本文主要是介绍优秀博士学位论文分享:大规模预训练语言模型的高效适配技术研究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
优秀博士学位论文代表了各学科领域博士研究生研究成果的最高水平,本公众号近期将推出“优秀博士学位论文分享”系列文章,对人工智能领域2023年优秀博士学位论文进行介绍和分享,方便广大读者了解人工智能领域最前沿的研究进展。
“博士学位论文激励计划”(原优秀博士学位论文奖)是对博士研究生学位论文的一项重大奖励,由各大学会通过严格评选后颁布。中国计算机学会、中国自动化学会、中国人工智能学会等各大学会每年都会颁布该奖项。该奖项的目的是促进学术研究的卓越性,并鼓励产出高质量的博士论文。博士研究生如果能够荣获该奖项,则表明其学术研究生涯早期的成果受到了很高的认可。
本文主要介绍清华大学丁宁博士的研究成果,其博士论文《大规模预训练语言模型的高效适配技术研究》在预训练语言模型的适配技术领域取得了显著成就。该论文从模型适配的数据高效和计算高效两个角度出发,研究了预训练模型在下游任务的适配问题,特别是在数据量不足的情况下如何高效适配。此外,丁宁博士还在模型的数据高效和计算高效两个维度上,分别开发了统一范式的提示学习系统 OpenPromp和统一范式的增量微调系统 OpenDelta。这两个开源系统的构建,推动了大规模预训练语言模型的应用落地,为该领域的发展做出了显著贡献。目前该论文已获得“博士学位论文激励计划”奖项。此外,本文还对其指导老师郑海涛教授进行了介绍,以方便读者了解更多相关信息。本文的作者为许东舟,审校为朱旺和陆新颖。
一、论文介绍
自1956年人工智能学科确立以来,自然语言处理始终是其核心领域之一。自然语言处理的发展历程如图1所示。近年来,预训练语言模型的迅速发展正在重新定义自然语言处理的基本框架。这类模型首先在大规模的无标注语料中进行预训练,然后通过各种训练策略进一步适配到各类下游任务中。适配作为将预训练语言模型部署到特定任务的重要一环,通过特定的适配方式,模型可以在文本分类、文本生成、文本摘要、文本翻译、命名实体识别等任务中取得更好的表现,同时使得其输出具有更强的稳定性和鲁棒性,并且与人类的价值观对齐。

图1 自然语言处理的技术范式发展历程
然而,随着模型规模的不断增大,大规模预训练模型的适配面临着严峻的挑战。如何使模型在数据有限的情况下有效泛化,以及如何降低其昂贵的训练和存储成本,成为了迫切需要解决的关键问题。针对以上问题,丁宁博士从模型数据高效适配和计算高效适配两个方向展开了研究,具体框架如图2所示。基于所提出的研究问题和应用的具体方法,本文的研究内容主要分为数据高效的模型适配、计算高效的模型适配和开源系统构建三个部分,文章的组织结构如图3所示。

图2 学位论文研究内容的框架图

图3 学位论文各章节的组织结构
1.1 数据高效适配
(1) 增强表示能力
a) 基于球面原型的表示学习方法:原型表示学习以知识获取中的关系抽取任务为落脚点,对大规模预训练语言模型进行数据高效的适配,图4为原型表示学习的示意图。本方法在此类语料上训练一个原型编码器以学习准确的关系表示,然后在精标注数据稀缺的下游任务上进行精调。这种方法在处理少量标注数据的任务上特别有效,能够利用有限的信息实现较好的分类性能,比如在少样本或零样本学习中,通过有效利用有限的标注信息来提升分类性能。
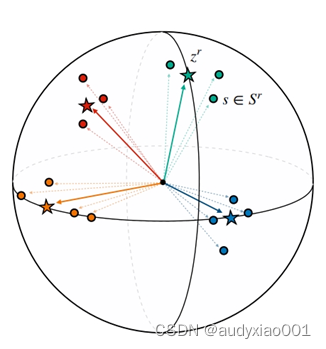
图4 原型表示学习示意图
b) 基于超球原型的表示学习方法:超球原型是一种从几何角度出发,使用超球来建模类别表示的表示学习方法,建模示意图如图5所示。几何建模可以同时增强表示的表达能力和降低度量计算的难度,同时在少样本分类中产生出人意料的表现。这种方法的优点是只使用中心和半径两组可学习参数来表示一个超球。超球比表示空间中的单个点更具有表达能力,并且可学习的半径参数之后还可以将这种表达能力进一步提高。此外,除了度量设计的简单性和更强的表达能力外,超球原型也十分容易训练。
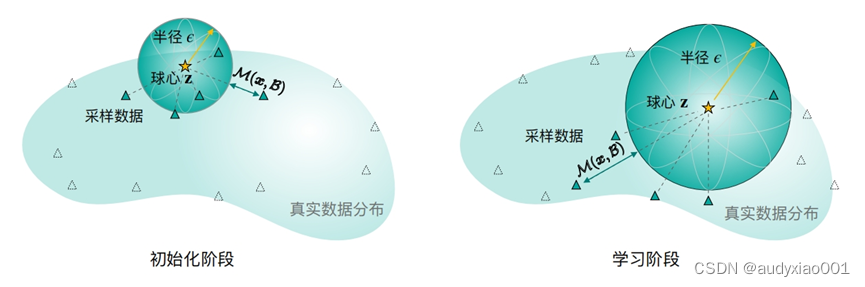
图5 超球原型建模的示意图
(2) 挖掘通用信息
a) 数据高效的细粒度实体识别数据集 Few-NERD:本文提出了一个名为Few-NERD的大规模人工标注的少样本命名实体识别数据集。该数据集从维基百科文章提取,包含18.82万个句子和48.61万个实体,所有实体均由经过良好训练的标注员手动标注。Few-NERD是目前最大的人工标注命名实体识别数据集之一,Few-NERD 的实体类型非常多样化,这使得该数据集包含了更细粒度的上下文特征,可以更好地用于评测少样本命名实体识别。Few-NERD中实体类型的分布如图6所示。包含8个粗粒度实体类型和66个细粒度实体的类别体系。
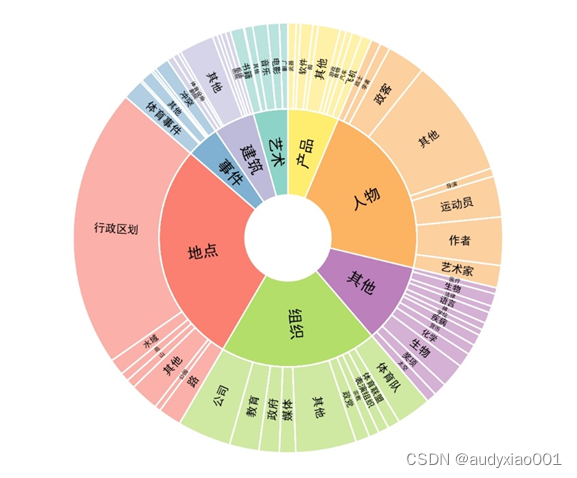
图6 Few-NERD实体类型分布
b) 基于提示学习的细粒度实体分类模型:文中以细粒度实体分类任务为基点,提出了基于提示学习的方法,包含了一个朴素的提示学习方法和一个自监督学习框架。这个框架在 Few-NERD 等一众有挑战性的数据集上取得了非常好的效果,特别是在监督数据不足的情况下。
1.2 计算高效适配
(1) 发展统一范式
论文提出了增量微调(Delta Tuning)框架,采用一个统一的视角来看待和分析模型的参数高效微调方法,该统一框架如图7所示。并针对增量微调进行了大量的理论和实验分析。在理论方面,分别从优化和最优控制两个角度来阐述了增量微调,为进一步理解大规模预训练语言模型的机理提供了新的视角。在实验方面,对增量微调进行了全面的分析,从效果、收敛性、泛化误差、计算效率、组合性、模型规模的影响、迁移性等多个角度进行了全面的评测,在这几个方面均得出了前沿的实验结论。
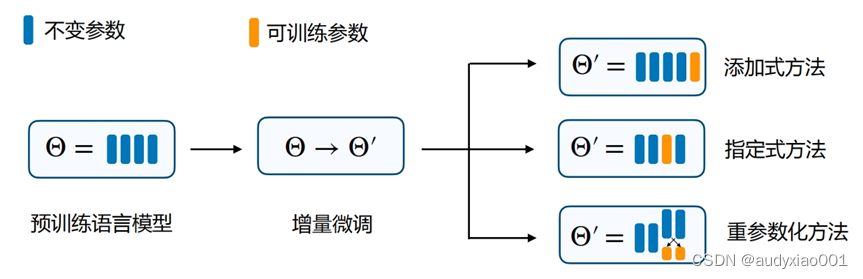
图7 统一框架下的增量微调方法
(2) 进阶计算高效
在增量微调的统一框架上,探索了进一步对大规模预训练模型执行计算高效适配的方法。在训练之前,使用现有的已存在的轻量级对象来对新任务的增量微调进行初始化,以更好地实现知识迁移。在训练之中,首先将二阶优化成功地应用在了大规模预训练语言模型的训练过程中,在理论和实验分析之后,提出了牛顿步裁剪法来稳定实验效果,进一步加速了大规模预训练语言模型适配过程的收敛。
1.3 开源系统构建
提出针对数据高效的提示学习系统OpenPrompt和针对计算高效的增量微调系统OpenDelta,二者都是领域内的首个统一范式系统。OpenPrompt负责将训练流程和输入输出组织成提示学习的方式,而OpenDelta负责具体的增量微调优化,二者相辅相成,协同构成一个完整的高效适配系统,如图8所示。
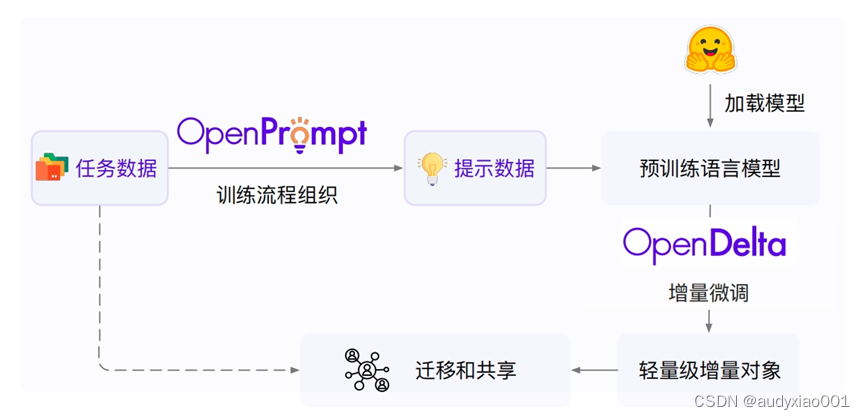
图8 OpenPrompt 和 OpenDelta 的协同工作框架
二、个人成果
丁宁博士是清华大学计算机科学与技术专业的毕业生,在他的博士学业生涯中,不仅以第一(以及共一)作者的身份发表了多篇学术论文和专利,还在Github上开源了若干项目。他的研究成果展现了出色的学术深度和应用广度,为他获得CCF优秀博士学位论文奖项打下了坚实的基础。具体成果如表1所示。
表1 博士生涯成果
| 成果类型 | 成果 | 类型 |
|---|---|---|
| 学术论文 | Parameter-efficient Fine-tuning for Large Language Models | Nature Machine Intelligence |
| An open-source framework for promptlearning | ACL | |
| DeepEye: Towards Automatic Data Visualization | EMNLP | |
| A Few-shot Named Entity Recognition Dataset | ACL | |
| Prototypical Representation Learning for Relation Extraction | ICLR | |
| Coupling Distant Annotation and Adversarial Training for Cross-Domain Chinese Word Segmentation | ACL | |
| Event Detection with Trigger-Aware Lattice Neural Network | EMNLP | |
| Few-shot Classification with Hypersphere Modeling of Prototypes | ACL | |
| Exploring Lottery Prompts for Pre-trained Language Models | ACL | |
| Parameter-efficient Weight Ensembling Facilitates Task-level Knowledge Transfer | ACL | |
| CLINE: Contrastive Learning with Semantic Negative Examples for Natural Language Understanding | ACL | |
| Chinese Relation Extraction with Multi-Grained Information and External Linguistic Knowledge | ACL | |
| Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification | ACL | |
| Modeling Relation Paths for Knowledge Graph Completion | TKDE | |
| Sparse Structure Search for Parameter-Efficient Tuning | NeurIPS | |
| Prototypical Verbalizer for Prompt-based Few-shot Tuning | ACL | |
| Pre-trained Models: Past, Present and Future | AI Open | |
| 专利 | 一种中文关系抽取方法 | 授权专利 |
| 开源项目 | 统一范式的提示学习系统 | Github 3800星标 |
| 提示学习论文导读 | Github 3300星标 | |
| 大规模多轮指令数据和模型 UltraChat | Github 1800星标 | |
| 统一范式的增量微调系统 OpenDelta | Github 695星标 | |
| 少样本命名实体识别评测基准和实现框架 Few-NERD | Github 334星标 | |
| 百亿参数中英双语基座预训练语言模型 CPM-Bee | Github 2600星标 | |
| 融合外部语义知识的知识获取系统 ChineseNRE | Github 260星标 | |
| 增量微调论文导读 | Github 220星标 |
三、指导老师——郑海涛教授简介
郑海涛教授的研究方向包括网络科学、语义网、信息检索、机器学习、医疗信息及人工智能等。带领团队所获研究成果处于世界领先地位并已经得到了国内外同行的认可,在国际顶级会议/期刊上共发表论文80余篇,其中在人工智能顶级期刊/会议发表33篇论文,包括CCF A类/清华计算机A类论文19篇,JCR一区SCI期刊11篇。谷歌学术总被引用数8457次。曾担任国家863项目的副组长,主持国家自然科学基金4项,负责教育部博士点基金1项,广东省自然科学基金项目2项,深圳市基础研究重点项目2项。代表作之一ShuffleNet V2获得2019年VALSE年度杰出学生论文奖,与腾讯AI Lab合作研究课题《融合多类型多知识结构的预训练神经网络语言模型》在2020年度腾讯AI Lab犀牛鸟专项研究计划结题评优交流会中,荣获技术创新奖(全国仅2名)。如需进一步了解郑海涛教授的详细信息,欢迎访问他的个人主页:https://www.sigs.tsinghua.edu.cn/zht/main.htm。
这篇关于优秀博士学位论文分享:大规模预训练语言模型的高效适配技术研究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






