本文主要是介绍五大核心算法(分治、动态规划、回溯、贪心、分支限界),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、分治算法
分治法——见名思义,即分而治之,从而得到我们想要的最终结果。分治法的思想是将一个规模为N的问题分解为k个较
小的子问题,这些子问题遵循的处理方式就是互相独立且与原问题相同。
由两部分组成:
分(divide):递归分解为更小的问题
治(conquer):从子问题来解决原问题
三个步骤:
1、分解(Divide):将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题;
2、解决(Conquer):若子问题规模较小而容易被解决则直接解决,否则递归地解各个子问题;
3、合并(Combine):将各个子问题的解合并为原问题的解。
问题简化如下:
我们有一对硬币,如何找出不同的一个?
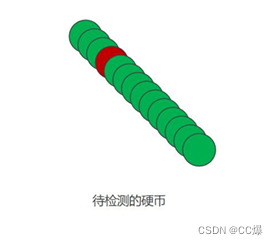
分治算法怎么做?分为两半
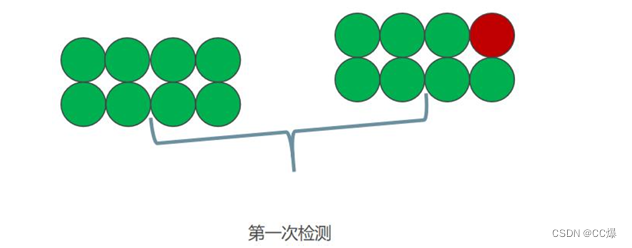
再从含有的一般里面在进行检测:
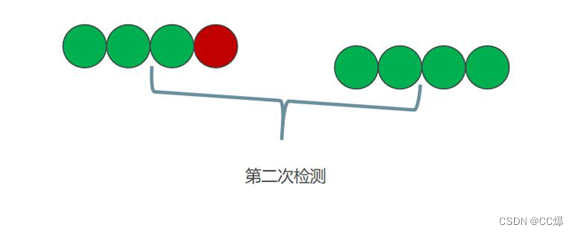
逐步到最后一步:

这样就将需要的检测出来了。
下面我们写出代码:
#include<bits/stdc++.h>using namespace std;/*递归实现二分查找参数:arr- 有序数组地址arrminSub- 查找范围的最小下标minSubmaxSub- 查找范围的最大下标maxSubnum- 带查找数字
返回:找到则返回所在数组下标,找不到则返回-1*/int BinarySearch(int* arr, int minSub, int maxSub, int num) {if (minSub > maxSub) {return -1; // 找不到 num}int mid = (minSub + maxSub) / 2;if (num < arr[mid]) { // 数小于mid,则往左边找return BinarySearch(arr, minSub, mid - 1, num);}else if (num > arr[mid]) { // 数大于mid,则往左边找return BinarySearch(arr, mid+1, maxSub, num);}else { // 找到了return mid; // 数组下标}
}int main() {int arr[] = { 1,5,8,9,10,15,17,23 };int index = BinarySearch(arr, 0, sizeof(arr) / sizeof(arr[0]), 15); // 查找15的下标cout << "index : " << index<<endl;system("pause");return 0;
}
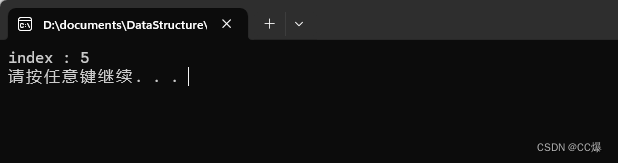
测试结果:
二、动态规划算法(非常重要)
先看问题:下面这个台阶,一次可以上1级台阶,也可以一次上2级台阶,求我们走一个n级台阶总共有多少种走法?
思考?
分治法核心思想:从上往下分析问题,大问题可以分解为子问题,子问题中还有更小的子问题
我们可不可以同分治算法一样,进行分解呢?分治算法
由于一次可以走两级台阶,也可以走一级台阶,所以我们可以分成两个情况(从上往下)
- 最后一次走了两级台阶,问题变成了“走上一个3级台阶,有多少种走法?”
- 最后一步走了一级台阶,问题变成了“走一个4级台阶,有多少种走法?”
我们将求n级台阶的共有多少种走法用f(n)来表示,则
f(n)=f(n-1)+f(n-2);
由上可得比如:
f(5)=f(4)+f(3);
f(4)=f(3)+f(2);
f(3)=f(2)+f(1);
边界情况分析:
走一步台阶时,只有一种走法,所以f(1)=1
走两步台阶时,有两种走法,直接走2个台阶,分两次每次走1个台阶,所以f(2)=2
走两个台阶以上可以分解成上面的情况。 这是不是就是我们上文提到的过的算法;分治算法呢?
代码实现:
#include <bits/stdc++.h>using namespace std;/*递归实现机器人台阶走法统计
参数:n-台阶个数
返回:上台阶总的走法
*/
int WalkCout(int n) {if (n < 0) {return 0;}if (n == 1) {return 1; // 一级台阶,一种走法}else if (n == 2) {return 2; // 二级台阶,两种走法}else {return WalkCout(n - 1) + WalkCout(n - 2);}
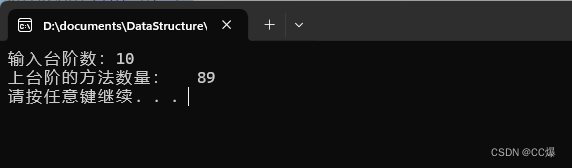
}int main() {int n = 0;cout << "输入台阶数:";cin >> n;cout << "上台阶的方法数量: " << WalkCout(n) << endl;system("pause");return 0;
}
测试结果:
这种算法来求解存在很大问题,就是计算存在很多重复性。
比如: f(5)=f(4)+f(3)
计算分成两个分支:
f(4)=f(3)+f(2)=f(2)+f(1)+f(2);
f(3)=f(2)+f(1)
所以,***f(2)+f(1)***就是重复计算部分
(可以自己试试,放输入为10000,直接会报错,内存溢出)
★★★★★如何避免重复部分?可以从下而上进行分析问题
f(1)=1
f(2)=2
f(3)=f(1)+f(2)=3
f(4)=f(3)+f(2)=3+2=5
f(5)=f(4)+f(3)=5+3=8
。。。依次类推。。。
#include <bits/stdc++.h>using namespace std;/*递归实现机器人台阶走法统计
参数:n-台阶个数
返回:上台阶总的走法
*/
int WalkCout(int n) {if (n < 0) {return 0;}if (n == 1) {return 1; // 一级台阶,一种走法}else if (n == 2) {return 2; // 二级台阶,两种走法}else {return WalkCout(n - 1) + WalkCout(n - 2);}
}long long WalkCout2(int n) {// 最初三种情况if (n == 0) return 0;if (n == 1) return 1;if (n == 2) return 2;// 数组用来保存台阶数long long*values = new long long [n + 1];values[0] = 0;values[1] = 1;values[2] = 2;for (int i = 3; i <= n; i++) {values[i] = values[i - 1] + values[i - 2];}long long res = values[n]; // n级台阶方法delete values; // 动态内存释放掉return res;
}
int main() {int n = 0;cout << "输入台阶数:";cin >> n;cout << "上台阶的方法数量: " << WalkCout2(n) << endl;system("pause");return 0;
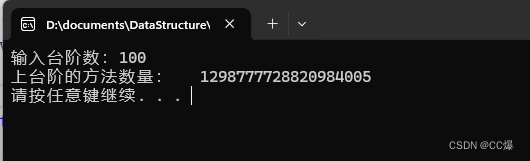
}
测试结果:
这种方法就是动态规划。
动态规划: 也是一种分治思想。
但与分治算法不同的是,分治算法是把原问题分解为若干子问题,自顶向下,求解各子问题,合并子问题的解从而得到原问题的解。
动态规划也是自顶向下把原问题分解为若干子问题,不同的是,然后自底向上,先求解最小的子问题,把结果存储在表格中,在求解大的子问题时,直接从表格中查询小的子问题的解,避免重复计算,从而提高算法效率。
什么时候要用动态规划?
如果要求一个问题的最优解(通常是最大值或者最小值),而且该问题能够分解成若干个子问题,
并且小问题之间也存在重叠的子问题,则考虑采用动态规划。
怎么使用动态规划?
五步曲解决:
1.判题题意是否为找出一个问题的最优解
2.从上往下分析问题,大问题可以分解为子问题,子问题中还有更小的子问题
3.从下往上分析问题,找出这些问题之间的关联(状态转移方程)
4.讨论底层的边界问题
5.解决问题(通常使用数组进行迭代求出最优解
三、回溯法(非常重要)
回溯的基本原理
在问题的解空间中,按深度优先遍历策略,从根节点出发搜索解空间树。算法搜索至解空间的任意一个节点时,先判断该节点是否包含问题的解。如果确定不包含,跳过对以该节点为根的子树的搜索,逐层向其祖先节点回溯,否则进入该子树,继续深度优先搜索。
回溯法解问题的所有解时,必须回溯到根节点,且根节点的所有子树都被搜索后才结束。回
溯法解问题的一个解时,只要搜索到问题的一个解就可结束。
回溯的基本步骤
1.定义问题的解空间
2.确定易于搜索的解空间结构
3.以深度优先搜索的策略搜索解空间,并在搜索过程中尽可能避免无效搜索
直接上案列:(大厂面试题)

思路:
首先,在矩阵中任选一个格子作为路径的起点。如果路径上的第i个字符不是待搜索的目标字
符ch,那么这个格子不可能处在路径上的第i个位置。如果路径上的第i个字符正好是ch,那么
往相邻的格子寻找路径上的第i+1个字符。除在矩阵边界上的格子之外,其他格子都有4个相邻
的格子。重复这个过程直到路径上的所有字符都在矩阵中找到相应的位置。
完整代码:
#include <bits/stdc++.h>using namespace std;// 判断从这个点开始能不能找到字符串路径
bool hasPathCore(const char* matrix, int rows, int cols, int row, int col,const char* str, int& pathLength, bool* visited);/*****************************************
功能:查找矩阵中是否含有str指定的字串
参数说明:matrix 输入矩阵rows 矩阵行数cols 矩阵列数str 要搜索的字符串
返回值:是否找到true是,false否
*******************************************/bool hasPath(const char* matrix, int rows, int cols, const char* str) {if (matrix == NULL || rows < 1 || cols < 1 || str == NULL) { // 矩阵不存在,或者 字符串不存在return false;}bool* visited = new bool[rows * cols]; // 数组用来判断,是否走过该点memset(visited, 0, rows * cols); int pathLength = 0; // 路径长度// 遍历矩阵每个点,作为起点进行搜索for (int row = 0; row < rows; row++) {for (int col = 0; col < cols; col++) {if (hasPathCore(matrix, rows, cols, row, col, str, pathLength, visited)) {return true;}}}delete[]visited;return false;
}// 探测下一个字符是否存在
bool hasPathCore(const char* matrix, int rows, int cols, int row, int col, const char* str, int& pathLength, bool* visited) {if (str[pathLength] == '\0') {return true; //代表字符寻找结束}bool hasPath01 = false;if (row >= 0 && row < rows && col>0 && col < cols && matrix[row * cols + col] == str[pathLength] && !visited[row * cols + col]) {++pathLength;visited[row * cols + col] = true; // 设置为该字符已经走过// 左上右下hasPath01 = hasPathCore(matrix, rows, cols, row, col - 1, str, pathLength, visited)|| hasPathCore(matrix, rows, cols, row - 1, col, str, pathLength, visited)|| hasPathCore(matrix, rows, cols, row, col + 1, str, pathLength, visited)|| hasPathCore(matrix, rows, cols, row + 1, col, str, pathLength, visited);if (!hasPath01) {--pathLength;visited[row * cols + col] = false; // 此处就是回退}}return hasPath01;
}/*单元测试代码*/
void Test(const char* testName, const char* matrix, int rows, int cols,const char* str, bool expected)
{if (testName != nullptr)printf("%sbegins: ", testName);if (hasPath(matrix, rows, cols, str) == expected)printf(" Passed.\n");elseprintf(" FAILED.\n");
}//ABTG
//CFCS
//JDEH//BFCE
void Test1()
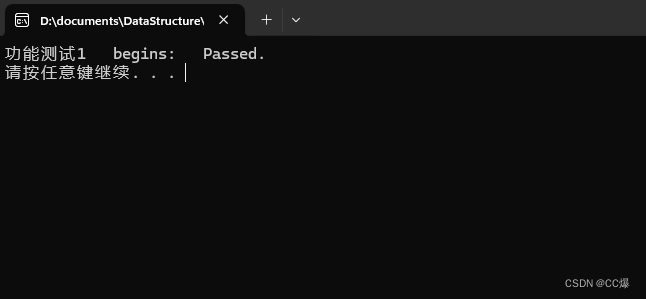
{const char* matrix = "ABTGCFCSJDEH";const char* str = "BFCE";Test("功能测试1 ", (const char*)matrix, 3, 4, str, true);
}int main() {Test1();system("pause");return 0;
}
测试结果:
四、贪心算法(非常重要)
原理:
贪婪算法(贪心算法)是指在对问题进行求解时,在每一步选择中都采取最好或者最优(即最有 利)的选择,从而希望能够导致结果是最好或者最优的算法。
基本思路:
建立数学模型来描述问题
把求解的问题分成若干个子问题
对每一子问题求解,得到子问题的局部最优解
把子问题对应的局部最优解合成原来整个问题的一个近似最优解
直接上面试题:

思路:
每次我尽量用最大的纸币来支付,每次我都做到最贪的状态,想最少纸币支付。
完整代码如下:
#include <bits/stdc++.h>using namespace std;#define N 7
int value[N] = { 1,2,5,10,20,50,100 }; // 零钱面值
int counts[N] = { 10,2,3,1,2,3,5 }; // 零钱张数/**************************
*对输入的零钱数,找到至少要用的纸币的数量
*参数:
* money - 要找/支付的零钱数
*返回:
* 至少要用的纸币的数量,-1表示找不开
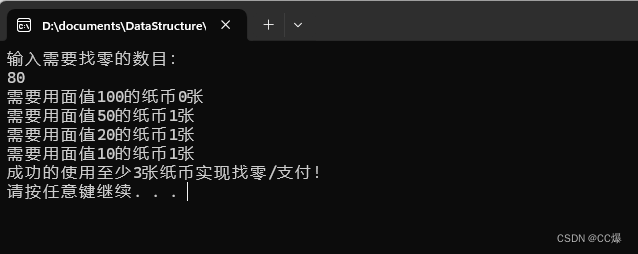
*************************/int solve(int money) {if (money == 0) return 0; // 如果输入的 money 为 0,则不需要使用任何纸币int num = 0;int i = 0;for (i = N - 1; i >= 0; i--) { // 从大的开始支付int j = money / value[i]; // 需要用目前最大的去支付int c = j > counts[i] ? counts[i] : j;printf("需要用面值%d的纸币%d张\n", value[i], c);money -= c * value[i];num += c; if (money == 0) break;}if (money > 0) num = -1;return num;
}int main(void) {int money = 0;int num = 0;printf("输入需要找零的数目: \n");scanf_s("%d", &money); // scanf_s 就是如果输入是字符串 ("%s",monney,10),10代表只接受10个num = solve(money);if (num == -1) {printf("对不起,找不开\n");}else {printf("成功的使用至少%d张纸币实现找零/支付!\n", num);}system("pause");return 0;
}
测试结果:
五、分支定界法
分支定界(branchandbound)算法是一种在问题的解空间上搜索问题的解的方法。但与回溯算
法不同,分支定界算法采用广度优先或最小耗费优先的方法搜索解空间树,并且,在分支定界算
法中,每一个活结点只有一次机会成为扩展结点。
利用分支定界算法对问题的解空间树进行搜索,它的搜索策略是:
1.产生当前扩展结点的所有孩子结点;
2.在产生的孩子结点中,抛弃那些不可能产生可行解(或最优解)的结点;
3.将其余的孩子结点加入活结点表;
4.从活结点表中选择下一个活结点作为新的扩展结点。 如此循环,直到找到问题的可行解(最优解)或活结点表为空。
从活结点表中选择下一个活结点作为新的扩展结点,根据选择方式的不同,分支定界算法通
常可以分为两种形式:
1.FIFO(FirstInFirstOut)分支定界算法:按照先进先出原则选择下一个活结点作为扩展结点,即从活结点表中取出结点的顺序与加入结点的顺序相同。
2.最小耗费或最大收益分支定界算法:在这种情况下,每个结点都有一个耗费或收益。假如要查找一个具有最小耗费的解,那么要选择的下一个扩展结点就是活结点表中具有最小耗费的活结点;假如要查找一个具有最大收益的解,那么要选择的下一个扩展结点就是活结点表中具有最大收益的活结点
这篇关于五大核心算法(分治、动态规划、回溯、贪心、分支限界)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




