本文主要是介绍CSAPP | Floating Point,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CSAPP | Floating Point
b i b_i bi b i − 1 b_{i-1} bi−1 … b 2 b_2 b2 b 1 b_1 b1 b 0 b_0 b0 b − 1 b_{-1} b−1 b − 2 b_{-2} b−2 b − 3 b_{-3} b−3 … b − j b_{-j} b−j
S = ∑ k = − j i b k × 2 k S=\sum_{k=-j}^{i}b_k\times2^k S=∑k=−jibk×2k
IEEE Standard 754
浮点数表示方法
v = ( − 1 ) s × M × 2 E v=(-1)^s\times M\times 2^E v=(−1)s×M×2E
符号位 Sign: 0 表示正,1 表示负。
尾数 Significand M: ∈ [ 1.0 , 2.0 ) \in [1.0, 2.0) ∈[1.0,2.0)
阶码 exponent: E 对浮点数加权,权重为 2 的 E 次幂。
浮点数分为三个域:符号、阶码、 尾数
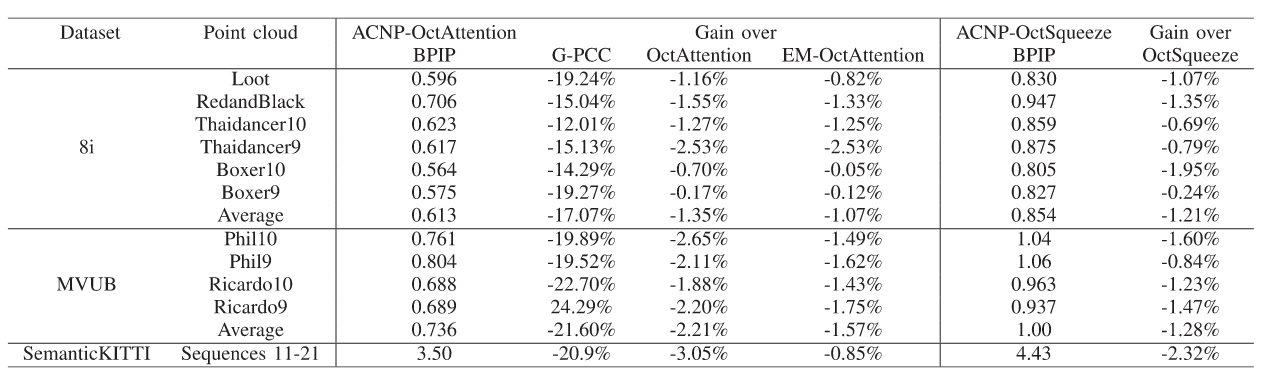
sign (1 bit) | exponent (e bit) | fraction(or mantissa) (f bit)
sign 直接编码符号 s
k 位阶码字段 e x p = e k − 1 . . . e 1 e 0 exp=e_{k-1}...e_1e_0 exp=ek−1...e1e0 编码了 E(但是不等同于 E)
n 位小数字段 f r a c = f n − 1 . . . f 1 f 0 frac=f_{n-1}...f_1f_0 frac=fn−1...f1f0 编码了 M(但是不等同于 M)
规格化值
1.exp ≠ \neq = 000…0 and exp ≠ \neq = 111…1
2.阶码字段以 biased(偏置) 形式表示,E = Exp - Bias,Exp 为无符号数,Exp 的范围为 00000001 ∼ 11111110 0000 0001 \sim 1111 1110 00000001∼11111110 即 1 ∼ 254 1 \sim 254 1∼254。Bias 为 2 k − 1 − 1 2^{k-1}-1 2k−1−1,由此产生的指数取值范围,单精度为 − 126 ∼ + 127 -126\sim +127 −126∼+127,双精度为 − 1022 ∼ + 1023 -1022\sim +1023 −1022∼+1023
3.小数字段 frac 被解释为描述小数值 f, f ∈ [ 0 , 1 ) f \in [0,1) f∈[0,1), 二进制表示为 0. f n − 1 . . . f 1 f 0 0.f_{n-1}...f_1f_0 0.fn−1...f1f0。尾数定义为 M = 1 + f M=1+f M=1+f。可以把 M 看作为二进制表示为 1. f n − 1 . . . f 1 f 0 1.f_{n-1}...f_1f_0 1.fn−1...f1f0。
4.对于尾数,我们可以“抛掉”小数点左边的 1,只看右侧。M 最小的时候 frac = 000…0(M = 1.0),M 最大的时候 frac = 111…1(M = 2.0 - ε \varepsilon ε,也就是 1.111…1)
IEEE754浮点数阶码为什么需要偏置bias
Single precision: 32 bits
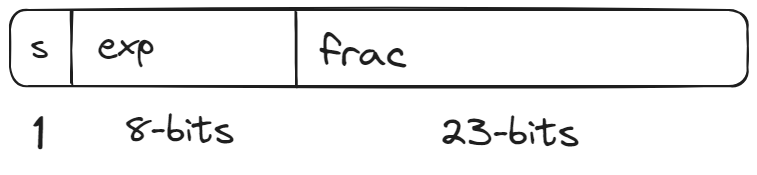
Double Precision: 64 bits
Example
对于浮点数 F = 15213.0
1521 3 10 15213_{10} 1521310
= 1110110110110 1 2 = 1110 1101 1011 01_2 =111011011011012
= 1.110110110110 1 2 × 2 13 =1.110 1101 1011 01_2 \times 2^{13} =1.11011011011012×213
Significand
M = 1.110110110110 1 2 M=1.110 1101 1011 01_2 M=1.11011011011012
f r a c = 1101101101101000000000 0 2 frac=110 1101 1011 01 0000 0000 00_2 frac=110110110110100000000002(23 bits)
Exponent
E = 13 E = 13 E=13 因为 2 的幂是 13
B i a s = 127 Bias=127 Bias=127 因为 float 单精度表示,k = 8, B i a s = 2 k − 1 − 1 = 2 7 − 1 = 127 Bias=2^{k-1}-1=2^7-1=127 Bias=2k−1−1=27−1=127
E x p = 140 = 1000110 0 2 = E + B i a s Exp=140=10001100_2=E + Bias Exp=140=100011002=E+Bias
Result
0 10001100 1101101101101000000000 0 2 0~~10001100~110 1101 1011 01 0000 0000 00_2 0 10001100 110110110110100000000002
从左到右分别为 s exp frac
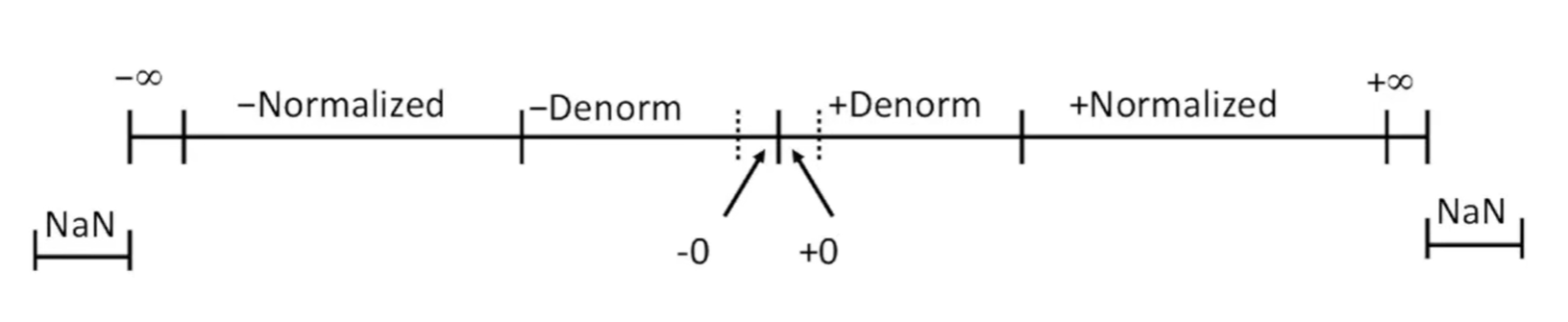
非规格化值
如果使用规格化数,总是使 M ≥ 1 M \geq 1 M≥1,就无法表示 0。而 +0.0 的浮点表示位模式为全 0。符号位为 0,阶码字段为 0,是一个非规格化值。然而此时 M = f = 0。如果符号位为 1,那么就是 -0.0。
1.exp = 000…0 成立
2.E = 1 - Bias
3.M = 0.xxx…x
特殊的值
e x p = 111...1 , f r a c = 000...0 exp = 111...1, frac=000...0 exp=111...1,frac=000...0 代表无穷大
e x p = 111...1 , f r a c ≠ 000...0 exp=111...1,frac\neq 000...0 exp=111...1,frac=000...0 N a N ( n o t a n u m b e r ) NaN(not~a~number) NaN(not a number) E.g. sqrt(-1)
Visualization: Floating Point Encodings
对于 8 位浮点数:
k = 4 , B i a s = 2 3 − 1 = 7 , E = 1 − B i a s = 1 − 7 = − 6 k = 4, Bias=2^3-1=7,E = 1-Bias=1-7=-6 k=4,Bias=23−1=7,E=1−Bias=1−7=−6
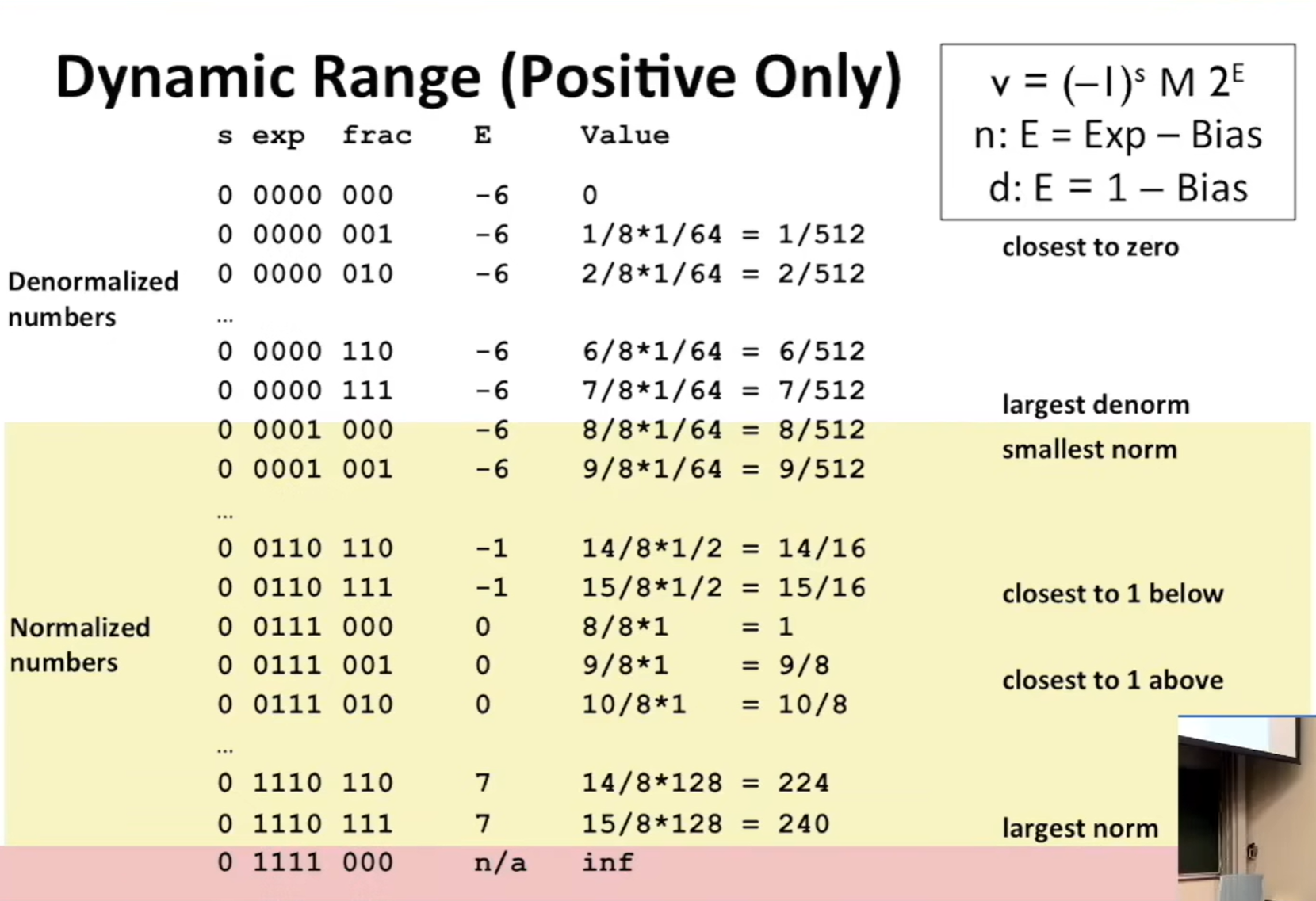
对于非规格化值:
E = 1 − B i a s E=1-Bias E=1−Bias
0 0000 000,M = 0, 0 × 2 − 6 = 0 0 \times 2^{-6} = 0 0×2−6=0
0 0000 001, M = 1 × 2 − 3 = 1 8 , 1 8 × 1 2 6 = 1 512 M=1\times 2^{-3}=\frac{1}{8}, \frac{1}{8} \times \frac{1}{2^6} = \frac{1}{512} M=1×2−3=81,81×261=5121
…
0 0000 111 为非规格化值所能表示的最大值
对于规格化值:
E = e x p − B i a s E=exp-Bias E=exp−Bias
0 0001 000 此时 e x p = 1 , E = e x p − B i a s = 1 − 7 = − 6 , f r a c = 000 , M = 1.000 exp=1, E=exp-Bias=1-7=-6,frac=000,M=1.000 exp=1,E=exp−Bias=1−7=−6,frac=000,M=1.000,这是最小的规格化值。
…
Rounding
IEEE 现在有四种舍入方式,分别为 向零舍入、向下舍入、向上舍入、就近舍入(默认)
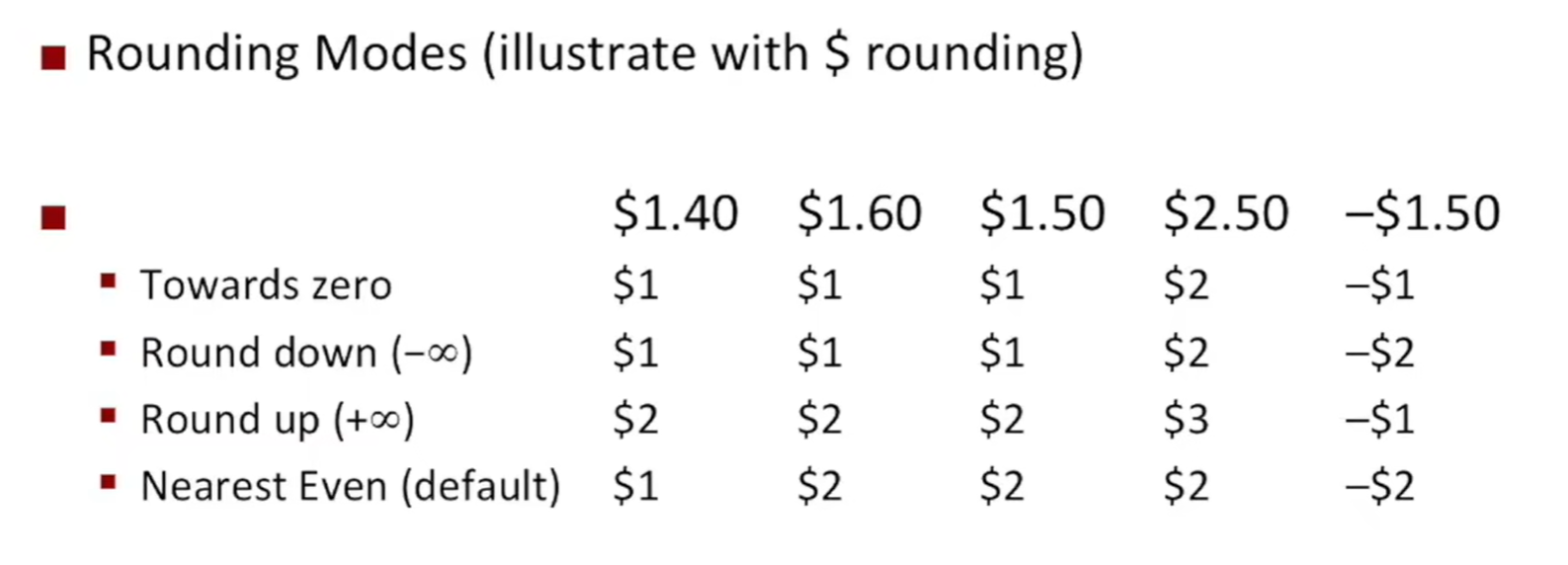
如何理解就近舍入?
当为中间数,要向最近的偶数(舍入后保留的最低有效位是偶数)舍入。

对于 7.8950000,9 是一个奇数,所以向上舍入。
对于 7.8850000,8 是一个偶数,所以向下舍入。
二进制数截断

对于 10.1110 0 2 10.11100_2 10.111002 如果直接截断,则为 10.11 是个奇数,所以应该加上 0.001
乘法
( ( − 1 ) s 1 × M 1 × 2 E 1 ) × ( ( − 1 ) s 2 × M 2 × 2 E 2 ) ((-1)^{s1}\times M1 \times 2^{E1}) \times ((-1)^{s2}\times M2 \times 2^{E2}) ((−1)s1×M1×2E1)×((−1)s2×M2×2E2)
S i g n s : s 1 ⊕ s 2 Sign~s: s1 \oplus s2 Sign s:s1⊕s2
S i g n i f i c a n d M : M 1 × M 2 Significand~M:M1 \times M2 Significand M:M1×M2
E x p o n e n t E : E 1 + E 2 Exponent~E: E1 + E2 Exponent E:E1+E2
如果 M ≥ \geq ≥ 2,则须有右移位同时增加指数,来让尾数在 1 和 2 之间。
如果 E 超出范围,则会溢出到无穷大。
如果 M 有太多位,则需要就近舍入。
(3.14 + 1e10) - 1e10 = 0
3.14 + (1e10 - 1e10) = 3.14
1e20 ∗ * ∗ (1e20 - 1e20) = 0.0
Questions
int x = ...;
float f = ...;
double d = ...;x == (int)(float) x; // False, 在浮点数的 frac 区域没有足够的位来表示 int,会舍入
x == (int)(double) x; // True
f == (float)(double) f; // True
d == (double)(float) d; // False
f == -(-f); // True
2 / 3 == 2 / 3.0 // False, 2/3=0, 2/3.0 是一个浮点数
d < 0.0 -> ((d * 2) < 0.0) // Yes, 即使 d * 2 溢出到负无穷大,也是小于 0
d > f -> -f > -d // Yes
d * d >= 0.0 // Yes
(d + f) - d == f // No
这篇关于CSAPP | Floating Point的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


![[学习笔记]《CSAPP》深入理解计算机系统 - Chapter 3 程序的机器级表示](/front/images/it_default.gif)