本文主要是介绍AI大模型探索之路-训练篇13:大语言模型Transformer库-Evaluate组件实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验
AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践
AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
AI大模型探索之路-训练篇11:大语言模型Transformer库-Model组件实践
AI大模型探索之路-训练篇12:语言模型Transformer库-Datasets组件实践
目录
- 系列篇章💥
- 前言
- 一、Evaluate组件介绍
- 二、Evaluate API用法
- 1、安装依赖
- 2、查看支持的评估函数
- 3、加载评估函数
- 4、查看函数说明
- 5、评估指标计算——全局计算
- 6、评估指标计算——迭代计算
- 7、多个评估指标计算
- 8、评估结果对比可视化
- 三、改造预训练代码
- 总结
前言
在自然语言处理(NLP)技术的迅猛发展过程中,基于深度学习的模型逐渐成为了研究和工业界解决语言问题的主流工具。特别是Transformer模型,以其独特的自注意力机制和对长距离依赖的有效捕捉能力,在多个NLP任务中取得了革命性的突破。然而,随着模型变得越来越复杂,如何准确评估模型的性能,理解模型的优势与局限,以及指导进一步的模型优化,成为了一个挑战。

官网的API:https://huggingface.co/docs/evaluate/index
为了简化这一过程并推广到更广泛的开发者群体,大语言模型Transformer库被设计出来,它不仅提供了训练和部署模型的工具,还包含了Evaluate组件。Evaluate组件的出现,正是为了填补这一空白,使得评估模型性能变得更加直接、高效和标准化。它为研究人员和工程师们提供了一套系统的评价方案,从而能够更加深入地理解和改进他们的模型。接下来,我们将深入探讨Evaluate组件的功能及其在大语言模型Transformer库中的实践应用。
一、Evaluate组件介绍
在自然语言处理的深度学习模型开发流程中,评估(Evaluation)阶段是至关重要的一环。它不仅帮助我们量化模型的性能,还为模型的进一步优化提供了依据。Evaluate组件正是为此而设计,旨在提供一套标准化的评估流程和工具,帮助开发者和研究人员更加系统地分析模型表现。
Evaluate组件在大语言模型Transformer库中扮演着核心角色。它与训练和推理(Inference)组件紧密集成,确保了从模型开发到部署的每一个环节都能被有效监控和评价。以下是Evaluate组件的关键特性:
1)标准化指标:Evaluate组件提供了一系列标准化的评价指标,如准确率(Accuracy)、召回率(Recall)、精确度(Precision)和F1分数(F1 Score),以及更复杂的度量如混淆矩阵(Confusion Matrix)、编辑距离(Edit Distance)等。这些指标为模型性能提供了全面的量化分析。
2)模型-数据接口:该组件设计了明确的接口用于连接模型和评估数据。开发者可以轻松指定待评估的模型以及用于评估的数据集,使得评估过程既灵活又高效。
3)评估报告:通过evaluate函数完成评估后,Evaluate组件能够生成详细的评估报告。报告中包括各项指标的得分,以及模型在不同类别上的表现,甚至可以展现模型预测的实例结果,帮助用户直观理解模型的优势和不足。
4)可视化工具:除了文本形式的报告外,Evaluate组件还提供可视化工具,如混淆矩阵的图表展示。这些图表帮助开发者快速识别模型在特定类型的输入上的表现情况,从而针对性地进行改进。
5)错误分析:对于分类任务,Evaluate组件还能够进行错误分析,指出模型在哪些样本上出错,以及出错的可能原因,这对于调试和改善模型具有重要意义。
6)易于集成和扩展:Evaluate组件的设计允许它轻松集成到现有的模型开发流程中,并且可以根据具体任务需求进行扩展,比如添加新的评价指标或定制报告格式。
二、Evaluate API用法
1、安装依赖
pip install evaluate
2、查看支持的评估函数
import evaluate
evaluate.list_evaluation_modules()
输出
['lvwerra/test','jordyvl/ece','angelina-wang/directional_bias_amplification','cpllab/syntaxgym','lvwerra/bary_score','hack/test_metric','yzha/ctc_eval','codeparrot/apps_metric','mfumanelli/geometric_mean','daiyizheng/valid','erntkn/dice_coefficient','mgfrantz/roc_auc_macro','Vlasta/pr_auc','gorkaartola/metric_for_tp_fp_samples','idsedykh/metric','idsedykh/codebleu2','idsedykh/codebleu','idsedykh/megaglue','cakiki/ndcg','Vertaix/vendiscore','GMFTBY/dailydialogevaluate','GMFTBY/dailydialog_evaluate','jzm-mailchimp/joshs_second_test_metric','ola13/precision_at_k','yulong-me/yl_metric','abidlabs/mean_iou','abidlabs/mean_iou2','KevinSpaghetti/accuracyk','NimaBoscarino/weat','ronaldahmed/nwentfaithfulness','Viona/infolm','kyokote/my_metric2','kashif/mape','Ochiroo/rouge_mn','giulio98/code_eval_outputs','leslyarun/fbeta_score','giulio98/codebleu','anz2/iliauniiccocrevaluation','zbeloki/m2','xu1998hz/sescore','dvitel/codebleu','NCSOFT/harim_plus','JP-SystemsX/nDCG','sportlosos/sescore','Drunper/metrica_tesi','jpxkqx/peak_signal_to_noise_ratio','jpxkqx/signal_to_reconstruction_error','hpi-dhc/FairEval','lvwerra/accuracy_score','ybelkada/cocoevaluate','harshhpareek/bertscore','posicube/mean_reciprocal_rank','bstrai/classification_report','omidf/squad_precision_recall','Josh98/nl2bash_m','BucketHeadP65/confusion_matrix','BucketHeadP65/roc_curve','yonting/average_precision_score','transZ/test_parascore','transZ/sbert_cosine','hynky/sklearn_proxy','xu1998hz/sescore_english_mt','xu1998hz/sescore_german_mt','xu1998hz/sescore_english_coco','xu1998hz/sescore_english_webnlg','unnati/kendall_tau_distance','Viona/fuzzy_reordering','Viona/kendall_tau','lhy/hamming_loss','lhy/ranking_loss','Muennighoff/code_eval_octopack','yuyijiong/quad_match_score','Splend1dchan/cosine_similarity','AlhitawiMohammed22/CER_Hu-Evaluation-Metrics','Yeshwant123/mcc','transformersegmentation/segmentation_scores','sma2023/wil','chanelcolgate/average_precision','ckb/unigram','Felipehonorato/eer','manueldeprada/beer','tialaeMceryu/unigram','shunzh/apps_metric','He-Xingwei/sari_metric','langdonholmes/cohen_weighted_kappa','fschlatt/ner_eval','hyperml/balanced_accuracy','brian920128/doc_retrieve_metrics','guydav/restrictedpython_code_eval','k4black/codebleu','Natooz/ece','ingyu/klue_mrc','Vipitis/shadermatch','unitxt/metric','gabeorlanski/bc_eval','jjkim0807/code_eval','vichyt/metric-codebleu','repllabs/mean_reciprocal_rank','repllabs/mean_average_precision','mtc/fragments','DarrenChensformer/eval_keyphrase','kedudzic/charmatch','Vallp/ter','DarrenChensformer/relation_extraction','Ikala-allen/relation_extraction','danieldux/hierarchical_softmax_loss','nlpln/tst','bdsaglam/jer','fnvls/bleu1234','fnvls/bleu_1234','nevikw39/specificity','yqsong/execution_accuracy','shalakasatheesh/squad_v2','arthurvqin/pr_auc','d-matrix/dmx_perplexity','lvwerra/test','jordyvl/ece','angelina-wang/directional_bias_amplification','cpllab/syntaxgym','lvwerra/bary_score','hack/test_metric','yzha/ctc_eval','codeparrot/apps_metric','mfumanelli/geometric_mean','daiyizheng/valid','erntkn/dice_coefficient','mgfrantz/roc_auc_macro','Vlasta/pr_auc','gorkaartola/metric_for_tp_fp_samples','idsedykh/metric','idsedykh/codebleu2','idsedykh/codebleu','idsedykh/megaglue','cakiki/ndcg','Vertaix/vendiscore','GMFTBY/dailydialogevaluate','GMFTBY/dailydialog_evaluate','jzm-mailchimp/joshs_second_test_metric','ola13/precision_at_k','yulong-me/yl_metric','abidlabs/mean_iou','abidlabs/mean_iou2','KevinSpaghetti/accuracyk','NimaBoscarino/weat','ronaldahmed/nwentfaithfulness','Viona/infolm','kyokote/my_metric2','kashif/mape','Ochiroo/rouge_mn','giulio98/code_eval_outputs','leslyarun/fbeta_score','giulio98/codebleu','anz2/iliauniiccocrevaluation','zbeloki/m2','xu1998hz/sescore','dvitel/codebleu','NCSOFT/harim_plus','JP-SystemsX/nDCG','sportlosos/sescore','Drunper/metrica_tesi','jpxkqx/peak_signal_to_noise_ratio','jpxkqx/signal_to_reconstruction_error','hpi-dhc/FairEval','lvwerra/accuracy_score','ybelkada/cocoevaluate','harshhpareek/bertscore','posicube/mean_reciprocal_rank','bstrai/classification_report','omidf/squad_precision_recall','Josh98/nl2bash_m','BucketHeadP65/confusion_matrix','BucketHeadP65/roc_curve','yonting/average_precision_score','transZ/test_parascore','transZ/sbert_cosine','hynky/sklearn_proxy','xu1998hz/sescore_english_mt','xu1998hz/sescore_german_mt','xu1998hz/sescore_english_coco','xu1998hz/sescore_english_webnlg','unnati/kendall_tau_distance','Viona/fuzzy_reordering','Viona/kendall_tau','lhy/hamming_loss','lhy/ranking_loss','Muennighoff/code_eval_octopack','yuyijiong/quad_match_score','Splend1dchan/cosine_similarity','AlhitawiMohammed22/CER_Hu-Evaluation-Metrics','Yeshwant123/mcc','transformersegmentation/segmentation_scores','sma2023/wil','chanelcolgate/average_precision','ckb/unigram','Felipehonorato/eer','manueldeprada/beer','tialaeMceryu/unigram','shunzh/apps_metric','He-Xingwei/sari_metric','langdonholmes/cohen_weighted_kappa','fschlatt/ner_eval','hyperml/balanced_accuracy','brian920128/doc_retrieve_metrics','guydav/restrictedpython_code_eval','k4black/codebleu','Natooz/ece','ingyu/klue_mrc','Vipitis/shadermatch','unitxt/metric','gabeorlanski/bc_eval','jjkim0807/code_eval','vichyt/metric-codebleu','repllabs/mean_reciprocal_rank','repllabs/mean_average_precision','mtc/fragments','DarrenChensformer/eval_keyphrase','kedudzic/charmatch','Vallp/ter','DarrenChensformer/relation_extraction','Ikala-allen/relation_extraction','danieldux/hierarchical_softmax_loss','nlpln/tst','bdsaglam/jer','fnvls/bleu1234','fnvls/bleu_1234','nevikw39/specificity','yqsong/execution_accuracy','shalakasatheesh/squad_v2','arthurvqin/pr_auc','d-matrix/dmx_perplexity','lvwerra/test','jordyvl/ece','angelina-wang/directional_bias_amplification','cpllab/syntaxgym','lvwerra/bary_score','hack/test_metric','yzha/ctc_eval','codeparrot/apps_metric','mfumanelli/geometric_mean','daiyizheng/valid','erntkn/dice_coefficient','mgfrantz/roc_auc_macro','Vlasta/pr_auc','gorkaartola/metric_for_tp_fp_samples','idsedykh/metric','idsedykh/codebleu2','idsedykh/codebleu','idsedykh/megaglue','cakiki/ndcg','Vertaix/vendiscore','GMFTBY/dailydialogevaluate','GMFTBY/dailydialog_evaluate','jzm-mailchimp/joshs_second_test_metric','ola13/precision_at_k','yulong-me/yl_metric','abidlabs/mean_iou','abidlabs/mean_iou2','KevinSpaghetti/accuracyk','NimaBoscarino/weat','ronaldahmed/nwentfaithfulness','Viona/infolm','kyokote/my_metric2','kashif/mape','Ochiroo/rouge_mn','giulio98/code_eval_outputs','leslyarun/fbeta_score','giulio98/codebleu','anz2/iliauniiccocrevaluation','zbeloki/m2','xu1998hz/sescore','dvitel/codebleu','NCSOFT/harim_plus','JP-SystemsX/nDCG','sportlosos/sescore','Drunper/metrica_tesi','jpxkqx/peak_signal_to_noise_ratio','jpxkqx/signal_to_reconstruction_error','hpi-dhc/FairEval','lvwerra/accuracy_score','ybelkada/cocoevaluate','harshhpareek/bertscore','posicube/mean_reciprocal_rank','bstrai/classification_report','omidf/squad_precision_recall','Josh98/nl2bash_m','BucketHeadP65/confusion_matrix','BucketHeadP65/roc_curve','yonting/average_precision_score','transZ/test_parascore','transZ/sbert_cosine','hynky/sklearn_proxy','xu1998hz/sescore_english_mt','xu1998hz/sescore_german_mt','xu1998hz/sescore_english_coco','xu1998hz/sescore_english_webnlg','unnati/kendall_tau_distance','Viona/fuzzy_reordering','Viona/kendall_tau','lhy/hamming_loss','lhy/ranking_loss','Muennighoff/code_eval_octopack','yuyijiong/quad_match_score','Splend1dchan/cosine_similarity','AlhitawiMohammed22/CER_Hu-Evaluation-Metrics','Yeshwant123/mcc','transformersegmentation/segmentation_scores','sma2023/wil','chanelcolgate/average_precision','ckb/unigram','Felipehonorato/eer','manueldeprada/beer','tialaeMceryu/unigram','shunzh/apps_metric','He-Xingwei/sari_metric','langdonholmes/cohen_weighted_kappa','fschlatt/ner_eval','hyperml/balanced_accuracy','brian920128/doc_retrieve_metrics','guydav/restrictedpython_code_eval','k4black/codebleu','Natooz/ece','ingyu/klue_mrc','Vipitis/shadermatch','unitxt/metric','gabeorlanski/bc_eval','jjkim0807/code_eval','vichyt/metric-codebleu','repllabs/mean_reciprocal_rank','repllabs/mean_average_precision','mtc/fragments','DarrenChensformer/eval_keyphrase','kedudzic/charmatch','Vallp/ter','DarrenChensformer/relation_extraction','Ikala-allen/relation_extraction','danieldux/hierarchical_softmax_loss','nlpln/tst','bdsaglam/jer','fnvls/bleu1234','fnvls/bleu_1234','nevikw39/specificity','yqsong/execution_accuracy','shalakasatheesh/squad_v2','arthurvqin/pr_auc','d-matrix/dmx_perplexity']
3、加载评估函数
"""
准确率(accuracy)是一种评估分类模型性能的指标。它是正确预测的数量与总预测数量的比值。
对于二分类问题,其计算公式为(TP+TN) / (TP+TN+FP+FN),其中:TP(True Positive):真正,实际为正样本,预测也为正样本
TN(True Negative):真负,实际为负样本,预测也为负样本
FP(False Positive):假正,实际为负样本,预测却为正样本
FN(False Negative):假负,实际为正样本,预测却为负样本"""accuracy = evaluate.load("accuracy")

4、查看函数说明
1)打印出准确率(accuracy)的描述信息
print(accuracy.description)
输出
Accuracy is the proportion of correct predictions among the total number of cases processed. It can be computed with:
Accuracy = (TP + TN) / (TP + TN + FP + FN)Where:
TP: True positive
TN: True negative
FP: False positive
FN: False negative
2)打印出准确率(accuracy)的输入描述信息
print(accuracy.inputs_description)
输出
Args:predictions (`list` of `int`): Predicted labels.references (`list` of `int`): Ground truth labels.normalize (`boolean`): If set to False, returns the number of correctly classified samples. Otherwise, returns the fraction of correctly classified samples. Defaults to True.sample_weight (`list` of `float`): Sample weights Defaults to None.Returns:accuracy (`float` or `int`): Accuracy score. Minimum possible value is 0. Maximum possible value is 1.0, or the number of examples input, if `normalize` is set to `True`.. A higher score means higher accuracy.Examples:Example 1-A simple example>>> accuracy_metric = evaluate.load("accuracy")>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0])>>> print(results){'accuracy': 0.5}Example 2-The same as Example 1, except with `normalize` set to `False`.>>> accuracy_metric = evaluate.load("accuracy")>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], normalize=False)>>> print(results){'accuracy': 3.0}Example 3-The same as Example 1, except with `sample_weight` set.>>> accuracy_metric = evaluate.load("accuracy")>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], sample_weight=[0.5, 2, 0.7, 0.5, 9, 0.4])>>> print(results){'accuracy': 0.8778625954198473}
3)查看:accuracy
accuracy
输出
EvaluationModule(name: "accuracy", module_type: "metric", features: {'predictions': Value(dtype='int32', id=None), 'references': Value(dtype='int32', id=None)}, usage: """
Args:predictions (`list` of `int`): Predicted labels.references (`list` of `int`): Ground truth labels.normalize (`boolean`): If set to False, returns the number of correctly classified samples. Otherwise, returns the fraction of correctly classified samples. Defaults to True.sample_weight (`list` of `float`): Sample weights Defaults to None.Returns:accuracy (`float` or `int`): Accuracy score. Minimum possible value is 0. Maximum possible value is 1.0, or the number of examples input, if `normalize` is set to `True`.. A higher score means higher accuracy.Examples:Example 1-A simple example>>> accuracy_metric = evaluate.load("accuracy")>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0])>>> print(results){'accuracy': 0.5}Example 2-The same as Example 1, except with `normalize` set to `False`.>>> accuracy_metric = evaluate.load("accuracy")>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], normalize=False)>>> print(results){'accuracy': 3.0}Example 3-The same as Example 1, except with `sample_weight` set.>>> accuracy_metric = evaluate.load("accuracy")>>> results = accuracy_metric.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0], sample_weight=[0.5, 2, 0.7, 0.5, 9, 0.4])>>> print(results){'accuracy': 0.8778625954198473}
""", stored examples: 0)
5、评估指标计算——全局计算
一次性计算准确率(accuracy)。具体来说,它首先加载了一个名为"accuracy"的评估对象,然后使用compute方法计算准确率。在调用compute方法时,传入了两个列表作为参数:references和predictions。其中,references表示参考值,predictions表示预测值。最后,将计算结果存储在results变量中并返回。
accuracy = evaluate.load("accuracy")
results = accuracy.compute(references=[0, 1, 2, 0, 1, 2], predictions=[0, 1, 1, 2, 1, 0])
results
{‘accuracy’: 0.5}
6、评估指标计算——迭代计算
1)采用循环迭代计算准确率(accuracy)
accuracy = evaluate.load("accuracy")
for ref, pred in zip([0,1,0,1], [1,0,0,1]):accuracy.add(references=ref, predictions=pred)
accuracy.compute()
{‘accuracy’: 0.5}
2)使用add_batch方法将每个元组添加到评估对象中。最后,调用compute方法计算准确率并返回结果
accuracy = evaluate.load("accuracy")
for refs, preds in zip([[0,1],[0,1]], [[1,0],[0,1]]):accuracy.add_batch(references=refs, predictions=preds)
accuracy.compute()
{‘accuracy’: 0.5}
7、多个评估指标计算
"""
F1分数(F1 Score)是精确率(Precision)和召回率(Recall)的调和平均值。它综合考虑了模型的精确率和召回率,用于评估模型的整体性能。
其数学公式为:2 * (Precision * Recall) / (Precision + Recall)。
举个例子来解释一下:
假设我们有一个用来预测疾病的模型,我们测试了100个人,其中实际有病的人有50人,没有病的人有50人。
这个模型预测出有病的人有60人,其中实际有病的人有40人(即真正例TP),预测病人中实际健康的人有20人(即假正例FP);
它预测的健康人有40人,其中实际健康的人有30人(即真负例TN),预测健康中实际有病的人有10人(即假负例FN)。
此时,精确率Precision(预测为正的样本中实际为正的比例)为TP / (TP + FP) = 40 / (40 + 20) = 0.67,
召回率Recall(实际为正的样本中预测为正的比例)为TP / (TP + FN) = 40 / (40 + 10) = 0.8。
将精确率和召回率代入F1分数的公式,我们得到F1 = 2 * (0.67 * 0.8) / (0.67 + 0.8) = 0.73。这个值越接近1,表示模型的性能越好。"""
clf_metrics = evaluate.combine(["accuracy", "f1", "recall", "precision"])
clf_metrics
#计算预测结果的准确率、F1分数、召回率和精确度
clf_metrics.compute(predictions=[0, 1, 0], references=[0, 1, 1])
输出
{'accuracy': 0.6666666666666666,'f1': 0.6666666666666666,'recall': 0.5,'precision': 1.0}
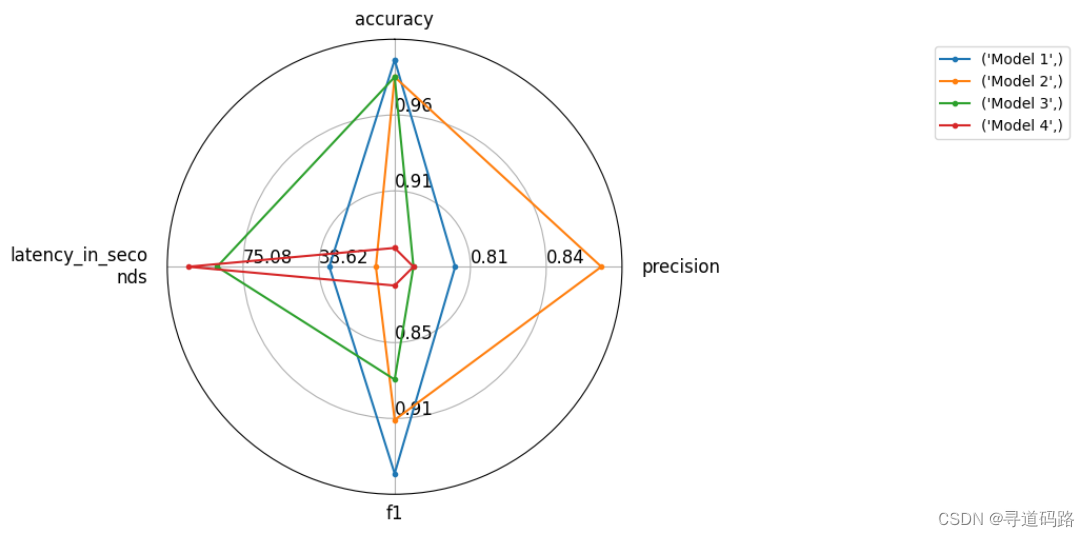
8、评估结果对比可视化
from evaluate.visualization import radar_plotdata = [{"accuracy": 0.99, "precision": 0.8, "f1": 0.95, "latency_in_seconds": 33.6},{"accuracy": 0.98, "precision": 0.87, "f1": 0.91, "latency_in_seconds": 11.2},{"accuracy": 0.98, "precision": 0.78, "f1": 0.88, "latency_in_seconds": 87.6}, {"accuracy": 0.88, "precision": 0.78, "f1": 0.81, "latency_in_seconds": 101.6}]
model_names = ["Model 1", "Model 2", "Model 3", "Model 4"]plot = radar_plot(data=data, model_names=model_names)
三、改造预训练代码
改造前面篇章《AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验》中的第七步中的评估的代码;原来代码如下:
def evaluate():## 将模型设置为评估模式model.eval()acc_num=0#将训练模型转化为推理模型,模型将使用转换后的推理模式进行评估with torch.inference_mode():for batch in validloader:## 检查是否有可用的GPU,如果有,则将数据批次转移到GPU上进行加速if torch.cuda.is_available():batch = {k: v.cuda() for k,v in batch.items()}##对数据批次进行前向传播,得到模型的输出output = model(**batch)## 对模型输出进行预测,通过torch.argmax选择概率最高的类别。pred = torch.argmax(output.logits,dim=-1)## 计算正确预测的数量,将预测值与标签进行比较,并使用.float()将比较结果转换为浮点数,使用.sum()进行求和操作acc_num += (pred.long() == batch["labels"].long()).float().sum()## 返回正确预测数量与验证集样本数量的比值,这表示模型在验证集上的准确率return acc_num / len(validset)
原来是通过计算正确预测的数量与验证集样本数量的比值来得到模型在验证集上的准确率
改造后代码如下:改造后的代码使用了evaluate库来组合多个评估指标,并计算它们的值。
import evaluate
clf_metrics = evaluate.combine(["accuracy", "f1"])def evaluate():model.eval()with torch.inference_mode():for batch in validloader:if torch.cuda.is_available():batch = {k: v.cuda() for k, v in batch.items()}output = model(**batch)pred = torch.argmax(output.logits, dim=-1)clf_metrics.add_batch(predictions=pred.long(), references=batch["labels"].long())return clf_metrics.compute()总结
在本文中,我们详细介绍了大语言模型Transformer库中的Evaluate组件。Evaluate组件的出现填补了评估模型性能的空白,使得评估过程更加直接、高效和标准化。它为研究人员和工程师们提供了一套系统的评价方案,从而能够更加深入地理解和改进他们的模型。
Evaluate组件在大语言模型Transformer库中扮演着核心角色。它与训练和推理(Inference)组件紧密集成,确保了从模型开发到部署的每一个环节都能被有效监控和评价

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
这篇关于AI大模型探索之路-训练篇13:大语言模型Transformer库-Evaluate组件实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






