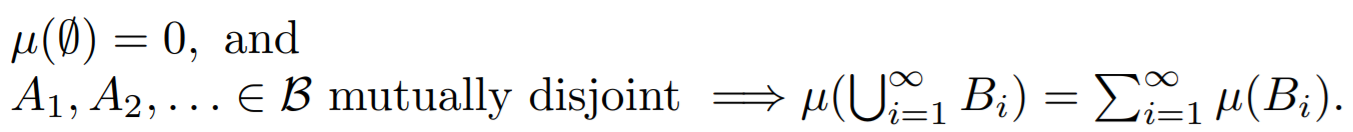本文主要是介绍NBNN及SIS Measure,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文主要讲一种稀疏表示下的特征相似度度量方法,叫做SIS Measure,该度量方法结合NBNN可以完成目标分类的任务,且对特征空间非聚集的特征分类有很好的效果。相关实验结果可参考文献[2]。本文主要是实现该方法时的一些简单的心得和代码,欢迎交流。
1. 实验步骤
1.1. NBNN
首先阅读论文[1],了解了非参数分类器的基本内容,如非参数分类器的优势在于:(1) 能自然地处理大量数据的分类问题;(2) 有效地避免过拟合;(3) 无需学习/训练阶段。同时熟悉了NBNN的算法概要,如下:

1.2. SIS Measure
而后开始阅读参考文献[2],了解Similarity Measure的大致内容,进一步理解SIS(Sparsity Induced Similarity) Measure的算法含义。Similarity Measure主要有欧式距离、高斯核的相似度等,它们的不足在于忽略了类的结构信息。在参考文献[2]中,考虑到特征空间中,人们使用高维特征向量,而可以假设每一类的特征向量都属于低维的特征子空间,提出了特征向量的稀疏表示下的相似度度量。 参考文献[2]提出的稀疏引导的相似度度量方法定义如下:

其中, L1 范数最小化问题是由Focuss 算法求解的。之所以选择Focuss 算法,是因为:该问题下,对于解向量稀疏度没有很好的先验知识,因此不能使用OMP等方法;另一方面,如采用[2]中所述的linear programming 的方法,由于引入 x+,x−, 将加大程序的空间复杂度。 通过该相似度度量,我们可以得出输入特征向量与其余样本向量的相似度,由此得到一个N×N的相似度矩阵,再由该相似度矩阵通过最近邻算法得到其分类标记。
2. 实验结果
如图1即为得到的相似度矩阵。

由最终实验预测可知,bed的预测正确率为60%,forest的预测正确率为70%。另实验代码见文档附录。
3. 实验中遇到的问题
3.1. SIS的理解
SIS的构造并非只是简单的计算稀疏系数向量,再比较各向量中对应类分量的模值大小,而是需要分别计算出 Sij 和 Sji在最初实验时,我曾选择某一特征向量作为输入,计算其在剩余向量撑成的矩阵中的稀疏系数,继而比较稀疏系数大小来确定其所属类别。虽然这样的处理与文献[2]中Toy problem所示类似,但是却不是SIS度量的正确理解,之后重新修改了代码,实现了完整的SIS度量方式。
3.2. Wii的设置
Wii 虽然在论文中设置为1(符合相似度度量的直观),但是为了代码的简便性,实际实验中预测时设置其为0。这是因为如果实验中将Wii设置为1,预测时需要额外的步骤把对应该项元素值踢出;而将其设置为0,则在预测时Wii对预测不产生影响。
4. 实验反思
首先本次实验中使用的数据量较小,因此对于论文中采用的“CD”欧式距离特征预选择并未能用到;出于同样的原因,在构造出所有向量的相似度矩阵后,采用最近邻分类时,采用相似度最高的特征向量所属的类作为输入向量的分类标记,一定程度上忽略了类的分布结构信息,影响了分类的准确度。在得到更多数据的前提下,修改以上两点可以获得更高的分类准确度,以及数据量归一化下更快的执行速度。
Reference
[1] Boiman O, Shechtman E, Irani M In defense of nearest-neighbor based image classification[C]//Computer Vision and Pattern Recognition, 2008 CVPR 2008 IEEE Conference on IEEE, 2008: 1-8
[2] H Cheng, Z Liu, L Hou, and J Yang Sparsity induced similarity measure and its applications IEEE Transactions on Circuits and Systems for Video Technology, 2012
附录:实验代码(Matlab语言)
clear all;
close all
clc load bedroom.mat
load forest.mat
[m,n] = size(bedroom);
%data feature normalization
for i =1:m Nbedroom(i,:) = bedroom(i,:)./max(bedroom(i,:));
end
for i =1:m NMITforest(i,:) = MITforest(i,:)./max(MITforest(i,:));
end
Nbedroom = Nbedroom';
NMITforest = NMITforest';
[m,n] = size(Nbedroom);
%parameter
%% bed
for k = 1:n fk = Nbedroom(:,k); Gk = [Nbedroom(:,1:k-1) Nbedroom(:,k+1:end) NMITforest]; [x_bed(:,k)] = Focuss(Gk,fk);
end
for k = 1:n fk = NMITforest(:,k); Gk = [Nbedroom NMITforest(:,1:k-1) NMITforest(:,k+1:end)]; [x_forest(:,k+n)] = Focuss(Gk,fk);
end Xk = [x_bed zeros(19,10)]+ x_forest;
[M,N] = size(Xk);
for k = 1:N for i = 1:M x = Xk(:,k); rest = sum(x' * (x > 0)) - max(x(i),0); S(k,i) = max(Xk(i,k),0) ./ (rest); end
end
for i = 1:N s = S(i,:); S_new(i,:) = [s(1:i-1) 0 s(i:end)];
end
W = (S_new + S_new')./2;
Wnew = W + eye(N);
%compute classified probability
for i = 1:N [whatever,sim_label(i)] = max(W(i,:));
end
class = sim_label < N/2;
ratebed = sum(class(1:N/2))/length(class(1:N/2))
rateforest = sum(~(class(N/2+1:N)))/length(class(N/2+1:N))
这篇关于NBNN及SIS Measure的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!