本文主要是介绍Xinlinx FPGA如何降低Block RAM的功耗,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
FPGA中降低Block RAM的功耗有两种方式,分别是选择合适的写操作模式以及Block RAM的实现算法及综合设置。我们知道对于采用IP核生成对应的RAM时,会有最小面积算法、低功耗算法以及固定原语,但是采用最小功耗算法有时由于级联长度导致无法实现,我们可以通过综合选项得到一个折中的效果,下面将具体介绍。
一、写操作模式
之前我们介绍过BRAM的各种设计细节,可以参考如下文章:
Xinlinx FPGA内的存储器BRAM全解-CSDN博客
我们知道BRAM的写模式一共有三种:写优先、读优先、Nochange
在NO_CHANGE模式下,在写操作期间输出锁存保持不变。如图所示,输出的数据仍然是之前的读数据,不受同一端口上的Write操作的影响。
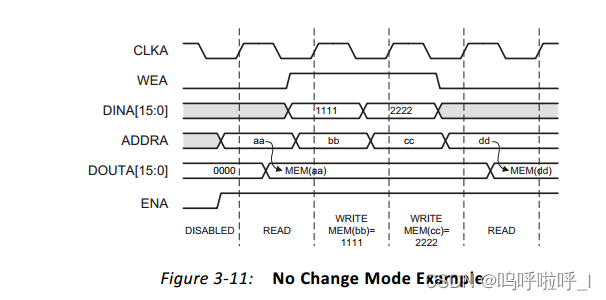
这样就可以减少端口数据的翻转,从而达到降低功耗的目的。
二、实现算法及综合设置
在上面给出的文章中我们介绍了Block RAM一共有三种实现算法,分别是最小面积算法、低功耗算法以及固定原语算法。在这里我们简单介绍一下:
1.实现算法
- 最小面积
最小面积算法使所用的BRAM原语数量最少,同时减少了输出多路复用。
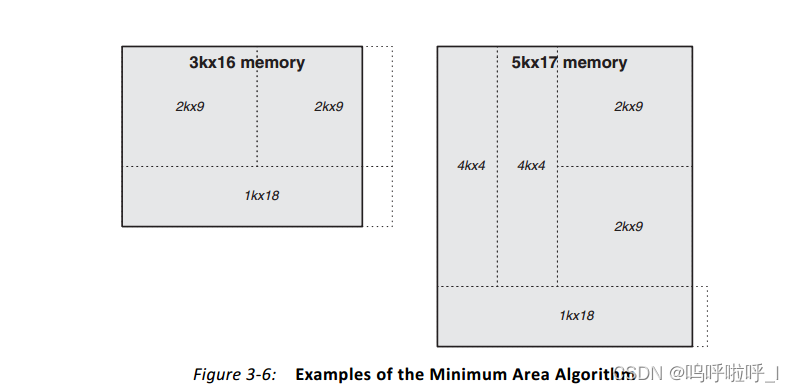
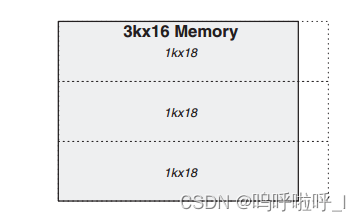
在3k×16RAM的实现中,我们用到了三个18Kb的RAM。为了能够形成对比,我们将3个1K×18的BRAM放在一列构成一个3k×16,如下图。
我们可以发现,在水平和垂直方向上两种方法构成的Memory长度一致,那最小面积是怎么体现出来的呢?这是因为在各个BRAM构成的RAM输出时,需要进行选择。比如对于最小面积算法,在输出时需要对上面2k×19的输出和1k×18的输出进行选择,因此只需要一个2选1多路复用器。那上面两个相邻的2K×19需要进行选择吗,其实是不用的,两个9bit宽的RAM共同构成了要输出的16bit,任何时候都是拼在一起的不需要选择。
- 低功耗
低功耗算法可以最大限度地减少在读或写操作期间启用的原语数量。该算法没有针对面积进行优化,可能比最小面积算法使用更多的BRAM和多路复用器。
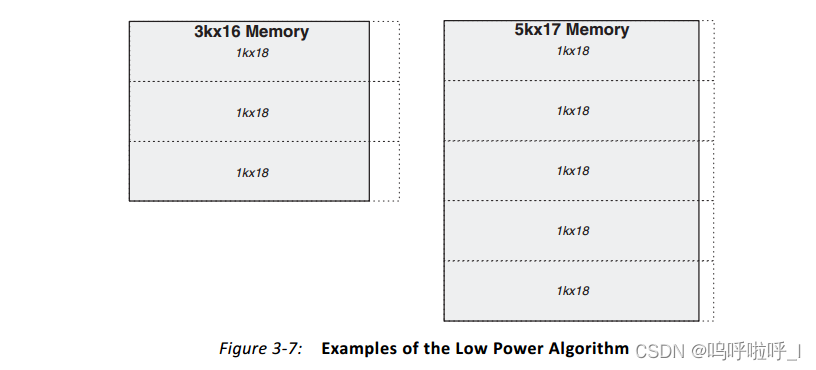
比如在上述3k×16的Memory中,3个1k×18的垂直方向排列,3个输出通过多路复用器输出到RAM外。当地址处于0-1k时只有上面一个RAM被启用,其余两个RAM不用使能,因此可以降低功耗。
- 固定原语
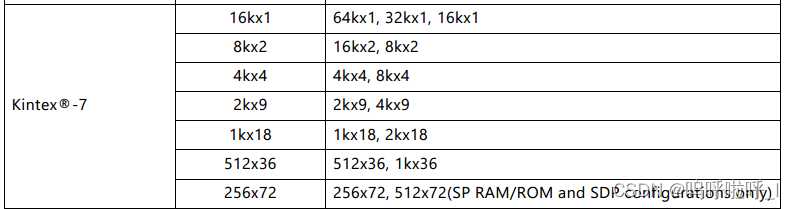
固定原语算法允许选择单个BRAM原语类型。内核通过在宽度和深度上连接这个单一的原语类型来构建内存。固定原语算法提供了16kx1、8kx2、4kx4、2kx9、1kx18和512x36原语的选择。

2.级联高度cascade_height综合属性
从上面的介绍我们可以发现,低功耗算法实际上是将多个RAM进行级联得到的,下面我们以32K×32bit的RAM为例,通过设置综合属性cascade_height来控制BRAM的级联高度,我们分别设置级联高度为1、32和8,所得结果如图所示:
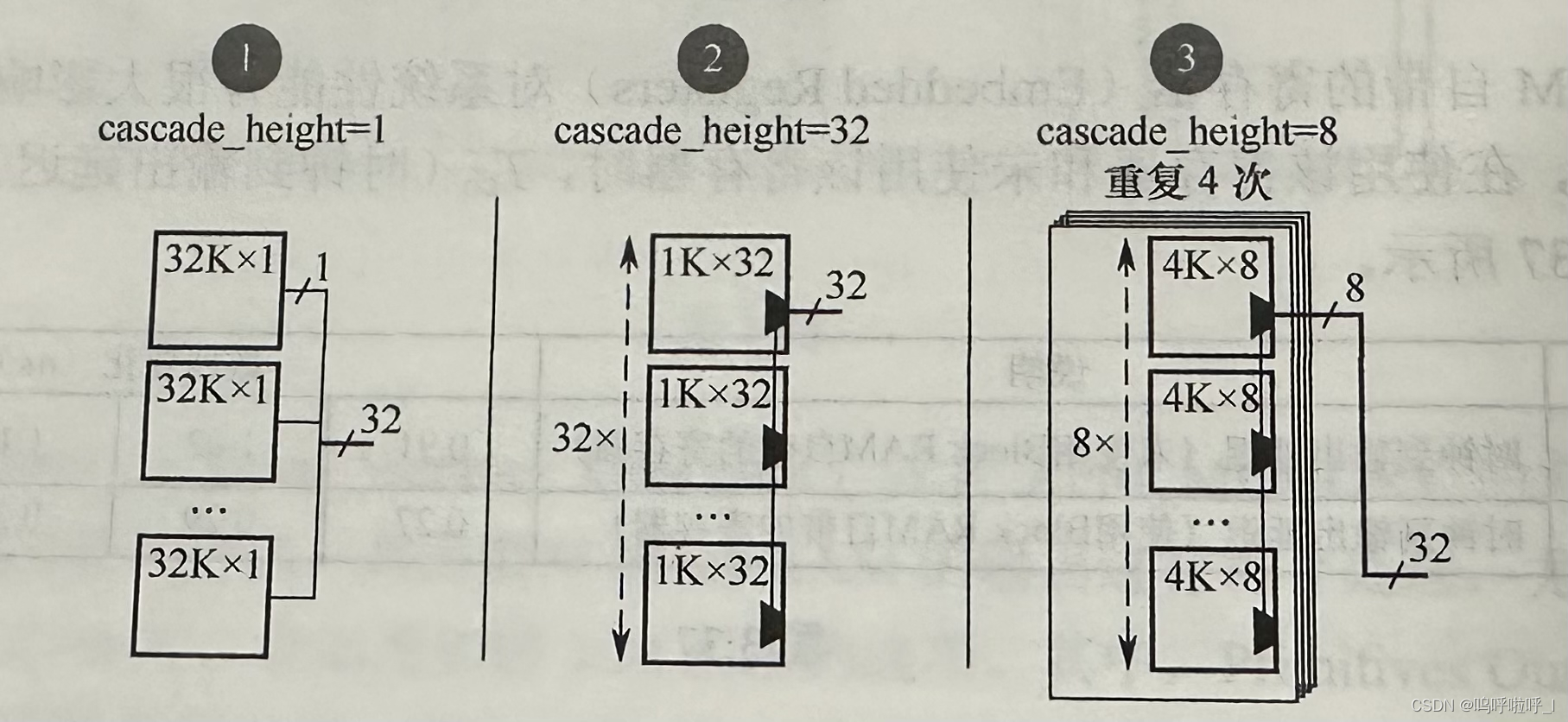
图中1和2的方式看似很像,那我们换个图来看看二者的差别:
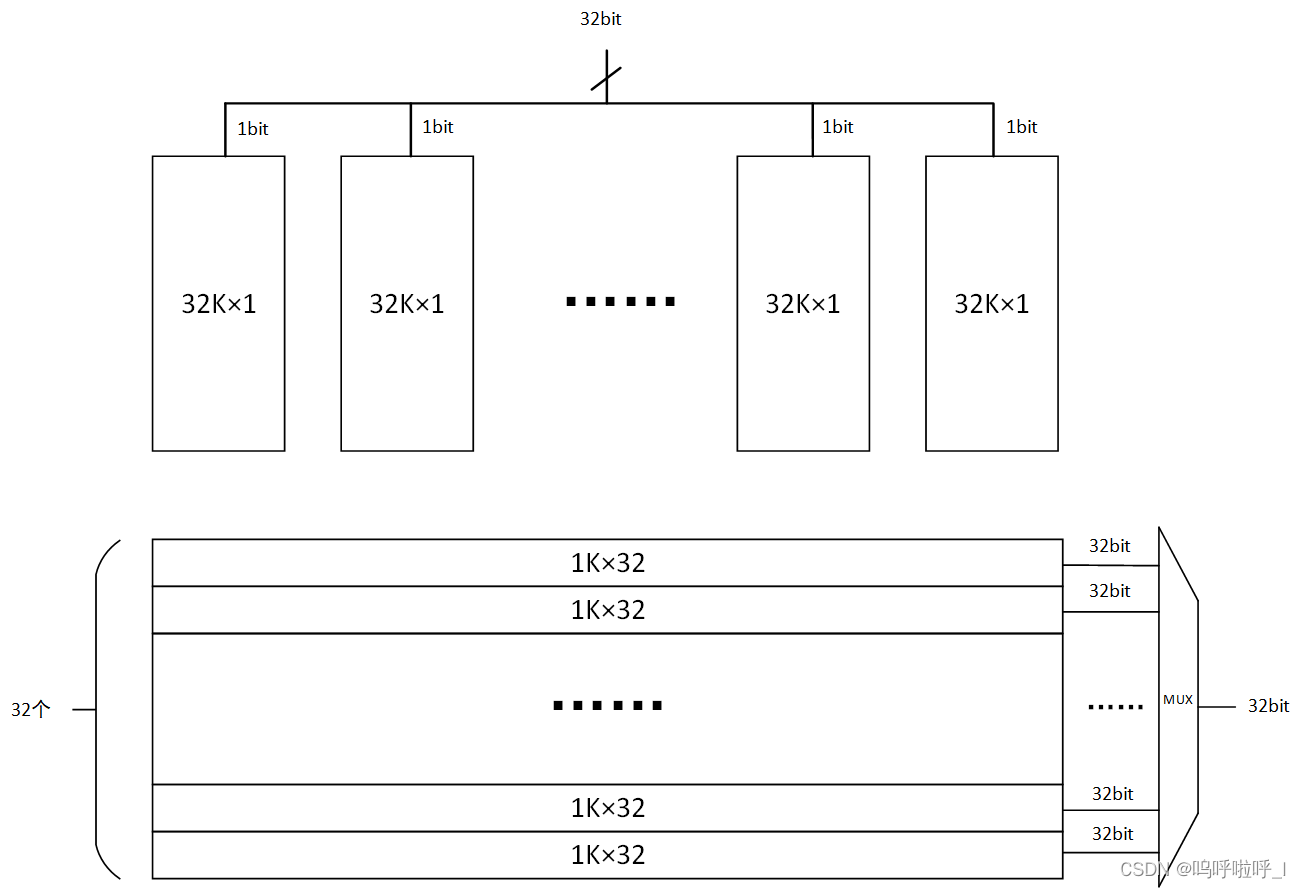
对于cascade_height=1的情况,在每一次读写地址时,每一个BRAM均被选通使能;而对于cascade_height=32的情况,在任何一次读写操作中,均只有一个RAM被宣统其他块不被使用,因此可以降低功耗。
那这样的话是不是cascade_height级联高度越大越好?当然不是,因为级联数越大,级联长度就越长,尽管有专用的级联走线,但毕竟要跨过时钟域,有可能无法实现;并且由于布线带来的延迟也可能会对时序造成很大影响。于是就有了图三的情况,在每一时刻激活4个RAM,既减小了功耗,又能够使走线带来的影响较小。
3.ram_decomp综合属性
这一节我们介绍一下ram_decomp综合属性,以8K×36bit为例:
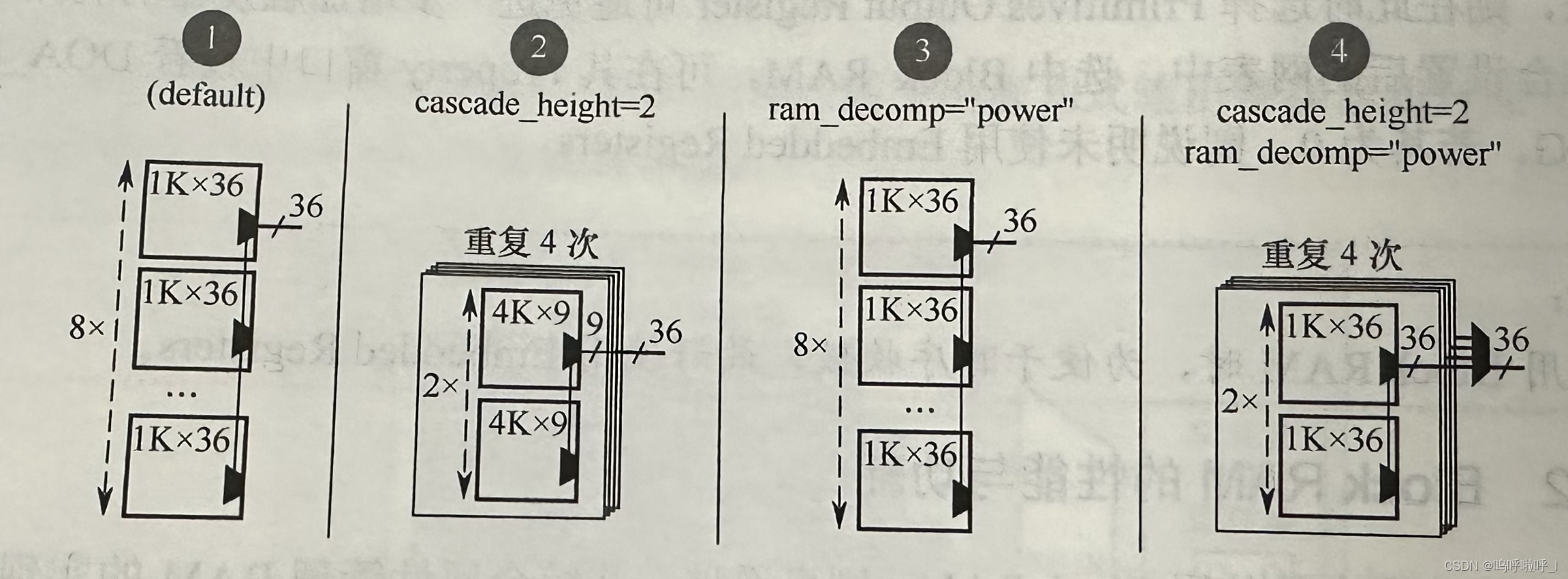
①和③的效果是一样的,我们来分析②和④,我们可以发现两者的级联数都是2,但是二者对RAM36B36E1的配置方式不同,一种将其配置为9bit位宽,一种将其配置为36bit位宽,那为什么采用ram_decomp="power"后的功耗更低呢?
这是因为在同一时刻,对于4K×9的实现方式来说,每一时刻会激活并排的4个RAM,而1K×36的实现方式每一时刻只用激活1个RAM即可。但是对于④这种方式来说需要更多的多路复用器,一方面它需要在一列的两个RAM中选择出一个RAM数据进行输出,另一方面他还需要从并排的同一列四个RAM中(因为可能需要输出的数据并不在第一个BANK的两个RAM中)选择一个RAM数据进行输出,会消耗更多的资源,面积相比之下会大于②这种实现方式。
下面给出上述四种方式的功耗和资源使用情况:
| 实现方式 | 功耗 | BRAMs | LUT |
|---|---|---|---|
| default | 0.597 | 8 | 24 |
| cascade_height=2 | 0.788 | 8 | 6 |
| ram_decomp=“power” | 0.597 | 8 | 24 |
| cascade_height=2 ram_decomp=“power” | 0.610 | 8 | 90 |
这篇关于Xinlinx FPGA如何降低Block RAM的功耗的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![[Linux Kernel Block Layer第一篇] block layer架构设计](https://i-blog.csdnimg.cn/direct/6f402f42143b4aac927657769404055e.png)