本文主要是介绍如何配置X86应用程序启用大地址模式(将用户态虚拟内存从2GB扩充到3GB),以解决用户态虚拟内存不够用问题?(项目实战案例解析),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1、概述
2、为什么不直接将程序做成64位的?
3、进程内存不足导致程序发生闪退的案例分析
3.1、问题说明
3.2、将Windbg附加到程序进程上进行动态调试
3.3、动态调试的Windbg感知到了中断,中断在DebugBreak函数调用上
3.4、malloc或new失败的可能原因分析
3.5、为什么没能生成dump文件?
3.6、本例中malloc返回NULL的原因分析
3.7、为啥有的机器不出现,只在个别电脑上出现?
4、程序用户态虚拟内存占用高导致不够用的解决办法
4.1、修改WebRTC编译选项,减少内存占用
4.2、将程序做成64位的
4.3、使用多进程模式
4.4、使用Visual Studio的链接选项,将用户态虚拟内存从2GB扩充到3GB(最终选择的这个方法)
5、最后
C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/125529931C/C++基础与进阶(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/article/details/125529931C/C++基础与进阶(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_11931267.htmlVC++常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)
https://blog.csdn.net/chenlycly/category_11931267.htmlVC++常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/124272585C++软件分析工具从入门到精通案例集锦(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/article/details/124272585C++软件分析工具从入门到精通案例集锦(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/article/details/131405795网络编程与网络问题分享(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/article/details/131405795网络编程与网络问题分享(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_2276111.html 对于32位程序,默认情况下其用户态虚拟内存只有2GB,可能会出现内存不够用的情况,继而出现后续内存申请失败,导致软件出现异常。本文结合项目中出现的一个具体问题实例,详细讲述问题的排查定位的过程,并详细讨论了解决用户态虚拟内存不够用的手段与策略,最后讲述如何配置X86应用程序启用大地址模式(将用户态虚拟内存从2GB扩充到3GB)去解决内存不够用的问题。
https://blog.csdn.net/chenlycly/category_2276111.html 对于32位程序,默认情况下其用户态虚拟内存只有2GB,可能会出现内存不够用的情况,继而出现后续内存申请失败,导致软件出现异常。本文结合项目中出现的一个具体问题实例,详细讲述问题的排查定位的过程,并详细讨论了解决用户态虚拟内存不够用的手段与策略,最后讲述如何配置X86应用程序启用大地址模式(将用户态虚拟内存从2GB扩充到3GB)去解决内存不够用的问题。
1、概述
对于32位程序,系统给程序进程分配4GB的虚拟内存,默认情况下,用户态虚拟内存占2GB,内核态虚拟内存占2GB。对于应用程序,业务代码基本都是运行在用户态中的,占用的是用户态的虚拟内存。可能会因为程序模块多占用的内存过大,也可能是程序中存在内存泄漏,导致程序进程占用的用户态虚拟内存达到或者接近2GB的上限,导致后续内存申请失败,或者产生Out of memory内存耗尽的异常。
如果是内存泄漏导致的,则要排查泄漏的原因,解决泄漏问题。
如果是程序业务模块过多,占用了大量的内存,使程序占用的用户态虚拟内存接近2GB(快达到2GB的上限),导致后续内存申请失败,则需要对程序占用的内存进行优化,减少程序对虚拟内存的占用。如果内存优化空间有限,仍然无法解决问题,则可以将程序的用户态虚拟内存从2GB扩充到3GB,将问题规避掉。
对于32程序,总的虚拟内存是4GB,默认情况下,用户态虚拟内存占2GB,内核态虚拟内存占2GB。如果将用户态虚拟内存由2GB扩充到3GB,则内核态虚拟内存会从2GB较少到1GB,即内核态虚拟内存就变小了,对运行在内核态的模块的执行效率会带来一定的影响,虽然这种影响不大。另外,尽量对虚拟内存进行优化,如果程序占用的虚拟内存较大,要频繁地在虚拟内存与物理内存之间切换,也会对程序的执行效率产生影响。
2、为什么不直接将程序做成64位的?

64位程序的虚拟内存到大的多,既然32位程序的虚拟内存有限,为什么不做成64位的呢?32位程序可以在32位操作系统中运行,也可以在64位操作系统中运行(64位系统兼容32位程序)。但64位程序只能在64系统中运行,无法在32位系统运行。
为了同时支持32位和64位操作系统,将程序都做成32位的,当然,有些软件做成了32位和64位两个版本,可以根据操作系统的位数,选择安装对应位数的程序。
如果要将程序做成64位的,则程序从上到下的所有模块都要编译成64位的,因为32位模块和64位模块是不同混在一起使用的,如果强行混在一起使用,程序会报错的。
以64位Windows系统为例,64位系统是如何保证32位程序与64位都能正常运行的呢?程序会依赖很多系统dll库,而32位程序只能依赖使用32位的dll库,64位程序也只能依赖使用64位的dll库。系统为了同时支持32位与64位程序的运行,提供了32位版本和64位版本的系统dll库:

1)C:\Windows\System32:64位系统dll库目录。
2)C:\Windows\SysWOW64:32位系统dll库目录。
系统在启动程序时会根据程序的位数,去选择加载对应位数的系统dll库。
方便大家理解和记忆,此处说一下C:\Windows\SysWOW64路径中的WOW64的含义,MSDN上对WOW64的解释如下:
WOW64 is the x86 emulator that allows Win32-based applications to run on 64-bit Windows. It is intended to run 32-bit personal productivity applications needed by software developers and administrators. It is not intended to run 32-bit server applications.
即WOW64的大致含义是,W-Win32,O-On,W64-Win64(64-bit Windows),32位程序运行在64系统上。
3、进程内存不足导致程序发生闪退的案例分析
3.1、问题说明
之前有客户反馈,我们的客户端软件在他们某台华为MATE笔记本电脑上运行时,会时不时地出现闪退问题(问题不是必现的)。程序闪退时并没有弹出崩溃的提示框(如果程序的异常捕获模块感知到程序发生了崩溃,会弹出一个崩溃提示框),说明程序中安装的异常捕获模块并没有感知到异常,所以没有生成dump文件,所以也就没法使用Windbg静态分析dump文件的方式去分析这个问题。
程序中安装的异常捕获模块,大概只能捕获到90%左右场景的异常,有少部分异常是捕捉不到的。对于异常捕获不到的场景,则需要使用其他方法排查分析,比如使用Windbg进行动态调试。
3.2、将Windbg附加到程序进程上进行动态调试
既然异常捕获模块没有感知到,我们只能将Windbg附加到程序进程上进行动态调试,即将Windbg附加到程序进程上,和程序一起跑,如果程序发生异常,Windbg会第一时间感知到并中断下来,这个时候我们就趁这个中断的机会,去查看函数调用堆栈去分析。
但这个问题不是必现的,只能让客户每次启动程序时,都手动将Windbg附加到目标进程上,让Windbg跟着程序一起跑。一旦问题复现,Windbg就会感知到并中断下来。
在这里,给大家重点推荐一下我的几个热门畅销专栏:(博客主页还有其他专栏,可以去查看)
专栏1:(该精品技术专栏的订阅量已达到430多个,专栏中包含大量项目实战分析案例,有很强的实战参考价值,广受好评!专栏文章持续更新中,预计更新到200篇以上!)
C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/125529931
https://blog.csdn.net/chenlycly/article/details/125529931
本专栏根据多年C++软件异常排查的项目实践,系统地总结了引发C++软件异常的常见原因以及排查C++软件异常的常用思路与方法,详细讲述了C++软件的调试方法与手段,以图文并茂的方式给出具体的项目问题实战分析实例(很有实战参考价值),带领大家逐步掌握C++软件调试与异常排查的相关技术,适合基础进阶和想做技术提升的相关C++开发人员!
考察一个开发人员的水平,一是看其编码及设计能力,二是要看其软件调试能力!所以软件调试能力(排查软件异常的能力)很重要,必须重视起来!能解决一般人解决不了的问题,既能提升个人能力及价值,也能体现对团队及公司的贡献!
专栏中的文章都是通过项目实战总结出来的,包含大量项目问题实战分析案例,有很强的实战参考价值!专栏文章还在持续更新中,预计文章篇数能更新到200篇以上!
专栏2:
C/C++基础与进阶(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_11931267.html
https://blog.csdn.net/chenlycly/category_11931267.html
以多年的开发实战经验为基础,总结并讲解一些的C/C++基础与进阶内容,以图文并茂的方式对C++相关知识点进行详细地展开与剖析!专栏涉及了C/C++开发领域多个方面的内容,同时给出C/C++及网络方面的常见笔试面试题,并详细讲述Visual Studio常用调试手段与技巧!
专栏3:
VC++常用功能开发汇总![]() https://blog.csdn.net/chenlycly/article/details/124272585
https://blog.csdn.net/chenlycly/article/details/124272585
专栏将10多年C++开发实践中常用的功能,以高质量的代码展现出来,并对相关功能的实现细节进行了详细的说明。这些常用的代码,其质量与稳定性是有保证的,可以直接拿过去使用,可以有效地解决C++软件开发过程中遇到的问题。
3.3、动态调试的Windbg感知到了中断,中断在DebugBreak函数调用上
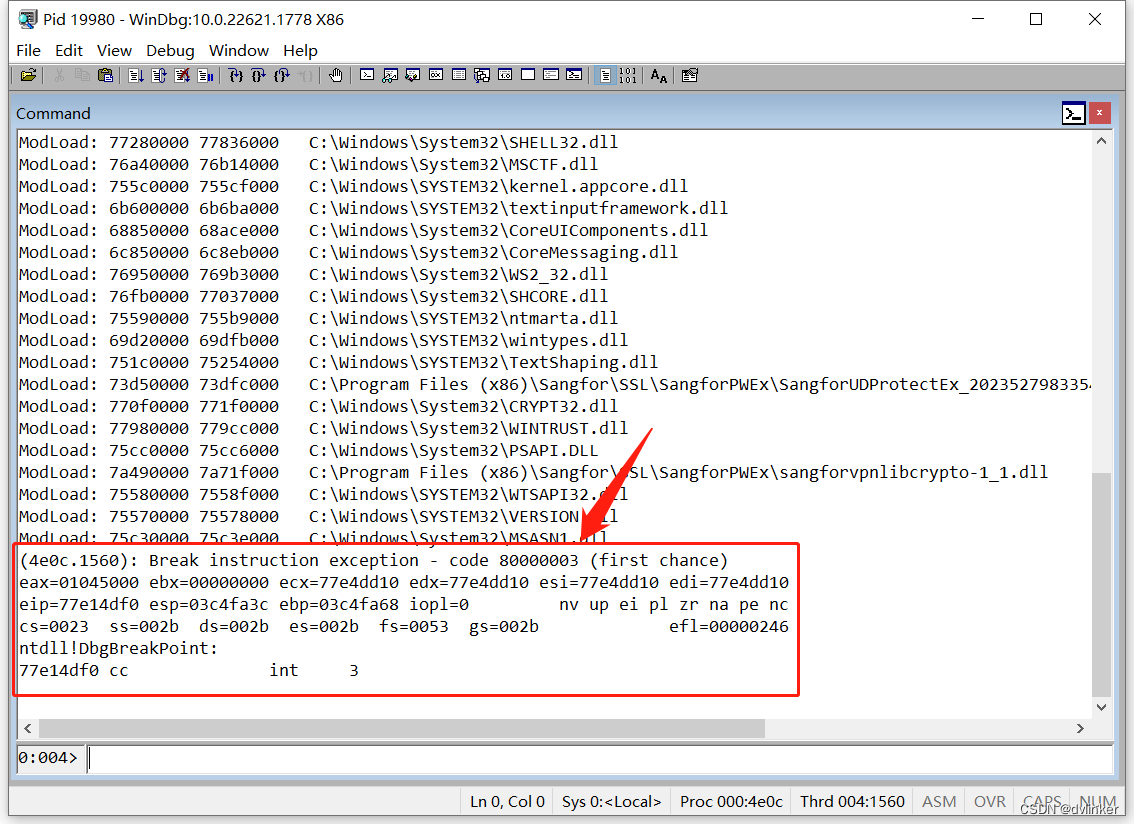
后来同事每次运行程序时都将Windbg附加到程序进程上,复现了问题,正在调试的Windbg中断了下来,发现中断在DebugBreak接口调用处,如下所示:
输入kn命令查看此时的函数调用堆栈:
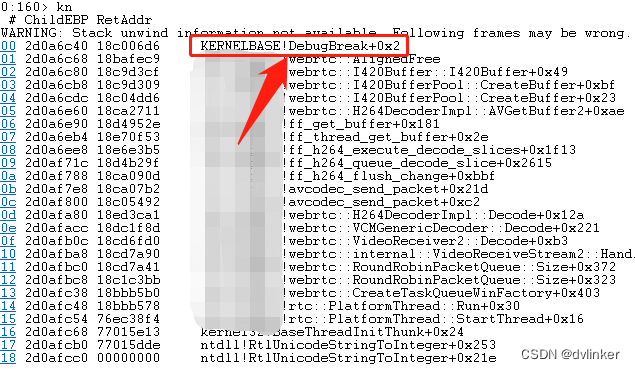
正是DebugBreak接口就是让正在调试的进程中断下来的。DebugBreak是Windows API函数,从函数名称上也能看出来,该函数就是让正在调试的调试器中断下来,此时的中断确实是调用了DebugBreak引起的中断。
于是顺着函数调用堆栈向上看,问题是出在WebRTC开源库中的,然后根据函数调用堆栈中的函数,找到对应的C++源码,看到是代码中调用malloc申请动态内存时,申请内存失败,返回空指针NULL,然后引发DebugBreak的调用,具体流程可以对照下列代码看:
1)申请内存的malloc返回NULL:
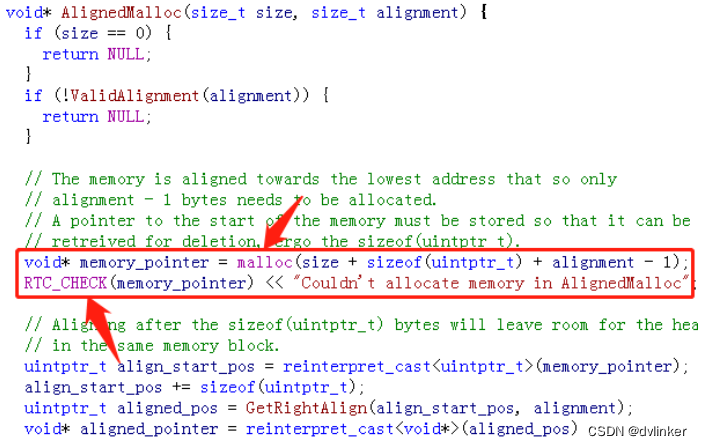
2)malloc返回NULL,会执行到RTC_CHECK宏中的rtc_FatalMessage接口:

3)rtc_FatalMessage接口中紧接着调用到FatalLog接口:

4) FatalLog接口中调用了DebugBreak接口:


此外,我们在实际调试时发现,使用g命令将DebugBreak函数调用引发的中断跳过去,Windbg还会产生一次中断,是因为调用abort系统函数,abort函数的内部实现代码如下:
/***
*void abort() - abort the current program by raising SIGABRT
*
*Purpose:
* print out an abort message and raise the SIGABRT signal. If the user
* hasn't defined an abort handler routine, terminate the program
* with exit status of 3 without cleaning up.
*
* Multi-thread version does not raise SIGABRT -- this isn't supported
* under multi-thread.
*******************************************************************************/
void __cdecl abort (void)
{_PHNDLR sigabrt_act = SIG_DFL;#ifdef _DEBUGif (__abort_behavior & _WRITE_ABORT_MSG){/* write the abort message */_NMSG_WRITE(_RT_ABORT);}
#endif /* _DEBUG *//* Check if the user installed a handler for SIGABRT.* We need to read the user handler atomically in the case* another thread is aborting while we change the signal* handler.*/sigabrt_act = __get_sigabrt();if (sigabrt_act != SIG_DFL){raise(SIGABRT);}/* If there is no user handler for SIGABRT or if the user* handler returns, then exit from the program anyway*/if (__abort_behavior & _CALL_REPORTFAULT){_call_reportfault(_CRT_DEBUGGER_ABORT, STATUS_FATAL_APP_EXIT, EXCEPTION_NONCONTINUABLE);}/* If we don't want to call ReportFault, then we call _exit(3), which is the* same as invoking the default handler for SIGABRT*/_exit(3);
}abort函数内部是通过调用exit系统函数将当前进程强制退出的,但在退出之前会调用raise(SIGABRT),该函数触发一个SIGABRT信号终止异常,如果当前正在调试状态,会让调试器中断下来。
3.4、malloc或new失败的可能原因分析
如果malloc申请内存失败,则会返回NULL;如果new申请内存失败,默认会抛出bad_alloc异常。 那为啥会出现malloc或new操作失败的问题呢?之前我们总结过,一般malloc或new失败可能是以下几种原因导致的:
1)申请的内存过大,进程中没有这么大内存可用了
可能受一些异常数据的影响,申请了很大尺寸的内存。比如前段时间排查一个崩溃问题,当时因为数据有异常,一次性申请了9999*9999*4*2 = 762MB的堆内存,进程中没有这么大可用的堆内存了,所以申请失败了。
2)用户态的内存已经达到了上限,申请不到内存了
有可能是虚拟内存占用太多,也有可能代码中有内存泄露,导致用户态的虚拟内存被消耗完了。对于一个32程序,一个进程分配了4GB的虚拟地址空间,而用户态和内核态内存各占一半,即用户态的虚拟内存只有2GB,如果程序占用的虚拟内存比较大,比如接近2GB的用户虚拟内存了,再申请大的内存就会申请失败了。或者程序中有内存泄露,快要把用户态的2GB的虚拟内存给占用完了,再申请内存可能会申请失败的。
3)进程中的内存碎片过多
如果进程中在大量的new和delete,产生了大量的小块内存碎片,可用的内存被切割成一小块一小块的小内存块,如果要申请一块长度很长的内存,因为到处是内存碎片,没有这么一大块连续的可用内存,可能会导致内存申请失败的。
4)发生堆内存越界
堆内存被破坏,导致new操作产生异常(此时new不会返回NULL,会抛出异常)。我们可以在出问题的地方,对该处的new添加一个保护(但不可能对代码中所有new的地方都加这样的保护),我们通过添加try...catch去捕获new抛出的异常,并将异常码打印出来,如下所示:(下面的代码在循环申请内存,直到内存申请失败为止,主要用来测试用)#include <iostream> using namespace std;int main(){char *p;int i = 0;try{do{p = new char[10*1024*1024];i++;Sleep(5);}while(p);}catch(const std::exception& e){std::cout << e.what() << "\n"<< "分配了" << i*10 << "M" << std::endl;}return 0; }
3.5、为什么没能生成dump文件?
现在我们再回过头去看看,程序发生闪退时为什么没有生成dump文件。 上面已经分析出程序闪退的原因了,是因为WebRTC开源库中调用malloc申请内存失败(因为进程的用户态虚拟内部不够用了,没有足够空闲的内存可供分配了)返回空指针NULL,WebRTC认为申请内存失败了,业务没法正常跑下去了,认为是致命的,然后最终调用abort系统函数强行将当前进程终止的。
程序中只是调用malloc申请内存失败,然后调用abort强行终止进程,并没有产生C++异常或崩溃。并没有产生C++异常或崩溃,异常捕获模块是感知不到的,所以没生成dump文件的,这和运行时实际表现出来的现象是完全吻合的!
如果代码中不是调用malloc去动态申请内存,而是使用new去申请,则在申请不到内存时new内部会抛出bad_alloc异常,这个会导致程序崩溃的,异常捕获模块应该能感知到,会生成dump文件。
3.6、本例中malloc返回NULL的原因分析
在本例中排除了内存泄漏的可能,推测是程序占用的虚拟内存过多,接近程序用户态虚拟内存2GB的上限,导致后续申请内存时没有足够的内存可供分配了,所以申请内存失败!

我们软件之前的版本,没有使用WebRTC开源库,一直没有这个问题的。这个问题是在引入WebRTC开源库后才出现的,可能和引入的WebRTC有关系的。WebRTC开源库内部功能庞大,内部包含了大量的业务和逻辑,会占用大量的内存,按讲是不适合用在32位程序中,因为32位程序的用户态虚拟内存默认只有2GB,很有可能会出现用户态虚拟内存不够用的情况。
3.7、为啥有的机器不出现,只在个别电脑上出现?
为啥这个问题有的机器不出现,只在个别电脑上出现呢?可能和机器的硬件配置及操作系统版本有关系。不同版本的操作系统的内存管理机制可能是有差异的。WebRTC开源库内部会根据机器的配置及网络带宽,去动态地调整音视频编码的分辨率等参数,会消耗不同大小的内存。
4、程序用户态虚拟内存占用高导致不够用的解决办法

WebRTC开源库比较大,会消耗很多的内存,如何解决WebRTC占用大量虚拟内存的问题,有如下的方法。
4.1、修改WebRTC编译选项,减少内存占用
可以尝试修改WebRTC编译选项,对其进行裁剪缩编,释放出一些占用内存的代码,但这种做法降低内存的效果有限,因为WebRTC作为大型库本来就需要占用大量的内存资源。
WebRTC库的源码就有10多个GB,是个非常庞大的开源库,内部包含了大量的业务逻辑和功能,需要占用大量的内存!有些内存在库初始化的时候就申请了,即很多内存一上来就占用上了,而不是需要使用时再去申请。
4.2、将程序做成64位的
要将程序做成64位的,底层的模块都要编译成64位的,32位模块与64位模块是不同混在一起使用的。如果强行混在一起,则运行会报错的。程序底层包含了上百个模块,都要将代码移植到64位上,可能会遇到这样那样的问题,短时间内完成迁移,会产生很多bug的。
再就是我们的程序要兼容32位操作系统,目前只能做成32位的,没有人力去分别制作32位版本和64位版本。
即便可以将主程序做成64位的,64位程序的用户态虚拟内存非常大,可以“肆无忌惮”的使用。但占用的虚拟内存过大,在代码执行过程中虚拟内存要切换到物理内存上,会来回在虚拟内存与物理内存之间频繁地切换,也会影响程序的执行效率。此外,物理内存较小,也会影响虚拟内存到物理内存的切换,也会显著降低程序的运行速度。
4.3、使用多进程模式
但上述方法,在使用WebRTC开源库时可能有问题,如果要解码更多路数的视频,会占用更多的内存。可以考虑将WebRTC封装成进程,使用多进程的模式,主进程与WebRTC进程使用RPC方式进行接口的调用。像Chrome那样,搞多个进程,不同的进程处理不同的事务,可以将程序占用的内存分摊到不同的进程上。并且一个进程崩溃了,也不会影响到主进程,将崩溃的进程重新启动起来就好。
但多个进程之间需要通信,需要协同控制,控制不好也容易出问题。进程之间如何高效地的传递数据也是个问题,这都需要人力和技术去支撑。但多进程模式是比较稳妥的解决方案之一。
4.4、使用Visual Studio的链接选项,将用户态虚拟内存从2GB扩充到3GB(最终选择这个方法)
可以在Visual Studio链接选项中打开扩大用户态虚拟内存的选项/L largeAddressAware,如下所示:
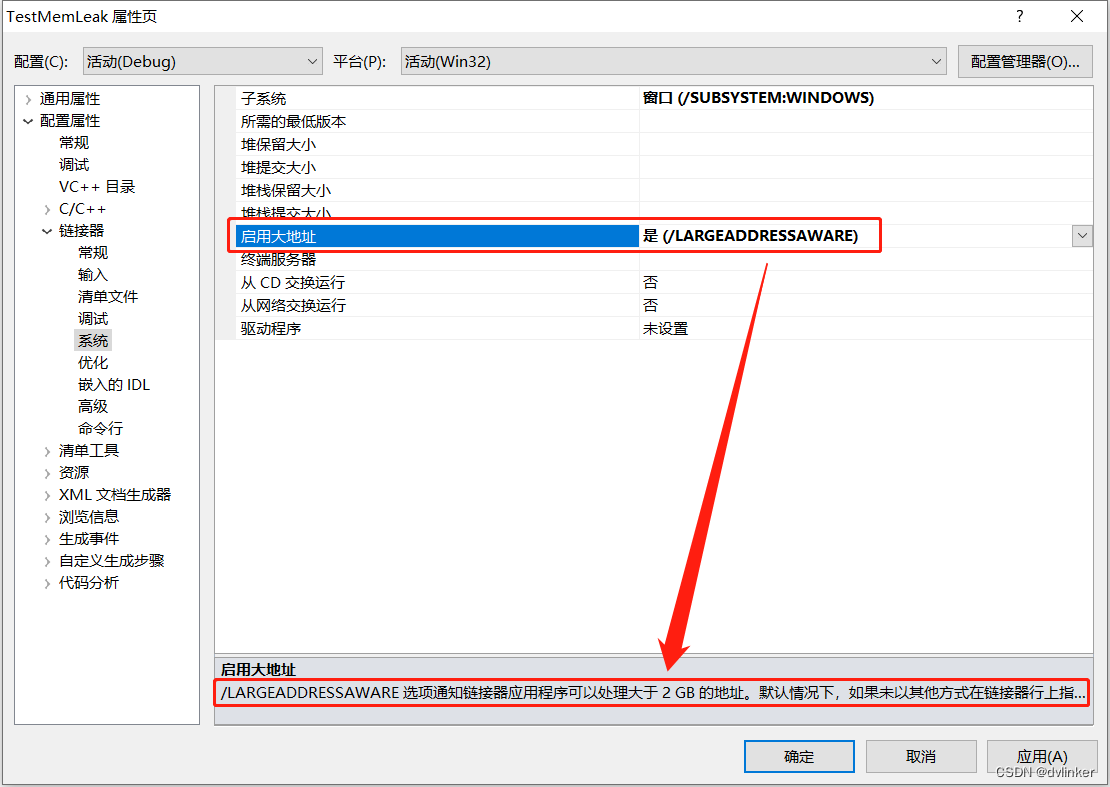
这样可以将用户态虚拟内存扩到3GB,这样可以有效缓解内存不够用的问题。
32位进程只有4GB的虚拟内存,如果将用户态虚拟内存由2GB扩到3GB,内核态的虚拟内存应该会被压缩到1GB,这样会不会导致内核态的代码执行比较慢,导致程序的运行性能下降呢?可能运行性能会有一定的损失,但既然系统运行这种扩充用户态虚拟内存的方式,应该影响不会很大。这个方法简单快速,也不会引入新的bug,短期内最合适,所以最后选的是这个方法!
5、最后
在Visual Studio中修改链接选项,可以直接将用户态虚拟内存从2GB扩充到3GB,可以有效的规避内存不够用的问题。这种方法简单方便,可以快速地解决问题。但最根本的还是要对内存进行优化,尽量减少对内存的占用,也能提高程序的执行效率。当然优化代码的过程中,也可能会引入这样那样的bug,需要根据时间和工作量评估可行性。
这篇关于如何配置X86应用程序启用大地址模式(将用户态虚拟内存从2GB扩充到3GB),以解决用户态虚拟内存不够用问题?(项目实战案例解析)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





