本文主要是介绍深度学习--Matlab使用LSTM长短期记忆网络对负荷进行预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、LSTM描述
长短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络,是为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的RNN都具有一种重复神经网络模块的链式形式。在标准RNN中,这个重复的结构模块只有一个非常简单的结构,例如一个tanh层。[概念参考:百度百科]
LSTM网络结构如下图:[图片来源:OPEN-OPEN]
单个LSTM主要包括以下四个步骤。
(1)遗忘门
(2)更新输入信息
(3)更新网络状态
(4)网络输出信息
更详细的分析,此处不再描述,本文着重实现和解决问题。
二、问题描述
已有一个月的电力负荷数据,该负荷数据为每15分钟一个数据点,要求通过对该数据进行学习,对未来的负荷数据进行预测。
采用单向LSTM长短期记忆网络进行深度学习,采用MATLAB平台实现。
三、MATLAB实现
3.1 加载原始数据
原始数据需要构建为行向量,即时间序列值。
%%
%加载数据,重构为行向量
datayears = load('RPD_data.mat');
datayears = datayears.Prpd;
data = datayears(length(datayears)-96*(31):end);
data = data';%很多人问我这个datayears是什么,这里解释一下,以上代码是加载数据
%把你的负荷数据赋值给data变量就可以了。
%data是行向量。要是还不明白,就留言吧。figure
plot(data)
xlabel("Days")
ylabel("Loads")
title("Daily load")运行结果如下:
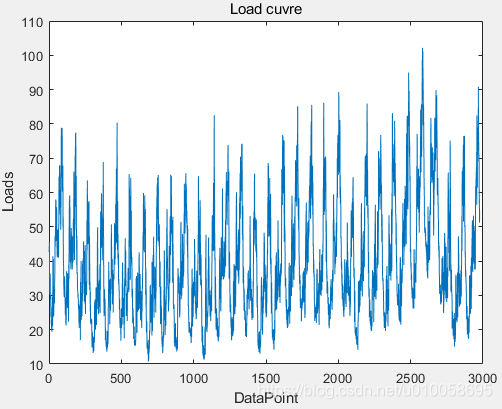
3.2 数据预处理
%%
%序列的前 90% 用于训练,后 10% 用于测试
numTimeStepsTrain = floor(0.9*numel(data));
dataTrain = data(1:numTimeStepsTrain+1);
dataTest = data(numTimeStepsTrain+1:end);%数据预处理,将训练数据标准化为具有零均值和单位方差。
mu = mean(dataTrain);
sig = std(dataTrain);
dataTrainStandardized = (dataTrain - mu) / sig;%输入LSTM的时间序列交替一个时间步
XTrain = dataTrainStandardized(1:end-1);
YTrain = dataTrainStandardized(2:end);3.3 创建LSTM网络
%%
%创建LSTM回归网络,指定LSTM层的隐含单元个数96*3
%序列预测,因此,输入一维,输出一维
numFeatures = 1;
numResponses = 1;
numHiddenUnits = 96*3;layers = [ ...sequenceInputLayer(numFeatures)lstmLayer(numHiddenUnits)fullyConnectedLayer(numResponses)regressionLayer];%指定训练选项,求解器设置为adam, 250 轮训练。
%梯度阈值设置为 1。指定初始学习率 0.005,在 125 轮训练后通过乘以因子 0.2 来降低学习率。
options = trainingOptions('adam', ...'MaxEpochs',250, ...'GradientThreshold',1, ...'InitialLearnRate',0.005, ...'LearnRateSchedule','piecewise', ...'LearnRateDropPeriod',125, ...'LearnRateDropFactor',0.2, ...'Verbose',0, ...'Plots','training-progress');
%训练LSTM
net = trainNetwork(XTrain,YTrain,layers,options);3.4 预测数据
!!!!这里补充一下很多人说没有看到的XTest YTest:
dataTestStandardized = (dataTest - mu) / sig;
XTest = dataTestStandardized(1:end-1);
YTest = dataTest(2:end);这里采用上一时刻的观测值来预测下一时刻的预测值。
net = resetState(net);
net = predictAndUpdateState(net,XTrain);YPred = [];
numTimeStepsTest = numel(XTest);
for i = 1:numTimeStepsTest[net,YPred(:,i)] = predictAndUpdateState(net,XTest(:,i),'ExecutionEnvironment','cpu');
end%使用先前计算的参数对预测去标准化。
YPred = sig*YPred + mu;%计算均方根误差 (RMSE)。
rmse = sqrt(mean((YPred-YTest).^2))3.5 查看预测结果
%将预测值与测试数据进行比较。
figure
subplot(2,1,1)
plot(YTest)
hold on
plot(YPred,'.-')
hold off
legend(["Observed" "Predicted"])
ylabel("Loads")
title("Forecast with Updates")subplot(2,1,2)
stem(YPred - YTest)
xlabel("Days")
ylabel("Error")
title("RMSE = " + rmse)figure
subplot(2,1,1)
plot(dataTrain(1:end-1))
hold on
idx = numTimeStepsTrain:(numTimeStepsTrain+numTimeStepsTest);
plot(idx,[data(numTimeStepsTrain) YPred],'.-')
hold off
xlabel("Days")
ylabel("Loads")
title("Forecast")
legend(["Observed" "Forecast"])
subplot(2,1,2)
plot(data)
xlabel("Days")
ylabel("Loads")
title("Daily load")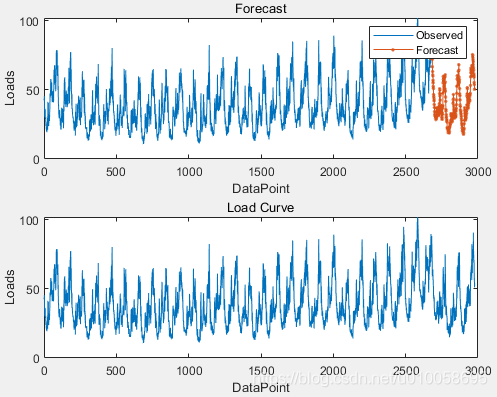

可以看到预测效果非常的好。
其他:
看不懂博文,源代码下载链接:https://x-x.fun/e/YD188aba3boPa
深度学习--Matlab使用LSTM长短期记忆网络对负荷进行分类
这篇关于深度学习--Matlab使用LSTM长短期记忆网络对负荷进行预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






