本文主要是介绍MR shuffle,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MapReduce 是现今一个非常流行的分布式计算框架,它被设计用于并行计算海量数据。第一个提出该技术框架的是Google 公司,而Google 的灵感则来自于函数式编程语言,如LISP,Scheme,ML 等。
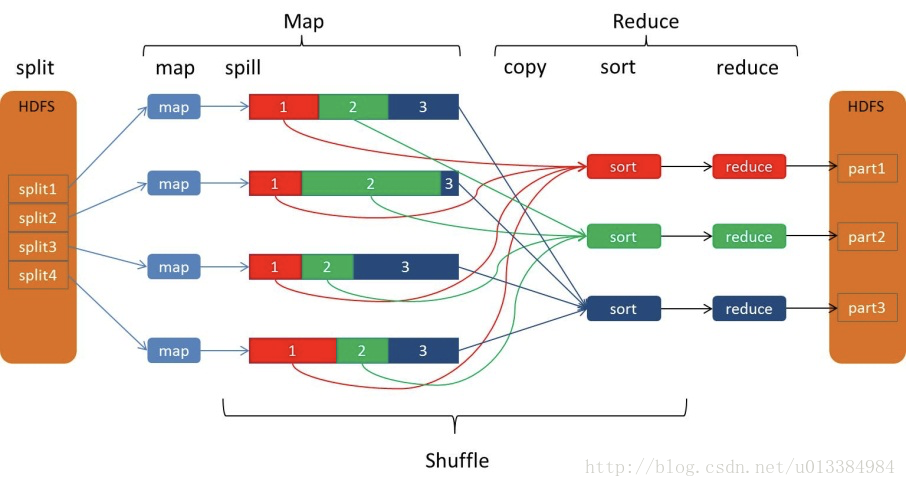
MapReduce 框架的核心步骤主要分两部分:Map 和Reduce。当你向MapReduce 框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map 任务,然后分配到不同的节点上去执行,每一个Map 任务处理输入数据中的一部分,当Map 任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce 任务的输入数据。Reduce 任务的主要目标就是把前面若干个Map 的输出汇总到一起并输出。
本文的重点是剖析MapReduce 的核心过程——Shuffle和Sort。在本文中,Shuffle是指从Map 产生输出开始,包括系统执行排序以及传送Map 输出到Reducer 作为输入的过程。在这里我们将去探究Shuffle是如何工作的,因为对基础的理解有助于对MapReduce 程序进行调优。
首先从Map 端开始分析。当Map 开始产生输出时,它并不是简单的把数据写到磁盘,因为频繁的磁盘操作会导致性能严重下降。它的处理过程更复杂,数据首先是写到内存中的一个缓冲区,并做了一些预排序,以提升效率。
每个Map 任务都有一个用来写入输出数据的循环内存缓冲区。这个缓冲区默认大小是100MB,可以通过io.sort.mb 属性来设置具体大小。当缓冲区中的数据量达到一个特定阀值(io.sort.mb * io.sort.spill.percent,其中io.sort.spill.percent 默认是0.80)时,系统将会启动一个后台线程把缓冲区中的内容spill 到磁盘。在spill 过程中,Map 的输出将会继续写入到缓冲区,但如果缓冲区已满,Map 就会被阻塞直到spill 完成。spill 线程在把缓冲区的数据写到磁盘前,会对它进行一个二次快速排序,首先根据数据所属的partition 排序,然后每个partition 中再按Key 排序。输出包括一个索引文件和数据文件。如果设定了Combiner,将在排序输出的基础上运行。Combiner 就是一个Mini Reducer,它在执行Map 任务的节点本身运行,先对Map 的输出做一次简单Reduce,使得Map 的输出更紧凑,更少的数据会被写入磁盘和传送到Reducer。spill 文件保存在由mapred.local.dir指定的目录中,Map 任务结束后删除。
每当内存中的数据达到spill 阀值的时候,都会产生一个新的spill 文件,所以在Map任务写完它的最后一个输出记录时,可能会有多个spill 文件。在Map 任务完成前,所有的spill 文件将会被归并排序为一个索引文件和数据文件,如图3 所示。这是一个多路归并过程,最大归并路数由io.sort.factor 控制(默认是10)。如果设定了Combiner,并且spill文件的数量至少是3(由min.num.spills.for.combine 属性控制),那么Combiner 将在输出文件被写入磁盘前运行以压缩数据。
对写入到磁盘的数据进行压缩(这种压缩同Combiner 的压缩不一样)通常是一个很好的方法,因为这样做使得数据写入磁盘的速度更快,节省磁盘空间,并减少需要传送到Reducer 的数据量。默认输出是不被压缩的, 但可以很简单的设置mapred.compress.map.output 为true 启用该功能。压缩所使用的库由mapred.map.output.compression.codec 来设定,
目前主要有以下几个压缩格式:
DEFLATE 无DEFLATE .deflate 不支持不可以
gzip gzip DEFLATE .gz 不支持不可以
ZIP zip DEFLATE .zip 支持可以
bzip2 bzip2 bzip2 .bz2 不支持可以
LZO lzop LZO .lzo 不支持不可以
bbs.hadoopor.com --------hadoop 技术论坛
当spill 文件归并完毕后,Map 将删除所有的临时spill 文件,并告知TaskTracker 任务已完成。Reducers 通过HTTP 来获取对应的数据。用来传输partitions 数据的工作线程数由tasktracker.http.threads 控制,这个设定是针对每一个TaskTracker 的,并不是单个Map,默认值为40,在运行大作业的大集群上可以增大以提升数据传输速率。
现在让我们转到Shuffle的Reduce 部分。Map 的输出文件放置在运行Map 任务的TaskTracker 的本地磁盘上(注意:Map 输出总是写到本地磁盘,但Reduce 输出不是,一般是写到HDFS),它是运行Reduce 任务的TaskTracker 所需要的输入数据。Reduce 任务的输入数据分布在集群内的多个Map 任务的输出中,Map 任务可能会在不同的时间内完成,只要有其中的一个Map 任务完成,Reduce 任务就开始拷贝它的输出。这个阶段称之为拷贝阶段。Reduce 任务拥有多个拷贝线程, 可以并行的获取Map 输出。可以通过设定mapred.reduce.parallel.copies 来改变线程数,默认是5。
Reducer 是怎么知道从哪些TaskTrackers 中获取Map 的输出呢?当Map 任务完成之后,会通知它们的父TaskTracker,告知状态更新,然后TaskTracker 再转告JobTracker。这些通知信息是通过心跳通信机制传输的。因此针对一个特定的作业,JobTracker 知道Map 输出与TaskTrackers 的映射关系。Reducer 中有一个线程会间歇的向JobTracker 询问Map 输出的地址,直到把所有的数据都取到。在Reducer 取走了Map 输出之后,TaskTrackers 不会立即删除这些数据,因为Reducer 可能会失败。它们会在整个作业完成后,JobTracker告知它们要删除的时候才去删除。
如果Map 输出足够小,它们会被拷贝到Reduce TaskTracker 的内存中(缓冲区的大小
由mapred.job.shuffle.input.buffer.percent 控制,制定了用于此目的的堆内存的百分比);如果缓冲区空间不足,会被拷贝到磁盘上。当内存中的缓冲区用量达到一定比例阀值(由mapred.job.shuffle.merge.threshold 控制),或者达到了Map 输出的阀值大小(由mapred.inmem.merge.threshold 控制),缓冲区中的数据将会被归并然后spill 到磁盘。
拷贝来的数据叠加在磁盘上,有一个后台线程会将它们归并为更大的排序文件,这样做节省了后期归并的时间。对于经过压缩的Map 输出,系统会自动把它们解压到内存方便对其执行归并。
当所有的Map 输出都被拷贝后,Reduce 任务进入排序阶段(更恰当的说应该是归并阶段,因为排序在Map 端就已经完成),这个阶段会对所有的Map 输出进行归并排序,这个工作会重复多次才能完成。
假设这里有50 个Map 输出(可能有保存在内存中的),并且归并因子是10(由io.sort.factor 控制,就像Map 端的merge 一样),那最终需要5 次归并。每次归并会把10个文件归并为一个,最终生成5 个中间文件。在这一步之后,系统不再把5 个中间文件归并压缩格式工具算法扩展名支持分卷是否可分割成一个,而是排序后直接“喂”给Reduce 函数,省去向磁盘写数据这一步。最终归并的数据可以是混合数据,既有内存上的也有磁盘上的。由于归并的目的是归并最少的文件数目,使得在最后一次归并时总文件个数达到归并因子的数目,所以每次操作所涉及的文件个数在实际中会更微妙些。譬如,如果有40 个文件,并不是每次都归并10 个最终得到4 个文件,相反第一次只归并4 个文件,然后再实现三次归并,每次10 个,最终得到4 个归并好的文件和6 个未归并的文件。要注意,这种做法并没有改变归并的次数,只是最小化写入磁盘的数据优化措施,因为最后一次归并的数据总是直接送到Reduce 函数那里。
在Reduce 阶段,Reduce 函数会作用在排序输出的每一个key 上。这个阶段的输出被直接写到输出文件系统,一般是HDFS。在HDFS 中,因为TaskTracker 节点也运行着一个DataNode 进程,所以第一个块备份会直接写到本地磁盘。
到此,MapReduce 的Shuffle和Sort分析完毕。
这篇关于MR shuffle的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!