本文主要是介绍数据挖掘之基于Lightgbm等多模型消融实验的信用欺诈检测实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
文章目录
- 一项目简介
- 二、功能
- 三、系统
- 四. 总结
一项目简介
一、项目背景
在当前的金融环境中,信用欺诈行为日益增多,给金融机构和消费者带来了巨大的损失。为了有效地检测和预防信用欺诈,金融机构急需一种高效、准确的方法。本项目旨在利用数据挖掘技术和LightGBM等多模型进行消融实验,以实现信用欺诈检测。
二、项目目标
利用数据挖掘技术,收集并整合与信用欺诈相关的各类数据,构建高质量的数据集。
基于LightGBM等多模型,构建信用欺诈检测模型,并通过消融实验验证各模型的关键组成部分对整体性能的影响。
通过对模型性能的评估和优化,选择最佳的信用欺诈检测模型,并实现其在实际业务中的应用。
为金融机构提供一套有效的信用欺诈检测解决方案,降低欺诈风险,保护消费者权益。
三、技术实现
数据收集与预处理:收集与信用欺诈相关的各类数据,包括用户交易记录、个人信息、行为特征等,并进行数据清洗、去噪、标准化等预处理操作,以提高数据质量。
特征选择与提取:根据数据特点,选择合适的特征进行提取,如交易金额、交易频率、用户行为模式等。同时,可以利用特征工程技术对特征进行转换和优化,以提高模型的预测能力。
模型构建与训练:基于LightGBM等多模型,构建信用欺诈检测模型。在模型训练过程中,采用消融实验的方法,逐步删除或修改模型的特定部分,以观察这些变化如何影响模型的性能。通过对比不同模型的性能,选择最佳的信用欺诈检测模型。
模型评估与优化:利用交叉验证等技术手段对模型进行评估,并根据评估结果对模型进行优化。优化过程包括调整模型参数、改进特征选择方法、引入新的技术等。
系统实现与部署:将优化后的模型集成到实际的业务系统中,实现信用欺诈检测功能的自动化和实时化。同时,提供友好的用户界面和交互方式,方便用户进行操作和管理。
四、项目特点
多模型融合:本项目采用LightGBM等多模型进行信用欺诈检测,通过消融实验验证各模型的关键组成部分对整体性能的影响,从而选择最佳的模型组合。这种多模型融合的方法能够充分利用不同模型的优点,提高检测的准确性和效率。
消融实验验证:本项目采用消融实验的方法验证模型的关键组成部分对整体性能的影响。这种方法有助于深入理解模型的工作原理和性能瓶颈,为模型的优化提供有价值的见解。
实时性与准确性:本项目将优化后的模型集成到实际的业务系统中,实现信用欺诈检测的自动化和实时化。同时,通过严格的数据预处理和特征选择技术,确保模型的准确性和稳定性。
可扩展性与可维护性:本项目采用模块化设计和可配置化策略,使得系统具有良好的可扩展性和可维护性。随着业务的发展和数据量的增加,可以方便地对系统进行扩展和升级。
二、功能
数据挖掘之基于Lightgbm等多模型消融实验的信用欺诈检测实现
三、系统
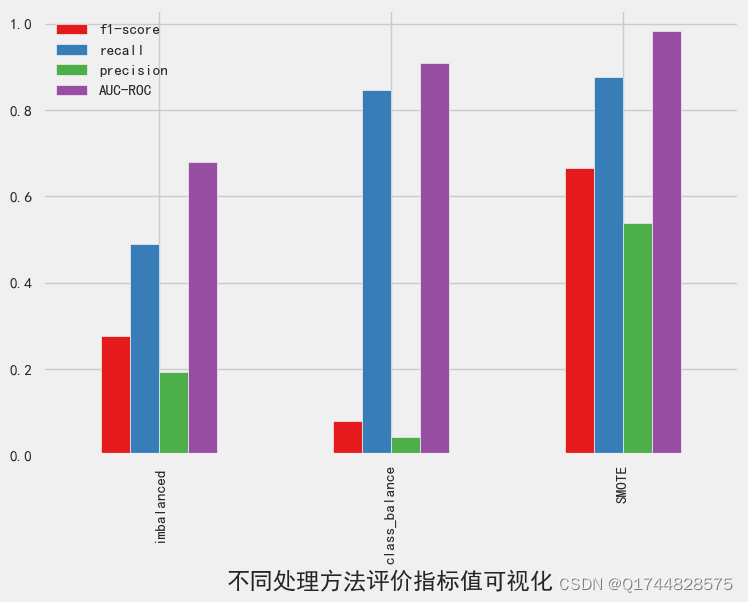
四. 总结
本项目的研究成果可以广泛应用于金融机构的信用欺诈检测领域,为金融机构提供一套有效的解决方案。通过实时、准确地检测信用欺诈行为,降低欺诈风险,保护消费者权益,提高金融机构的业务效率和竞争力。同时,随着大数据和人工智能技术的不断发展,本项目所采用的数据挖掘技术和模型优化方法将具有更广泛的应用前景。
这篇关于数据挖掘之基于Lightgbm等多模型消融实验的信用欺诈检测实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






