本文主要是介绍记一次线上日志堆栈不打印问题排查(附:高并发系统日志打印方案可收藏),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一.线上的日志堆栈不打印了
- 二.一步一步仔细排查
- 三.最后搞定
- 四.聊一聊线上日志到底应该怎么打印
- 4.1 日志打印的诉求
- 4.2 常见的系统日志上报方案
- 4.2.1 ELK 方案
- 4.2.2 自定义log appender 完成应用日志采集.
- 4.3 日志常见框架傻傻分不清
- 4.4 日志在高并发系统中需要注意的 tips
- 4.4.1 配置合理的日志级别
- 4.4.2 记录合理的链路
一.线上的日志堆栈不打印了
线上的报错 error 日志不打印详细的堆栈信息了.本着追根到底的精神.仔细排查了下.目前的日志打印过程.系统和代码虽然是公司的,解决问题都是自己的呀.
正常打印.拥有详细的堆栈信息.
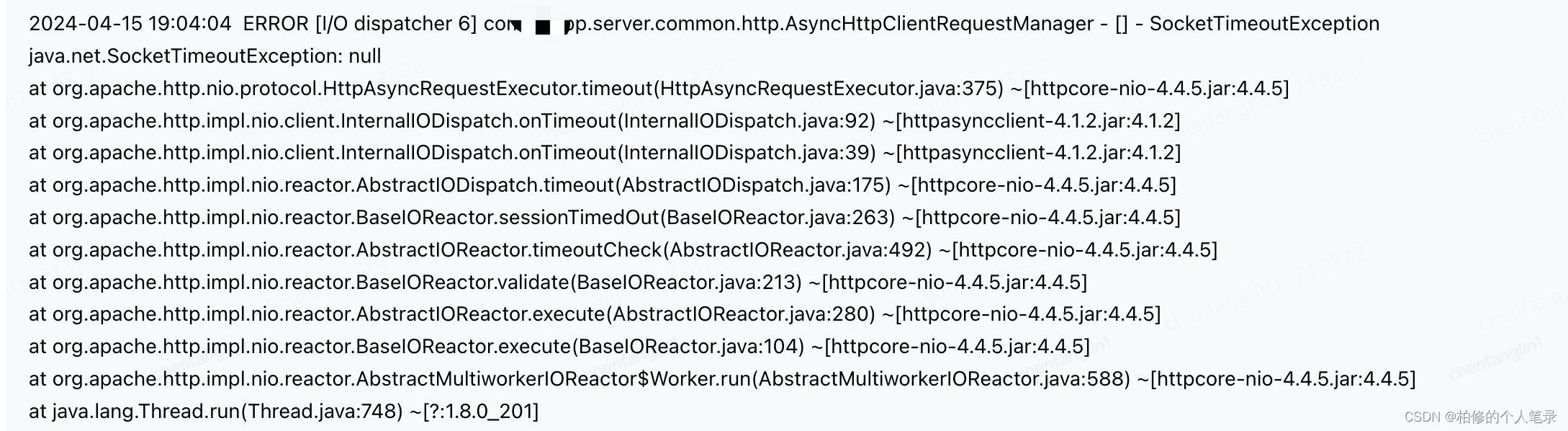
不正常打印.仅打印Exception className

二.一步一步仔细排查
第一反应是哪个神仙写法导致的.一般场景下不打印线上错误日志有这么几种场景.
- logger.error(“关键字{}”,e)
这种场景下 e 只会被 toString() 后打印一些简单的 toString() 方法,如果你的异常是自定义异常.那么相当于需要重写 toString() 方法,最后打印可以按照你的 toString() 方法进行打印.
一般场景下,只会打印简短的日志信息.

- logger.error(“关键字”+e.toString())
这种写法其实和上面第一种写法是一样的逻辑.仅仅只是通过手动拼接的逻辑来处理的.
一步两步跟踪代码.
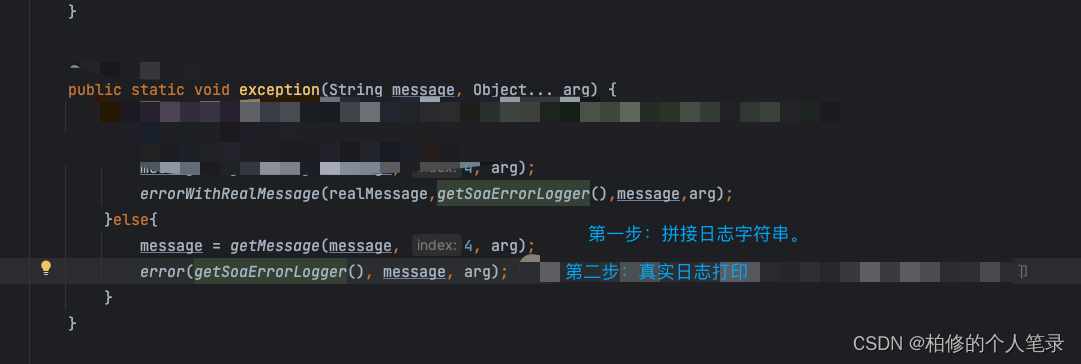
第二步下面的日志打印.
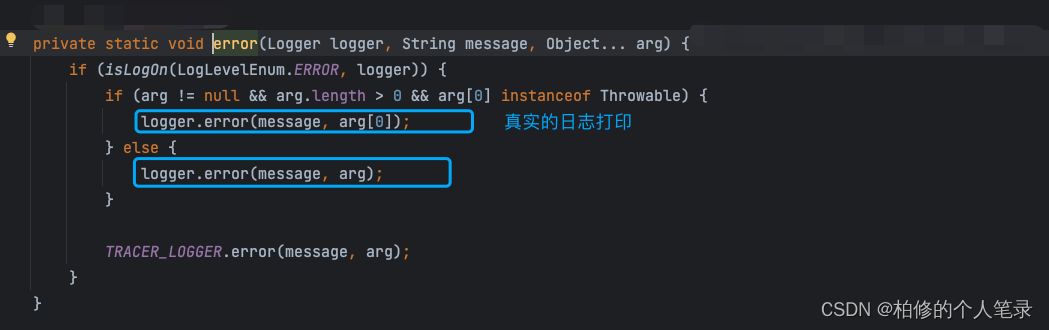
如上第二步真实的日志打印如上.可以发现第二步其实没有什么问题.真实就是直接调用的 logger 的打印方法.
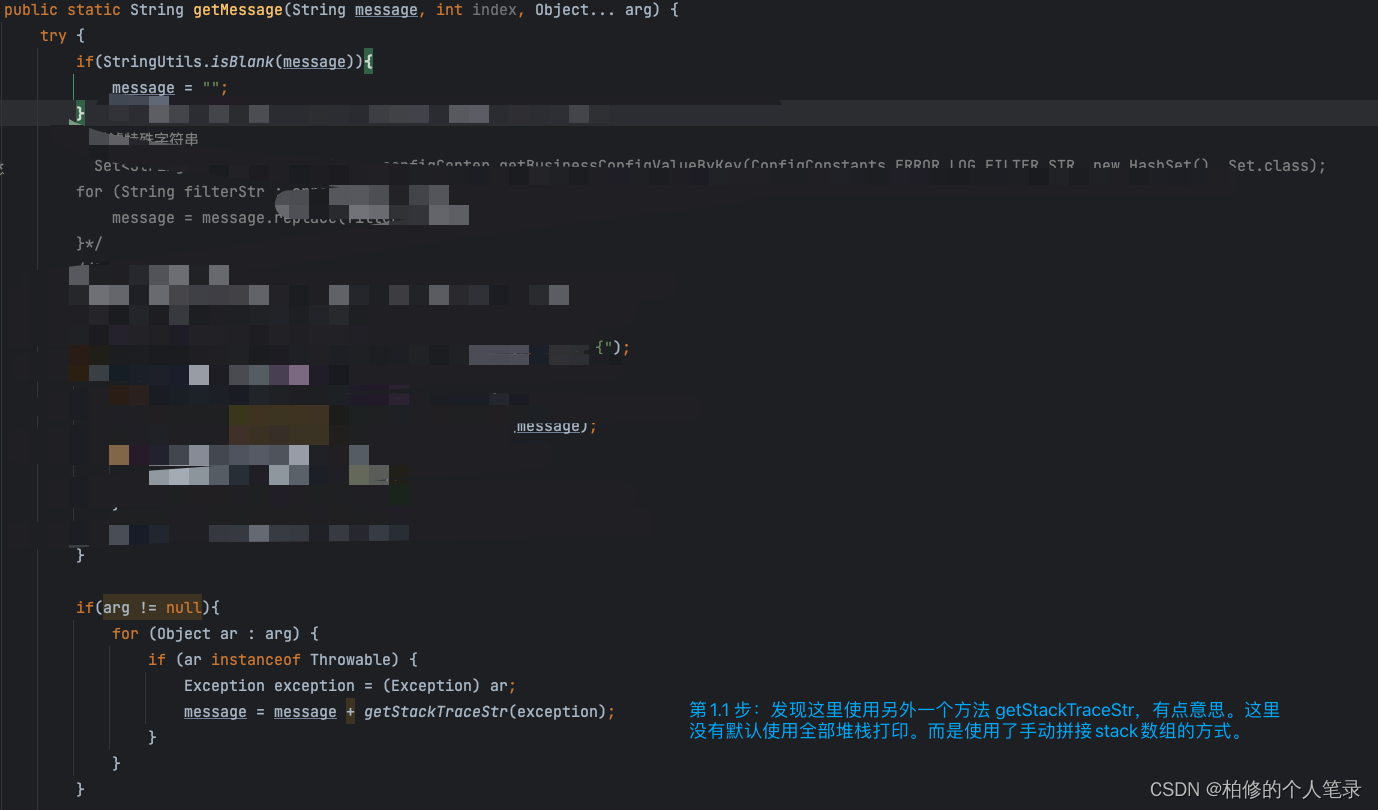
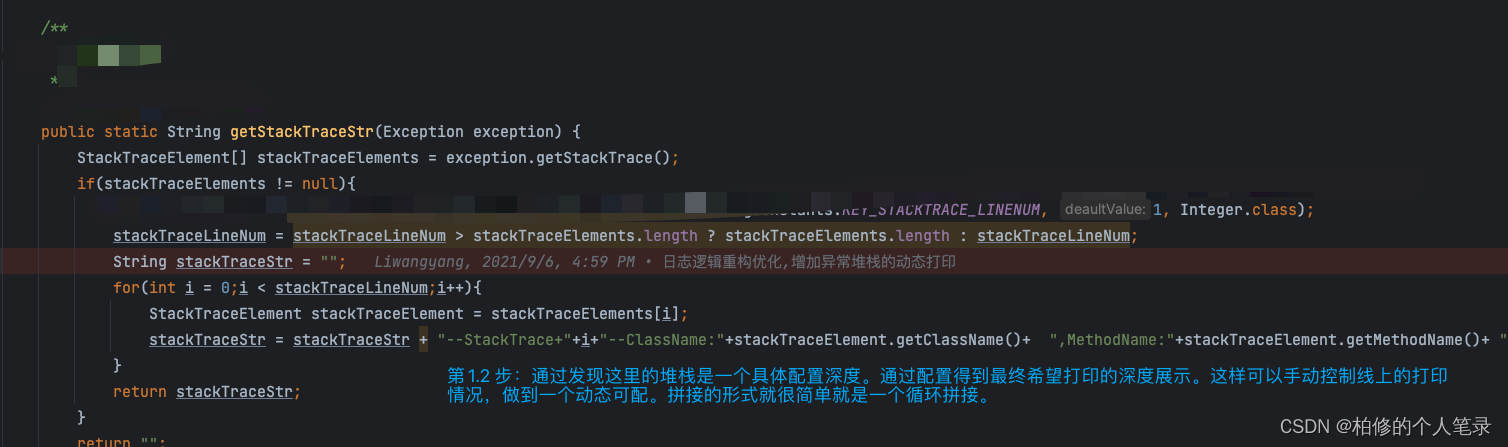
那其实可以发现具体就是在这个方法循环过程中出了问题,没有进入到的循环体中导致无法正确进行拼接,程序员的思维.通过配置发现整体的堆栈深度配置为 1 .先不论 1 是否合适.那么这里有一个判断.
int stackTraceLineNum = stackTraceLineNum > stackTraceElements.length ?
stackTraceElements.length : stackTraceLineNum;
配置的值大于堆栈的深度 length 则使用stack具体的深度.否则则使用配置的stackTraceLineNum.那么这种情况下就是stackTraceElements.length=0.
那么问题来了什么情况会导致这个length为空呢?.点进去.
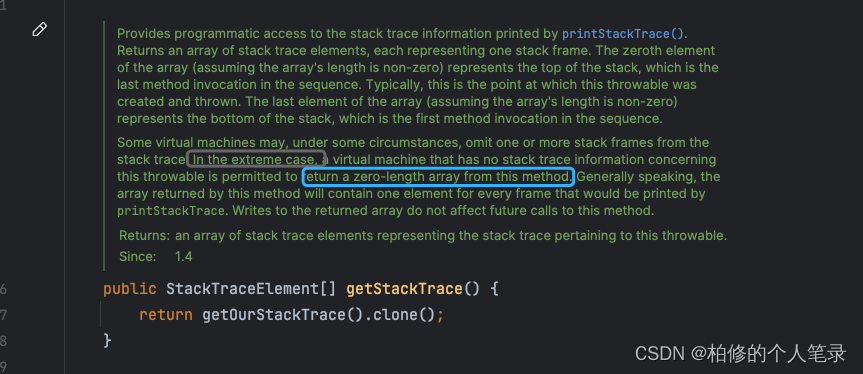
巴拉巴拉说了很长.发现有这么一段话.In the extreme case. a virtual machine that has no stack trace information concerning this throwable is permitted to return a zero-length array from this method.平时喜欢学外语的朋友都知道.这段话:在极端场景下.虚拟机考虑到堆栈信息可能被允许返回一个空数组从这个方法.我草,这是什么鬼.一时间发现这还是我写的那个 Java 吗 ???

线索到这里基本断了.
理了理思路重新梳理了下发现问题的过程,重新将代码部署在预发环境.整体跑了一个遍,并通过 debug 也没哟复现.都是可以正常获取到 stack length.就这样上午一天过去了.并没有什么进展.第二天,脑子稍微清醒了点,确实想的不一样了.再来回想一下线上环境和预发环境的特点,特征.回归原点思考问题.
线上环境:
- 流量特征:流量场景丰富.流量压力并发高.
- 机器环境:线上机器一般配置较高.
预发开发等环境:
-流量特征:场景贫乏.流量压力小.
-机器环境:线上机器可能配置较差[可以通过配置升级来抹平]
那么其实还是要磨平线上环境之间的差异.并尝试了批量的压测,最终他出现了.老小子你还是来了.
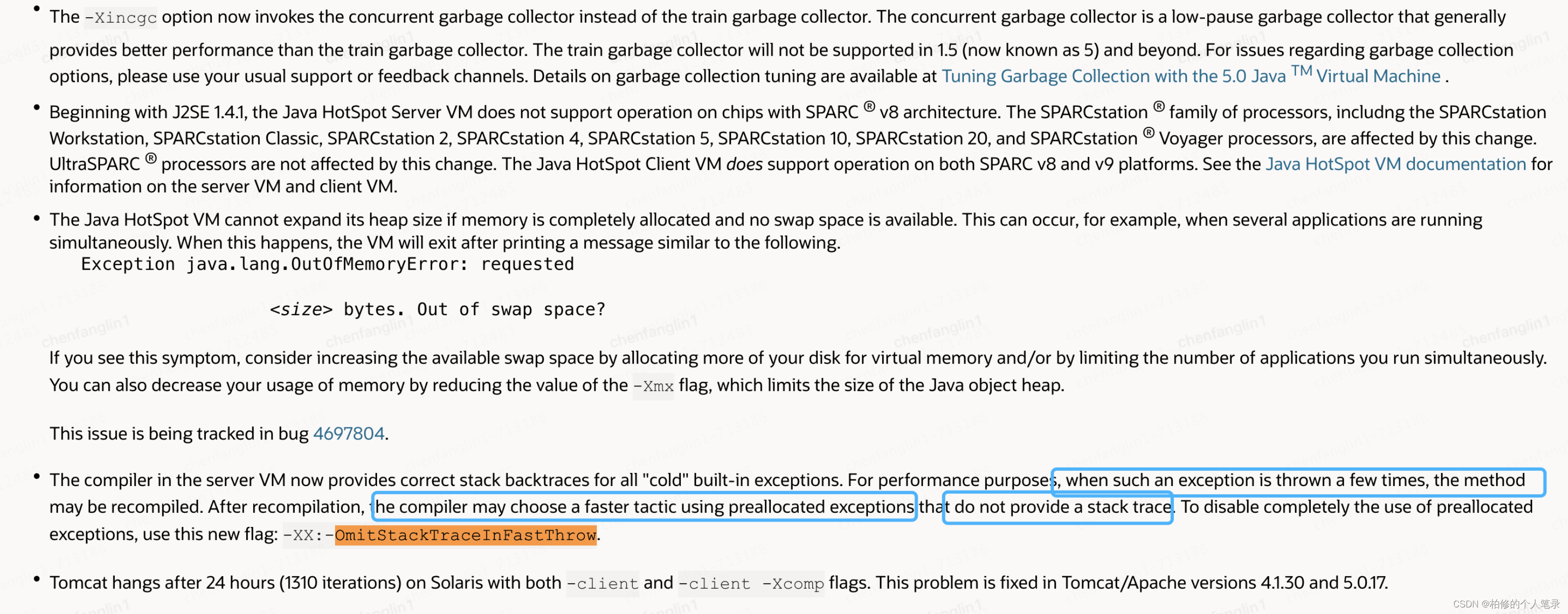
通过发现每每执行到一段时间堆栈就不打印了,这个是不是就是注释里说的极端情况.联系注释提到的 virtual machine. 次数+vm. 这块你想到了什么. 不知道你想到了什么 .在老早之前总结过 jit 的一些特性.一时间马上检索一下(关键字: jit 堆栈不打印优化).确实有了.
oracle官网: https://www.oracle.com/java/technologies/javase/release-notes-introduction.html
三.最后搞定
马上开搞.
-XX:+OmitStackTraceInFastThrow
配置上预发压测走起来,搞定.
幸福之余也再次查阅了一些资料.
发现这是 java 的 fast throw 优化,感叹确实 jit 牛哈.通过次数来检测是否进行详细的堆栈打印.返回来也能理解,虚拟机默认在一些次数打印之后就不再打印详细的堆栈.默认开发者已经关注到相关的堆栈信息了.以此来减少性能损耗.主要应对常见的一些 Exception .
NullPointerException
ArithmeticException
ArrayIndexOutOfBoundsException
ArrayStoreException
ClassCastException
fast throw 本身从 jvm 的 jit 层面来说是一个正向的优化措施,在线上整体的流量还是比较高的场景下,如果一旦将屏蔽优化内容.将徒增很多日志的打印,导致磁盘的 IO 升高以及磁盘利用率升高.所以本次的屏蔽也仅仅是开启了部分分组的配置,即能够保证在指定机器排查问题的场景下完成日志的追踪,也能够包装 fast throw 自带优化能够大部分被利用到.如果你的应用也是这种场景我也是建议使用这种方案.
四.聊一聊线上日志到底应该怎么打印
不止于此通过这次我们正好来聊一聊日志打印的这样一个流程.以及分享目前在搞的一个高并发系统是怎样去打印日志的.
4.1 日志打印的诉求
一般场景下打印日志主要基于以下几种诉求.
目标
- 技术诉求:排查问题;基于关键字主动告警监测系统异常情况.
- 业务运营诉求:基于关键字做流量统计,数据分析获取用户的具体产品功能反馈.以期进一步改进产品方案
关键路径
- 正常业务处理的日志告警关键字打印,需要能将堆栈打印;
- 支持一些巨量的存储以及结构化复杂查询能力
- 具备大促高峰流量的降级可配置
4.2 常见的系统日志上报方案
第一步:应用系统所在机器.一般是 Linux 完成系统日志采集.当发生所关心的日志文件变化时.由监听的进程将日志发送这里有很多种选择.常见的如下:
rsyslog:相对性能比较好,久经考验的老战士.配置较为复杂.
filebeat:性能相比没有rsyslog好.但使用相对简单.使用也比较广泛.
第二步:完成服务端日志接收.这里一般是 Logstash.也就是我们常说的ELK里的L.
第三步:完成日志入库.这里的库可以是 message.es.redis.mysql 集成的三方还是比较多的.
第四步:选择合适的工具来完成日志的展示.比如说:kibana
4.2.1 ELK 方案
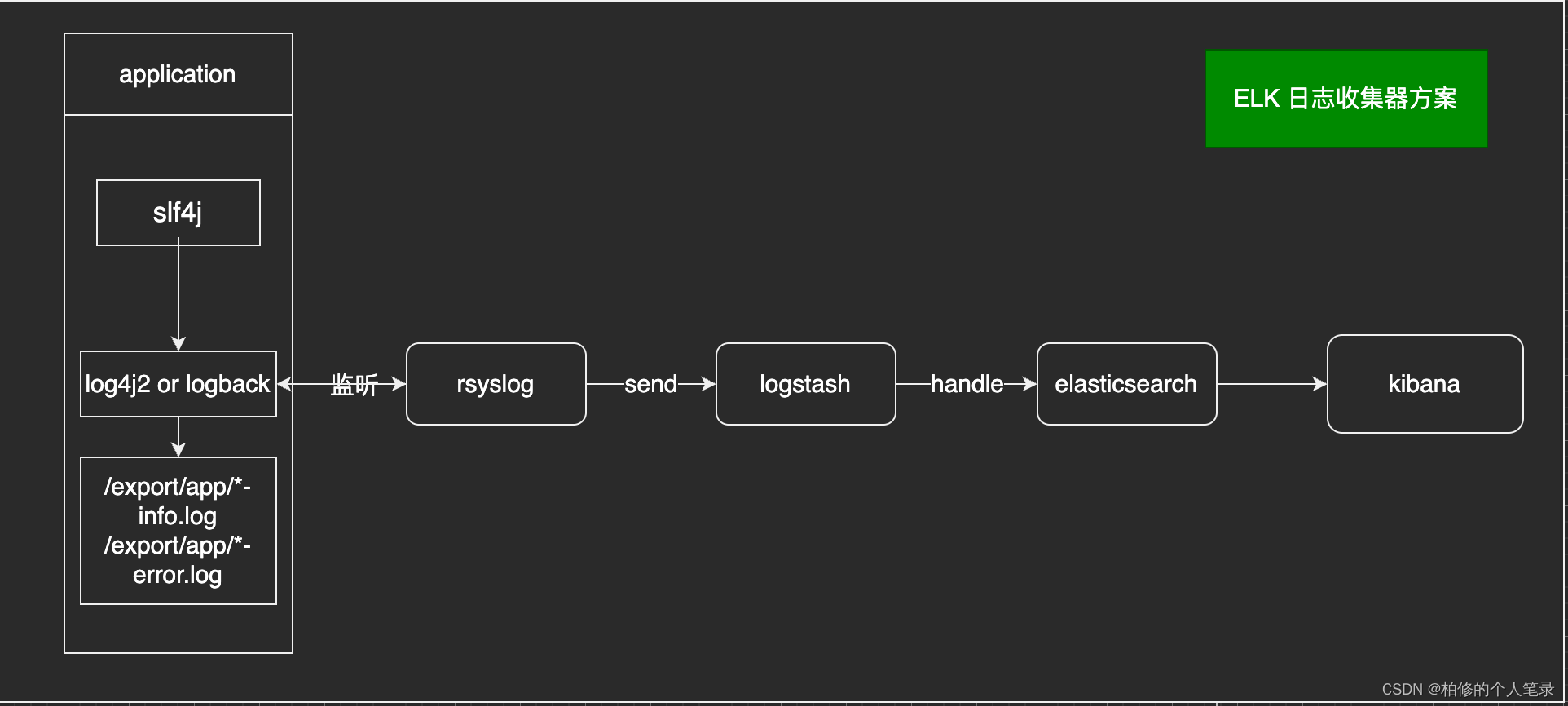
一般比较常见的大厂方案基本如此.
- step1:通过 slf4j 门面完成应用日志文件输出.
- step2:通过 rsyslog 监听文件变更完成日志文件发送.
- step3:通过 logstash 完成日志服务端解析发送.支持的插件也比较多.
具体可参考: https://www.elastic.co/guide/en/logstash/current/output-plugins.html
-step4:完成 es 数据存储.
一键开箱即用的es存储满足巨量的存储且支持水平扩展.并提供比较友好的查询 kibana 能力.
适用场景:业务系统的日志打印抽取.
优点:完全独立在系统应用之外不影响任何系统性能;日志侧可以做到资源的友好伸缩.
缺点:巨量的日志打印后容易出现资源的浪费
4.2.2 自定义log appender 完成应用日志采集.
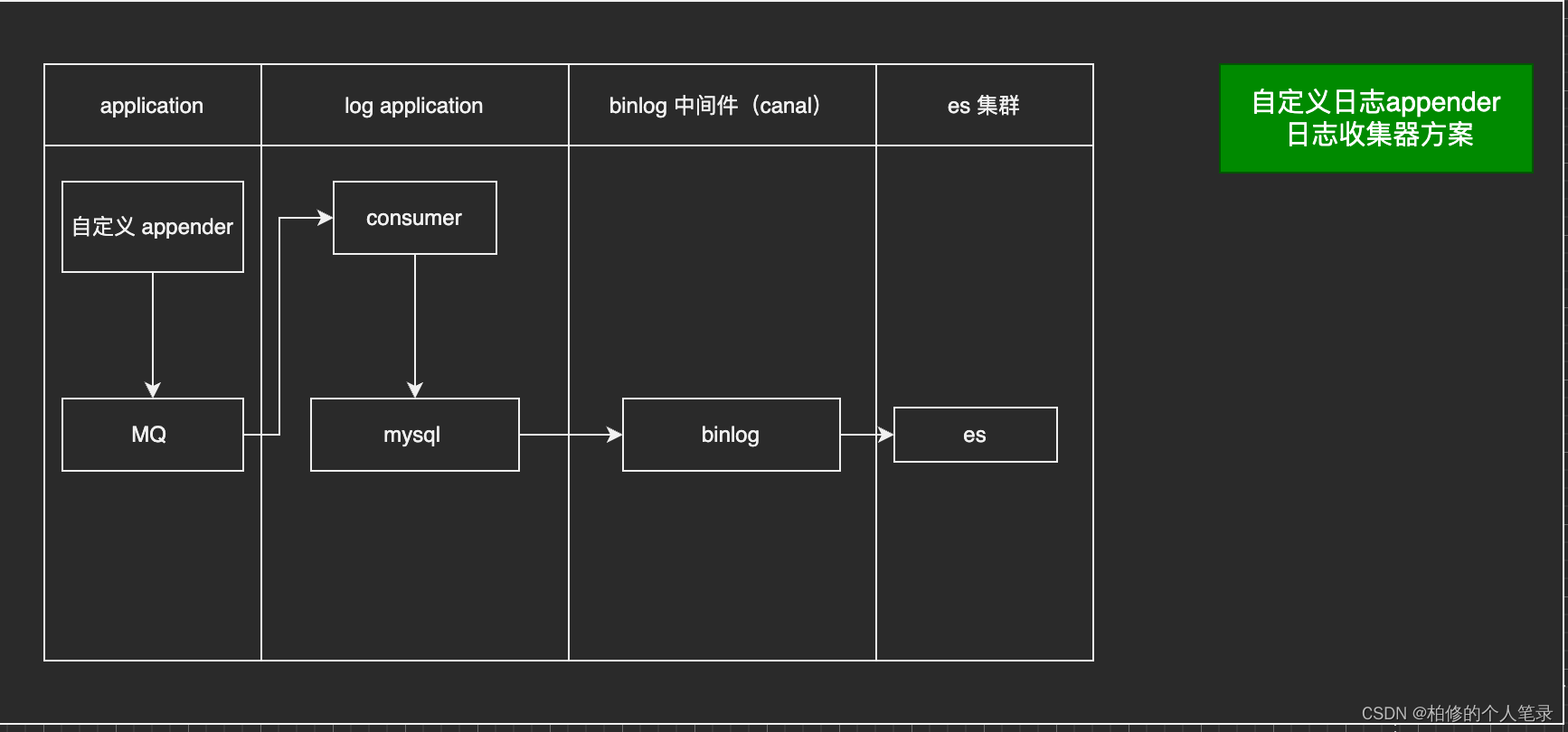
这种自定义appender方案比较适用于一些常见的后台操作.如ERP内部的用户日志记录.如:用户在2024年04月26日17:42:29 完成对租户 101 ,库存 201 的商品
库存调整。
4.3 日志常见框架傻傻分不清
一套日志编写标准.
SLF4J:是一套简易Java日志门面,本身并无日志的实现。(Simple Logging Facade for Java,缩写Slf4j)
以下为一些具体的实现.
- Jul (Java Util Logging):JDK中的日志记录工具,也常称为JDKLog、jdk-logging,自Java1.4以来的官方日志实现。
- Log4j:Apache Log4j是一个基于Java的日志记录工具。它是由Ceki Gülcü首创的,现在则是Apache软件基金会的一个项目。 Log4j是几种Java日志框架之一。
- Log4j2:一个具体的日志实现框架,是Log4j 1的下一个版本,与Log4j 1发生了很大的变化,Log4j 2不兼容Log4j 1。
- Logback:一个具体的日志实现框架,和Slf4j是同一个作者,但其性能更好。
4.4 日志在高并发系统中需要注意的 tips
4.4.1 配置合理的日志级别
常见的日志级别.
分别是 all, error、warning、info、debug、trace。
日常开发中,我们需要选择恰当的日志级别
- all: 所有日志级别打印.
- fatal :无法修复的程序异常
- error :错误日志,指比较严重的错误,对正常业务有影响,需要运维配置监控的;通常我们会在throw异常时进行打印。
- warn :警告日志,一般的错误,对业务影响不大,但是需要开发关注。
- info :信息日志,记录排查问题的关键信息,通常我们会在方法入口和出口打印出入参信息等。
- debug :用于开发DEBUG的,关键逻辑里面的运行时数据。通常我们用来调试关键程序,例如我们可以将SQL的日志级别调为debug,在本地或者测试环境调试时,可以看到具体SQL。
- trace :最详细的信息,一般这些信息只记录到日志文件中。
对于一些流量比较高的场景线上尽量不打印非error级别日志.无差别打印所有级别日志将会对磁盘的造成性能损耗,很可能就会将磁盘打爆,进而影响正常的系统的业务IO。
4.4.2 记录合理的链路
基于上一点我们总会有排查一些线上问题的时候,这无可避免。这时候如果要打印 用以排查问题的日志(非error级别),对于这种场景还是秉着尽可能少打印的原则。
比如说:保证能够做到随机抽量打印或者业务id过滤后打印,这个就视具体的业务类型而定。
如:库存,商品支持商品id来进行过滤;订单,售后支持订单id来进行过滤;
具备日志白名单(用户 id or pin )后查阅用户链路
赠人玫瑰 手有余香 我是柏修 一名持续更新的晚熟程序员
期待您的点赞,关注加收藏,加个关注不迷路,感谢
您的鼓励是我更新的最大动力
↓↓↓↓↓↓
这篇关于记一次线上日志堆栈不打印问题排查(附:高并发系统日志打印方案可收藏)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





