本文主要是介绍【数据结构】最小生成树(Prim算法、Kruskal算法)解析+完整代码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
5.1 最小生成树
-
定义
对一个带权连通无向图 G = ( V , E ) G=(V,E) G=(V,E),生成树不同,每棵树的权(即树中所有边上的权值之和)也可能不同。
设R为G的所有生成树的集合,若T为R中边的权值之和最小的生成树,则T称为G的最小生成树(MST)。
-
性质
1.最小生成树可能有多个,但边的权值之和总是唯一且最小的;
2.最小生成树的边数=顶点数-1。砍掉一条则不连通,增加一条会出现回路;
3.如果一个连通图本身就是一棵树,则其最小生成树就是它本身;
4.只有连通图才有最小生成树,非连通图只有生成森林。
5.1.1 Prim算法
-
定义
从某一个顶点开始构建生成树;
每次将代价最小的新顶点纳入生成树,直到所有顶点都纳入为止。
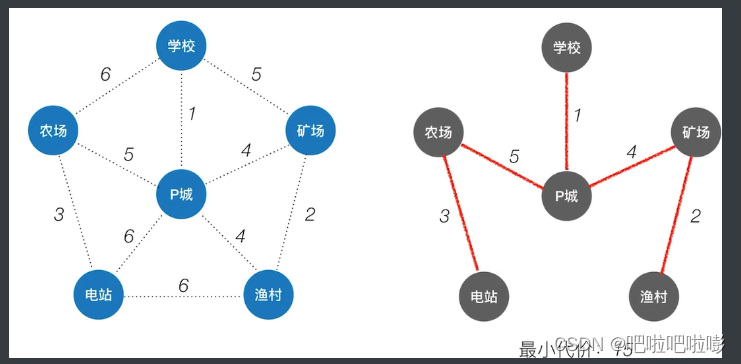
- 即选最小权值的结点
-
时间复杂度
O ( ∣ V ∣ 2 ) O(|V|^2) O(∣V∣2),适用于稠密图(|E|大的)。
-
算法的实现思想
-
思路:
从 V 0 V_0 V0开始,总共需要n-1轮处理。
第一轮处理:循环遍历所有个结点,找到
lowCast最低的,且还没加入树的顶点。再次循环遍历,更新还没加入的各个顶点的
lowCast值。 -
代码步骤:
1.创建
isJoin数组,初始为false,判断结点是否加入树。2.创建
lowCost数组,用于存储到该结点的最短距离。3.从 v 0 v_0 v0开始,将与其连接的权值加入到
lowCost数组中。4.遍历
lowCast数组,找到最小值,将其加入树中,并继续遍历与其相连的边。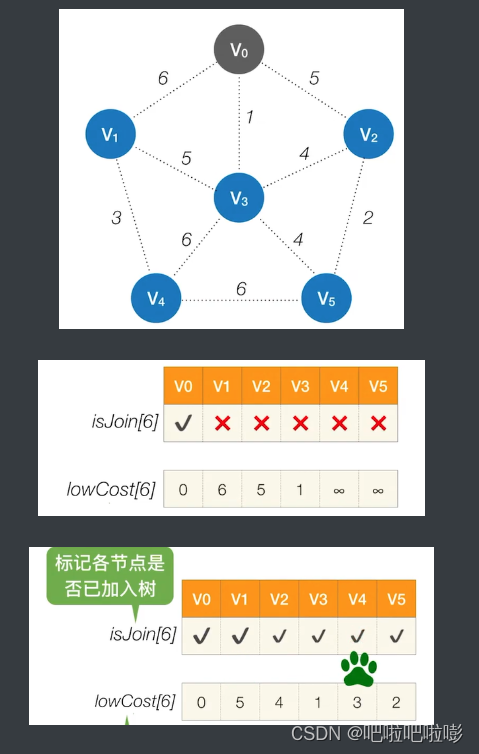
-
5.1.2 Kruskal算法
-
定义
每次选则一条权值最小的边,使这条边的两头连通(原本已经连通的不选),直到所有结点都连通。

- 即每次选最小的边
-
时间复杂度
O ( ∣ E ∣ l o g 2 ∣ E ∣ ) O(|E|log_2|E|) O(∣E∣log2∣E∣),适用于边稀疏图。
-
算法的实现思想
-
思路:
初始:将各条边按权值排序。
共执行e轮,每轮判断两个顶点是否属于同一集合,需要 O ( l o g 2 e ) O(log_2e) O(log2e)
-
5.1.3 最小生成树代码
A.邻接矩阵
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <limits.h>#define V 5 // 图的顶点数// 找到距离集合最近的顶点
int min_key(int key[], bool mst_set[]) {int min = INT_MAX, min_index;for (int v = 0; v < V; v++) {if (mst_set[v] == false && key[v] < min) {min = key[v];min_index = v;}}return min_index;
}// 打印最小生成树
void print_mst(int parent[], int graph[V][V]) {printf("Edge Weight\n");for (int i = 1; i < V; i++)printf("%d - %d %d \n", parent[i], i, graph[i][parent[i]]);
}// Prim算法
void prim_mst(int graph[V][V]) {int parent[V]; // 存放最小生成树的父节点int lowCost[V]; // 用于存放顶点到最小生成树的最小权重bool isJoin[V]; // 记录顶点是否已经加入最小生成树for (int i = 0; i < V; i++) {lowCost[i] = INT_MAX;isJoin[i] = false;}lowCost[0] = 0; // 初始点为0parent[0] = -1; // 根节点没有父节点for (int count = 0; count < V - 1; count++) {int u = min_key(lowCost, isJoin);isJoin[u] = true;for (int v = 0; v < V; v++) {if (graph[u][v] && !isJoin[v] && graph[u][v] < lowCost[v]) {parent[v] = u;lowCost[v] = graph[u][v];}}}print_mst(parent, graph);
}// Kruskal算法// 结构体用于表示边
struct Edge {int src, dest, weight;
};// 比较函数,用于排序
int compare(const void* a, const void* b) {return ((struct Edge*)a)->weight - ((struct Edge*)b)->weight;
}// 查找函数,用于查找集合的根节点
int find(int parent[], int i) {if (parent[i] == -1)return i;return find(parent, parent[i]);
}// 合并函数,用于合并两个集合
void Union(int parent[], int x, int y) {int xset = find(parent, x);int yset = find(parent, y);parent[xset] = yset;
}// Kruskal算法
void kruskal_mst(int graph[V][V]) {struct Edge result[V]; // 用于存放最小生成树的边int e = 0; // 表示result数组中的边数int i = 0; // 表示当前考虑的边// 边集合struct Edge edges[V*V];for (int u = 0; u < V; u++) {for (int v = u + 1; v < V; v++) {if (graph[u][v] != 0) {edges[e].src = u;edges[e].dest = v;edges[e].weight = graph[u][v];e++;}}}// 根据权重对边进行排序qsort(edges, e, sizeof(edges[0]), compare);int parent[V]; // 用于记录每个顶点的父节点for (int v = 0; v < V; v++)parent[v] = -1;// 最小生成树的边数小于V-1时继续while (i < V - 1 && e > 0) {struct Edge next_edge = edges[--e];// 检查是否会产生环int x = find(parent, next_edge.src);int y = find(parent, next_edge.dest);if (x != y) {result[i++] = next_edge;Union(parent, x, y);}}printf("Edge Weight\n");for (int i = 0; i < V - 1; i++)printf("%d - %d %d \n", result[i].src, result[i].dest, result[i].weight);
}// 测试主函数
int main() {int graph[V][V] = {{0, 2, 0, 6, 0},{2, 0, 3, 8, 5},{0, 3, 0, 0, 7},{6, 8, 0, 0, 9},{0, 5, 7, 9, 0}};printf("Prim's Minimum Spanning Tree:\n");prim_mst(graph);printf("\nKruskal's Minimum Spanning Tree:\n");kruskal_mst(graph);return 0;
}
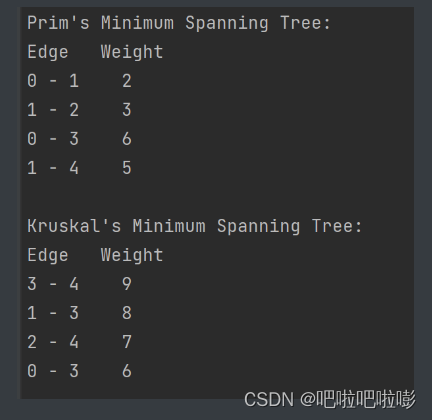
B.邻接表
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <limits.h>#define MaxVertexNum 100
#define INF 9999typedef struct ArcNode {int adjvex;int weight;struct ArcNode *next;
} ArcNode;typedef struct VNode {int data;ArcNode *first;
} VNode, AdjList[MaxVertexNum];typedef struct {AdjList vertices;int vexnum, arcnum;
} ALGraph;void InitALGraph(ALGraph *G, int vexnum, int arcnum) {G->vexnum = vexnum;G->arcnum = arcnum;for (int i = 0; i < vexnum; i++) {G->vertices[i].data = i;G->vertices[i].first = NULL;}
}void AddEdgeUndirectedALGraph(ALGraph *G, int v1, int v2, int weight) {ArcNode *arcNode1 = (ArcNode *)malloc(sizeof(ArcNode));arcNode1->adjvex = v2;arcNode1->weight = weight;arcNode1->next = G->vertices[v1].first;G->vertices[v1].first = arcNode1;ArcNode *arcNode2 = (ArcNode *)malloc(sizeof(ArcNode));arcNode2->adjvex = v1;arcNode2->weight = weight;arcNode2->next = G->vertices[v2].first;G->vertices[v2].first = arcNode2;
}void PrintALGraph(ALGraph G) {for (int i = 0; i < G.vexnum; i++) {printf("%d -> ", G.vertices[i].data);ArcNode *p = G.vertices[i].first;while (p != NULL) {printf("(%d, %d) ", p->adjvex, p->weight);p = p->next;}printf("\n");}
}// Prim算法
void Prim(ALGraph G) {int lowCost[G.vexnum], parent[G.vexnum];bool inMST[G.vexnum];for (int i = 0; i < G.vexnum; i++) {lowCost[i] = INF;parent[i] = -1;inMST[i] = false;}lowCost[0] = 0;for (int i = 0; i < G.vexnum - 1; i++) {int minIndex, minCost = INF;for (int j = 0; j < G.vexnum; j++) {if (!inMST[j] && lowCost[j] < minCost) {minCost = lowCost[j];minIndex = j;}}inMST[minIndex] = true;ArcNode *p = G.vertices[minIndex].first;while (p != NULL) {if (!inMST[p->adjvex] && p->weight < lowCost[p->adjvex]) {lowCost[p->adjvex] = p->weight;parent[p->adjvex] = minIndex;}p = p->next;}}printf("Edge Weight\n");for (int i = 1; i < G.vexnum; i++) {printf("%d - %d %d\n", parent[i], i, lowCost[i]);}
}// Kruskal算法
typedef struct {int src, dest, weight;
} Edge;int find(int parent[], int i) {if (parent[i] == -1)return i;return find(parent, parent[i]);
}void Union(int parent[], int x, int y) {int xset = find(parent, x);int yset = find(parent, y);parent[xset] = yset;
}int compare(const void *a, const void *b) {return ((Edge *)a)->weight - ((Edge *)b)->weight;
}void Kruskal(ALGraph G) {Edge result[G.arcnum];Edge edges[G.arcnum];int parent[G.vexnum];int e = 0;for (int i = 0; i < G.vexnum; i++) {ArcNode *p = G.vertices[i].first;while (p != NULL) {if (i < p->adjvex) {edges[e].src = i;edges[e].dest = p->adjvex;edges[e].weight = p->weight;e++;}p = p->next;}}qsort(edges, G.arcnum, sizeof(Edge), compare);for (int i = 0; i < G.vexnum; i++)parent[i] = -1;int i = 0, j = 0;while (i < G.vexnum - 1 && j < G.arcnum) {Edge next_edge = edges[j++];int x = find(parent, next_edge.src);int y = find(parent, next_edge.dest);if (x != y) {result[i++] = next_edge;Union(parent, x, y);}}printf("Edge Weight\n");for (int i = 0; i < G.vexnum - 1; i++) {printf("%d - %d %d\n", result[i].src, result[i].dest, result[i].weight);}
}int main() {ALGraph G;InitALGraph(&G, 5, 7);AddEdgeUndirectedALGraph(&G, 0, 1, 2);AddEdgeUndirectedALGraph(&G, 0, 3, 6);AddEdgeUndirectedALGraph(&G, 1, 2, 3);AddEdgeUndirectedALGraph(&G, 1, 3, 8);AddEdgeUndirectedALGraph(&G, 1, 4, 5);AddEdgeUndirectedALGraph(&G, 2, 4, 7);AddEdgeUndirectedALGraph(&G, 3, 4, 9);PrintALGraph(G);printf("Prim's Minimum Spanning Tree:\n");Prim(G);printf("\nKruskal's Minimum Spanning Tree:\n");Kruskal(G);return 0;
}
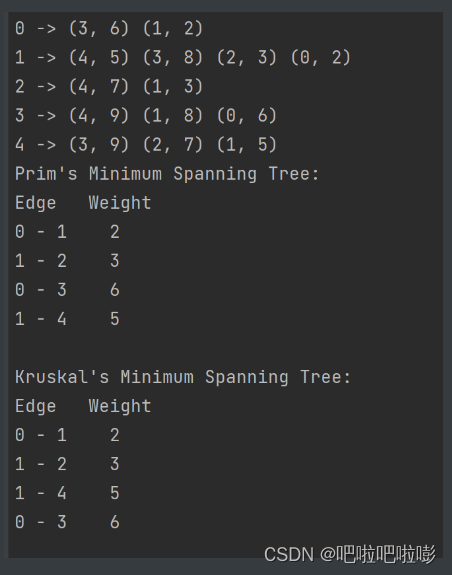
这篇关于【数据结构】最小生成树(Prim算法、Kruskal算法)解析+完整代码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






