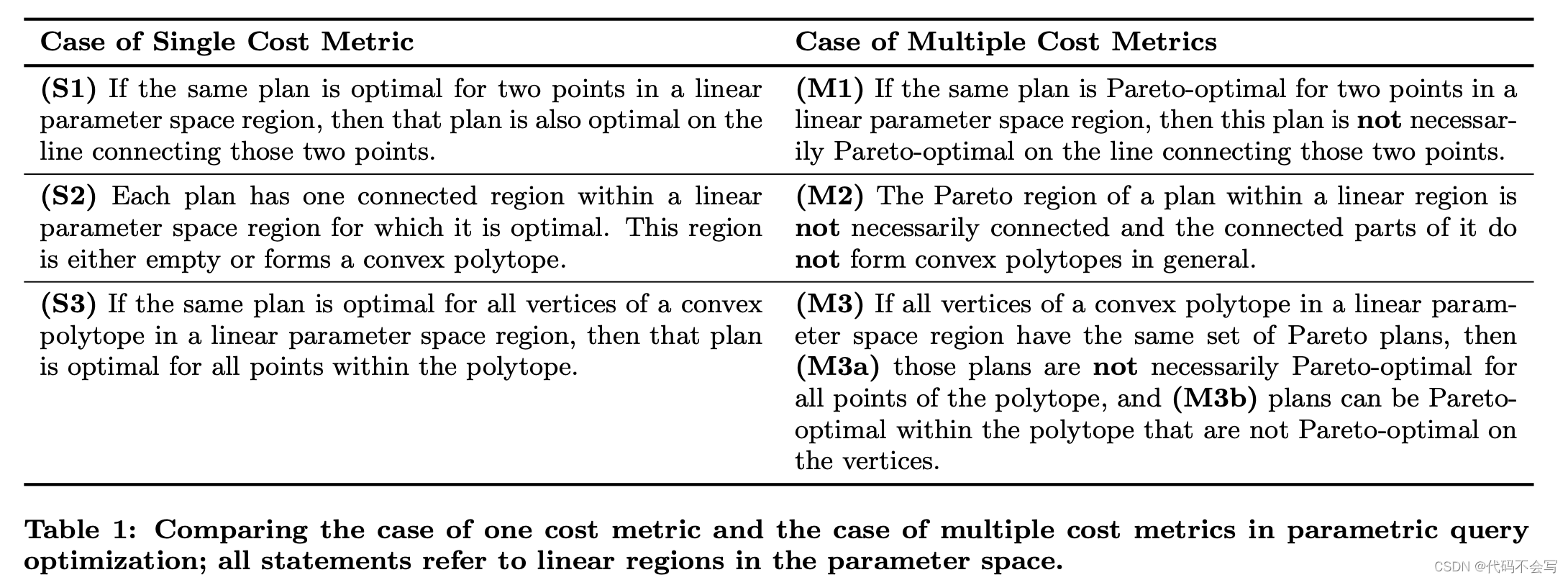
定理1:参数空间可以被划分成任意代价函数集的线性区域。
证明:根据PQ[17]的结果,只给定一个成本度量,参数空间总是可以被划分为线性区域。用Ci表示根据第i个成本度量进行的分区,1≤i≤M(表示为一组多角形)。那么{c = c1 ∩...∩cM|ci∈Ci}是根据所有成本度量将参数空间划分为线性区域。分区是凸多角形的交点,因此也是凸多角形本身。
我们在下文中用S1、S2和S3指代关于PQ的三个陈述,用M1、M2和M3指代关于MPQ的三个陈述。(见上方表1)
定理2:假设p1和p2是两个任意的计划,X⊆X是{p1,p2}的线性区域。那么,X内p1支配p2的区域D形成一个凸多边形。
证明:用Dm⊆X表示根据成本度量m∈M,其中p1比p2更好或相等的区域。每个区域Dm形成一个凸多角形(见关于具有线性成本函数的PQ的结果[13])。计划p1在其根据所有成本度量优于或等同于p2的区域中支配p2。因此,区域D对应于Dm的交点。D = ∩m∈MDm。凸形多面体是半平面的交点。因此,凸多面体的交点又是一个凸多面体。
下面的一系列反例证明了表1的陈述。最佳计划的多目标等价物是帕累托最优计划。关于PQ的陈述S1并不能推广到多目标的场景。Figure 4展示了对应的反例。该例子显示了一维参数空间内两个计划的二维成本函数。Plan1在整个参数空间(参数范围[0,3])内都是帕累托最优的。Plan2只在参数空间范围[0,1)和[2,3]内是帕累托最优的,在[1,2]范围中不是。这个例子对MPQ来说是最小的,因为少于两个成本指标会导致PQ,少于一个参数会导致MQ。因此,否定的结果适用于一般的MPQ。这个帕累托最优是怎么判断的???
这个例子同时表明,帕累托区域不一定是连接的(M2的第一部分)。图5说明了声明M2的第二部分:帕累托区域的连接部分不一定是凸的。图5中描述的例子使用两个计划和一个二维参数空间。这个例子需要一个二维的参数空间,因为一维参数空间中的连接区域总是形成凸形的多边形。让c1(x1,x2)=(x1,x2)是计划1的二维成本函数(二维身份函数),c2(x1,x2)=(1,1)是计划2的成本函数,计划1支配计划2的区域形成一个凸多角形,如图5所示。剩下的区域是计划2的帕累托区域。图5清楚地表明,帕累托区域不是凸的。


图4的例子也证明了M3a。图6中的例子证明了M3b。图6显示了三个计划在两个成本指标和一个参数下的成本函数。计划3在参数范围(0.5,1.5)内是帕累托最优的,但在范围[0,0.5]和范围[1.5,2]内则不是。我们例子中的成本函数不是单调的,但这些例子可以调整(只需将数字逆时针旋转45度)。PQ的一个常见假设是,计划成本函数在参数中是单调的[4]。我们看到,这个假设并没有改变我们的负面结果。

4.2 算法设计影响
表1左栏中列出的PQ问题的三个属性使得我们可以设计PQ算法,将一个PQ问题分成几个CQ问题。这种方法的好处是,现有的CQ查询优化器可以变成PQ的优化器,而且实施开销相对较低:现有的CQ优化器的代码基本保持不变(这就是为什么这种PQ方法被称为非侵入式的[17]),只需要增加一小段代码,将PQ问题分割成几个CQ问题。现在我们将看到,为什么这种方法对MPQ是失败的。
Hulgeri和Sudarshan[17]提出的递归分解算法是一种非侵入性的PQ算法,工作原理如下。给定参数空间中的一个凸多角形,该算法为该多角形的每个顶点计算一个最优计划(使用CQ查询优化器)。如果每个顶点的计划都是最优的,那么该计划对多面体中的每一个点都是最优的(根据表1的陈述S3),没有必要进一步分解。如果不同的计划对不同的顶点来说是最优的,那么多角形就会被分解成片段,算法就会递归地应用于每个片段。
所描述的算法对于其他非侵入性的PQ方法[13, 17, 18]是有代表性的,因为它们都是将参数空间连续地分解成只有一个计划是最优的片段。声明S3对所有这些算法都是至关重要的,因为它导致了一个充分的条件来检查进一步分解是否是不必要的。声明M3表明,对于MPQ来说,无法找到类似的条件:即使同一组计划对于参数空间中凸多角形的所有顶点都是帕累托最优的,也可能仍然需要进一步分解该多角形,以找到所有帕累托计划(根据声明M3b)。这意味着不可能将PQ的非侵入式算法推广到MPQ(这将使一个MPQ问题被分割成几个MQ问题,现有的MQ算法可以应用于这些问题[14])。在这一见解的推动下,我们在下一节中提出了一个相当不同的MPQ方法。
五、通用算法
在本节中,我们介绍了MPQ的相关性区域修剪算法(RRPA)。该算法将每个查询计划与参数空间中的RR联系起来,在剪枝过程中用于检测不相关的计划。该算法是通用的,不针对PWL成本函数。第5.1节描述了该算法,第5.2节证明了RRPA能够为任意的MPQ问题实例找到完整的PPS。我们没有明确描述如何在优化过程中处理嵌套查询;在之前的工作中已经提出了将复杂的SQL语句分解成简单的SPJ查询块的技术[26]。
5.1 算法概述
上一节的分析表明,试图将非侵入性的PQ算法适应于MPQ并不是一个有希望的方向。我们采用了一种基于动态编程(DP)的方法,从join子集的最优计划中计算出join table sets的最优计划。这种方法似乎很有希望,因为DP已经被广泛用于设计CQ[26]、MQ[14]和PQ[17]的算法。算法1展示了RRPA的伪代码。主函数接受一个查询Q作为输入并返回一个Q的PPS。这个算法使用了2个系列的全局变量:对于每个子查询q⊆Q,变量Pq最终将包含q的PPS,变量Rq包含相应的RM(让p∈Pq是q的执行计划,那么Rq(p)指定p的RR)。我们假设计划集最初是空的。RRPA首先计算每个基表q∈Q的PPS和RM;它计算每个基表的所有可能的扫描计划,并修剪掉在整个参数空间中被支配的计划。修剪函数的细节将在后面讨论。在基表之后,RRPA以cardinality的升序处理表集。一个辅助函数通过考虑q的所有可能的分割为两个非空的子集(每个分割代表最后一次连接的一对特殊算子),最后一次连接的所有可能的算子,以及生成最后一次连接的所有计划对(这些计划从之前计算的PPS中选出)来生成连接表集q⊆Q的PPS。对于每个操作数、运算符和子计划的组合,都会产生一个暂定计划。这个计划与所有其他产生相同结果并且已经包含在Pq中的计划进行配对比较。这些比较发生在剪枝函数中。其目的是识别并抛弃那些不需要形成PPS的次优计划。
修剪是基于第2节中介绍的RR的概念。每个计划都与参数空间中的一个RR相关联,对于这个RR,没有已知的替代计划具有同等或更优的成本。一个新生成的计划的RR是由全部参数空间初始化的。在对新生成的计划和join相同表的旧计划进行一系列比较的过程中,它(RR)被减少。在每次比较中,新计划的RR被参数空间中由旧计划支配新计划的点所减少。如果新计划的RR是空的,它就被丢弃了。否则,新计划被插入。在插入新计划之前,旧计划的RR被它们被新计划支配的区域所减少。具有空RRs的旧计划被丢弃。下面的例子说明了剪枝的方法。
EXAMPLE 3:我们重新审视场景1。Figure 7展示了join相同2个表的2个查询计划的代价函数。需要被执行join的数据量线性依赖于一个谓词的选择率;因此,所有的代价函数都依赖于这个参数。执行计划1使用了一个单节点的join,执行计划2使用了一个包含多个节点的并行join。执行计划1在输入数据量较小的情况下比执行计划2要快,因为不需要通过网络进行数据shuffle(假设所有需要的输入数据初始化时存在于一个节点上)。执行计划2在输入数据量较大时比执行计划1要快,由于它做了并行化。执行计划2始终要比执行计划1花费更多的费用,因为费用与总工作量成正比(在不同的节点上相加),而且总工作量因并行化而增加。
假设执行计划1在执行计划2之前被生成,执行计划2创建后的RR直接是整个参数空间[0,1],计划2与之前生成的所有join相同表的计划一起被修剪,在我们的例子中,只有计划1。根据执行时间和费用,只要选择率小于0.25,计划1就比计划2好。因此,计划2的RR被区间[0,0.25]减少,这样计划2在区间[0.25,1]内仍然是相关的。注意,这个例子只使用了仅依赖于一个参数的线性函数,而RRPA可以处理任意数量的参数的任意成本函数。
算法1没有规定如何实现添加成本函数或对相关区域RR进行交集计算等基本操作。实现这些操作的最佳方式取决于所考虑的成本函数的类别(这也隐含地决定了我们所需要考虑的RR形状类别)。因此,不可能为一般情况指定一个实现方案。出于同样的原因,也不可能分析RRPA的时间复杂性。然而,我们将在Section6中介绍一个针对PWL成本函数的RRPA的特别版本,并分析其复杂性。
5.2 完备性证明
我们证明RRPA可以为不同的输入查询生成完整的PPSs。我们做了一个常见的假设,即最优化原则(POO)[14]对每个成本度量都是成立的:用一个替代的子计划p′S替换一个查询计划p中的子计划pS,该计划在特定的参数向量x和特定的成本度量m下比pS的成本更好或相等,只能得到一个根据m的成本优于或相等于p的成本的计划。POO限制了一个计划的成本函数与它的子计划的成本函数之间的关系,但它并不限制一般的成本函数的形状。
RRPA生成PPS的证明是对要加入的表的数量的归纳。下面的定理将被用于归纳步骤。
悖论1:如果RRPA为所有连接到N个表的查询生成PPS和相应的RM,那么它也为连接到N+1个表的查询生成PPS和相应的RM。
证明:假设Q是一个连接N+1个表的查询(|Q|=N+1),向量x⊆X是一个任意的参数向量,p是Q的一个任意计划。计划p有两个子计划,p1和p2,每个计划最多连接N个表。因此,RRPA产生了一个计划p1*,它产生的结果与p1相同,并且对x来说支配p1。RRPA还生成了一个计划p2*,其属性与p2相似。计划p∗1和p∗2可以组合成一个计划p∗,产生与p相同的结果,并且对x来说支配p(由于有POO)。
RRPA将生成p*并以全部的参数空间初始化其RR。在和其他执行计划的配对比较中,只有计划p*的RR变为空,p*才会被剪枝。这只能发生在RRPA保留了另一个在x上支配p*的执行计划,并且x被包含在该计划的RR中。RRPA为查询Q生成了一个PPS和相应的RM(相关映射,将每个帕累托计划映射到参数空间中的相关区域(RR)),因为p和x是任意选择的。
以下定理是本小节的主要结果:
定理3:RRPA为任意的MPQ问题实例生成PPSs。
证明简述:该证明是对要加入的表的数量的归纳。在RRPA为单个表生成PPS和相应的RM的假设下(归纳开始)。根据Lemma1(归纳步骤),它也为任意表集生成PPS和相应的RM。RRPA考虑了每个基表的所有可能的计划,并且只丢弃在整个参数空间中被支配的计划。这就证明了归纳法的开始。
六、分段线性代价函数算法
上一节中介绍的RRPA是通用的,因为它可以处理任意的成本函数。RRPA的伪代码(算法1)留下了某些问题,如,如何代表RR,如何有效地交叉和减少它们;这些问题的答案取决于所考虑的成本函数的类别。在本节中,我们提出了一个针对PWL成本函数的RRPA的特殊版本。PWL-RRPA。我们在第6.1节中提出了表示成本函数和RR的数据结构,在第6.2节中展示了如何在这些结构上有效地实现基本操作,并在第6.3节中分析了PWL-RRPA的复杂性。PWL-RRPA保证为任意的PWL-MPQ概率实例生成PPS,因为它是RRPA的一个专门化。
6.1 数据结构
在算法1中,Rq(p)形式的表达式指定了一个join表集合q的计划p的RR。图8描述了RR作为实体关系图的内部表示。一个RR由一组凸多边形表示,称为切割区(切口),这样,如果一个参数空间向量不包含在任何切割区中,它就被保留在一个RR中。下面的定理证明了这种表示方法的合理性。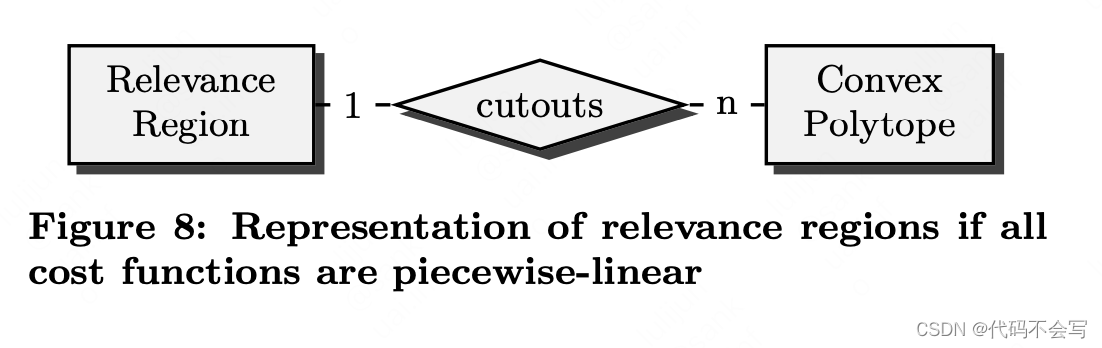
定理4:在PWL-RRPA执行过程中出现的任何相关区域都可以表示为一组凸多边形的补集。
证明:一个新执行计划的RR是整个参数空间,因此可以表示为一个空集的补集。在初始化之后,RR可以通过一个执行计划被其他执行计划所支配的区域被多次减少。当使用PWL成本函数比较两个执行计划时,根据定理1,参数空间可以被分为线性区域。根据定理2,在一个线性区域内一个集合支配另一个集合的区域会形成一个凸多边形。因此,被减少后的RR仍然可以表示为凸多边形的补集。
在算法1中,一个执行计划p的成本函数用表达式c(p)来表示。Figure 9展示了成本函数作为实体关系图的内部表示。一个多目标PWL成本函数由在每个成本度量上的单目标PWL成本函数组成。PWL成本函数在形成凸多边形的参数空间区域内是线性的。因此,每个PWL函数被表示为一组线性函数;每个线性函数的特征是它所适用的参数空间区域(Figure 9中的属性reg)和一个权重向量(Figure 9中的属性w),其中每个参数有一个权重以及一个定义线性函数的标量基础cost(Figure 9中的b)。线性分片的参数空间域不能重叠;然后可以通过识别区域中包含x的唯一分片来评估PWL函数,并通过评估公式b+wT -x来获得成本值。一个多目标PWL函数是通过按照上述方法对齐所有的组成部分进行评估的。
PWL成本函数可以对单个scan和join操作的实际成本函数进行近似,其精度可以达到任意程度。因此,整个查询计划的累积成本(使用标准的累积函数,如最小、最大和加权和)可以再次表示为PWL函数;这一事实已经被先前的PQ算法所使用。将这一推理推广到多目标的情况是不费吹灰之力的。因此,Figure 9中的标识方法涵盖了PWL-RRPA执行过程中出现的每个成本函数(假设单个操作的成本是由PWL函数近似计算的)。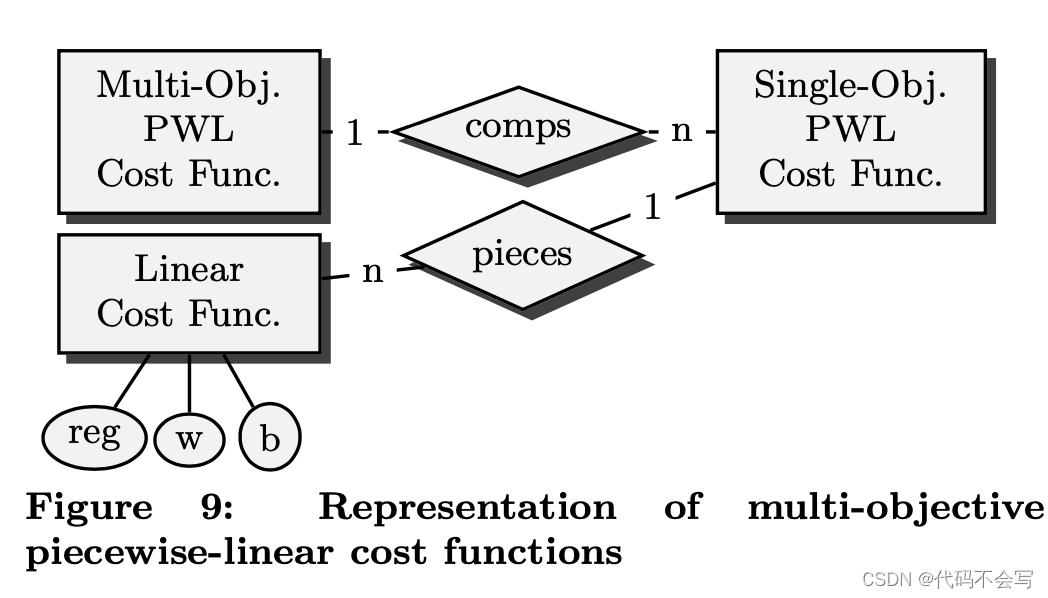
6.2 基本运算实现
PWL-RRPA对RR进行两项操作:它通过一个计划被另一个计划支配的区域来减少其RR(例如,算法1,第39行),并检查一个RR是否为空(算法1,第41行)。算法2显示了这两种操作的伪代码。字段指定符.cutouts指的是图8,表示代表一个RR的变量的cutouts集合。如图10所示,凸多边形是通过添加它们作为切口从RR中减去的。


函数IsEmpty是基于以下定理的。
定理5:一个相关区域是空的,如果它的切口的联合形成一个覆盖整个参数空间的凸多角形。
证明。让Ci⊆X是切口的集合。RR是空iff∀x∈X∃i:x∈Ci。这相当于X = ∪iCi,因为所有的切口都包含在参数空间X内。
切口的联合可能不是凸的,也可能没有形成一个多角形。检查一个形状不一的区域(切口的联合体)是否包含参数空间是低效的。因此,关键是要注意,只有在切口的联合体形成一个凸多边形的特殊情况下,包含性检查才是必要的。Bemporad等人的算法[6]检查凸多面体的联合体是否又是一个凸多面体,并在这种情况下CON-结构相应的多面体。检查两个凸多面体之间的包含性是一个标准问题[20]。
PWL-RRPA对成本函数进行了两种操作。它通过累加其子计划的成本来计算一个新计划的成本函数(算法1,第26行),并且--给定两个成本函数--它计算其中一个支配另一个的区域(例如,算法1,第39行)。算法3显示了这两种操作的伪代码。组合关系(见图9)将一个多目标成本函数与每个成本指标的一个单目标函数联系起来。我们将comps关系视为一个数组,用符号.[m]来指代度量m的单目标成本函数。函数AccumulateCost将一个新计划的成本从其子计划的成本中累积起来。它在所有成本指标上进行迭代,并分别计算每个指标的成本函数。对于每个指标,它将参数空间划分为两个子计划都具有线性成本函数的区域。每个非空的线性区域成为新计划的成本函数中的一个片断。新棋子的权重向量对应于两个子计划的权重向量和相应参数空间区域1中的连接成本向量(在伪代码中用o.w表示)的分量和;图11说明了参数为σ1和σ2的二维参数空间的这个步骤,二维权重向量显示在其线性区域的内部。新棋子的基本成本是加入的基本成本(o.b)和子计划的基本成本之和。因此,成本是通过增加子计划的成本来积累的。该函数可以简单地推广到成本以两个成本函数的加权和、最小值或最大值累积的情况。
函数Dom返回一组凸多面体,代表计划p1支配计划p2的区域。根据每个成本指标,一个计划在其具有更好或同等成本的区域内支配另一个计划。在第二步中,函数Dom初步计算每个成本度量m的参数空间中的凸多角形集合DomPolysm,其中p1根据m优于或等同于p2。
我们描述了到目前为止对预先发送的伪代码的一些改进;这些改进导致了我们实验中性能的显著提高。首先,我们尽可能地通过删除多余的线性约束来模拟凸多边形的内部表示。如果一个线性约束被同一多边形的其他约束所暗示,那么它就是多余的。其次,我们通过删除多余的切口来简化RR的内部表示。如果一个切口被同一RR的其他切口所覆盖,它就是多余的。第三,我们通过将每个新创建的RR与分布在整个参数空间的一组释放点联系起来,以避免不必要的空洞检查。每当一个新的切口被添加到RR中,包含在新切口中的相关点就会从点列表中删除。只要点列表不是空的,RR本身也不可能是空的,执行函数IsEmpty就可以避免了。
6.3 复杂度分析
七、实验评估
八、总结
这篇关于(论文阅读-多目标优化器)Multi-Objective Parametric Query Optimization的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






