本文主要是介绍更新-上市公司董事会多样性指标计算参考SMJ2021(代码+数据)1990-2022年,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01、数据介绍
董事会多样性(Board Diversity)是指公司董事会成员在性别、年龄、种族、教育背景、专业技能、国籍等方面的多元化程度。多样性的董事会能够为公司带来更广泛的观点、经验和技能,有助于提高公司的战略决策质量和创新能力。同时,董事会多样性也有助于增强公司的社会责任感和公众形象。
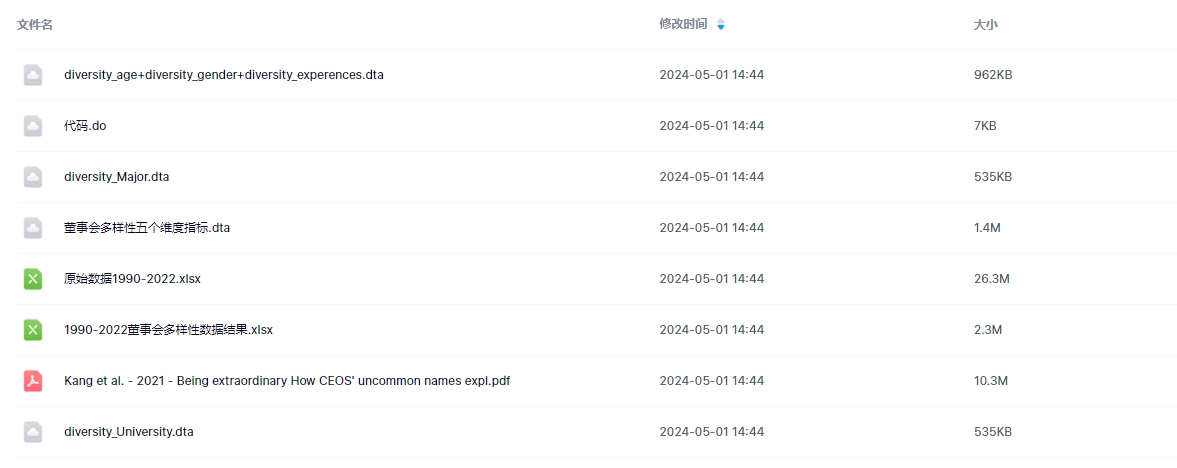
本数据包含:原始数据、stata代码、指标数据。
数据名称:董事会多样性数据
数据年份:1990-2022年
02、包含指标
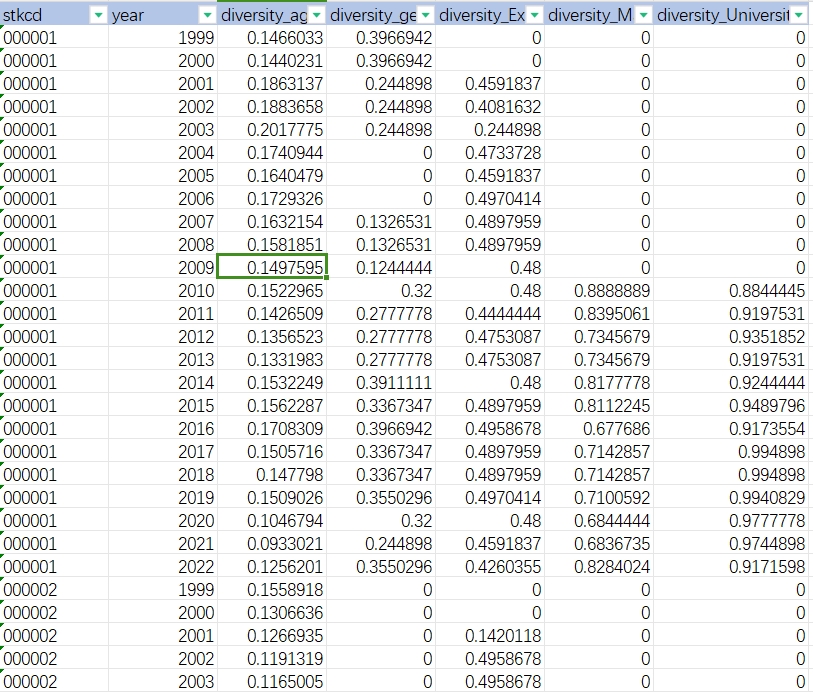
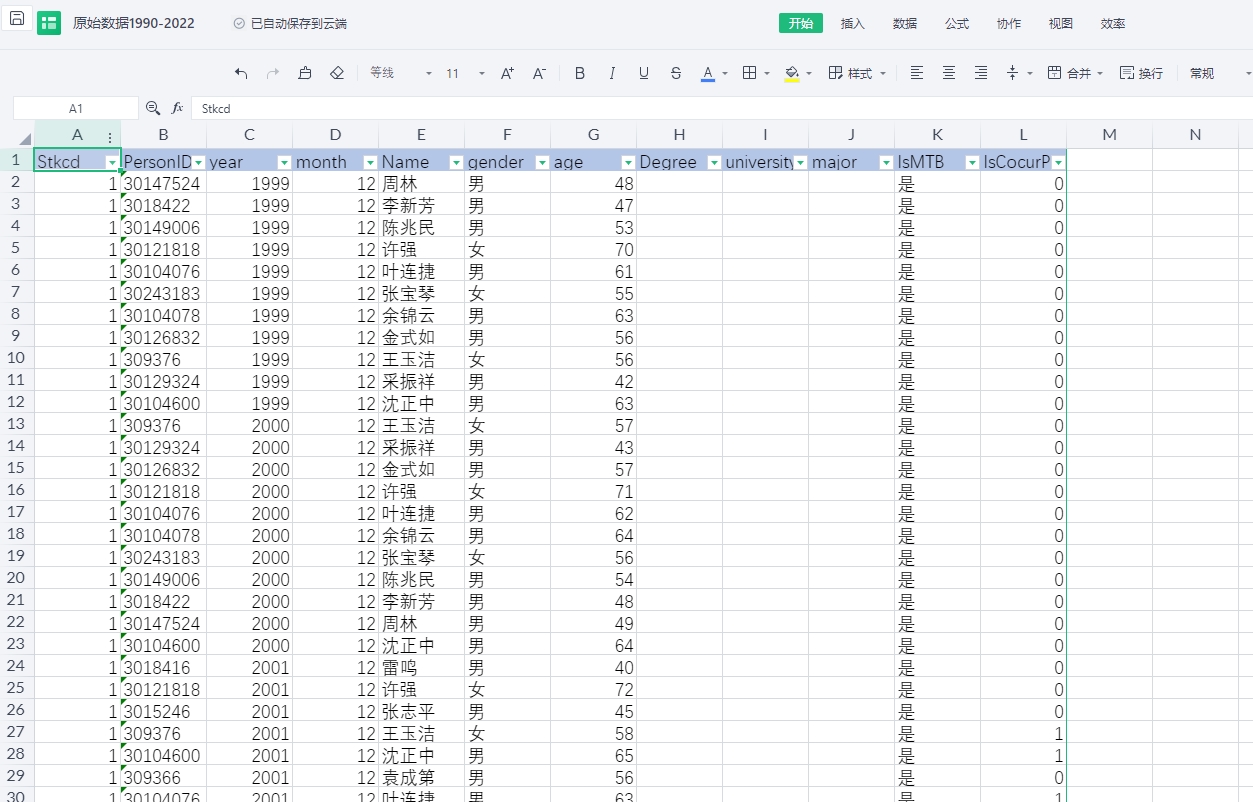
stkcd、year、diversity_age(董事会成员年龄多样性)、diversity_gender(董事会成员性别多样性)、diversity_Experience(董事会成员经验多样性)、diversity_Major(董事会成员专业多样性)、diversity_University(董事会成员教育背景多样性)。
03、样例数据
04、包含内容
05、全部数据下载链接:https://download.csdn.net/download/samLi0620/89249876
这篇关于更新-上市公司董事会多样性指标计算参考SMJ2021(代码+数据)1990-2022年的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







