本文主要是介绍《DiffusionNER: Boundary Diffusion for Named Entity Recognition》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Submitted 22 May, 2023; originally announced May 2023.
Comments: Accepted to ACL 2023, submission version
https://github.com/tricktreat/DiffusionNER
在这里插入图片描述
问题:
- 命名实体识别任务中存在的噪声跨度(边界不清晰)如何处理?
解决方法:
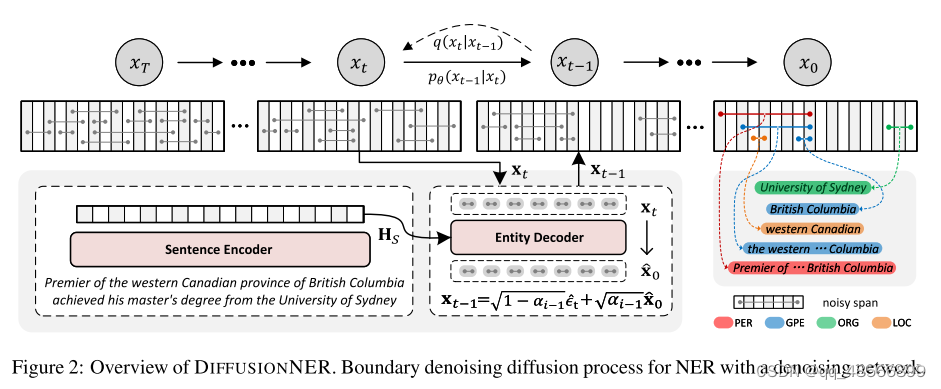
- 提出了 DIFFUSIONNER 方法,将命名实体识别任务建模为一个边界去噪扩散过程,从而生成清晰的命名实体。
- 在训练过程中,DIFFUSIONNER 通过一个固定的前向扩散过程逐渐向金标准实体边界添加噪声,然后学习一个逆扩散过程来恢复实体边界。
- 在推断过程中,DIFFUSIONNER 首先从标准高斯分布中随机抽样一些嘈杂的跨度,然后通过学习的逆扩散过程对它们进行去噪,从而生成清晰的命名实体。
- 提出的边界去噪扩散过程允许逐步细化和动态采样实体,使 DIFFUSIONNER 具备高效灵活的实体生成能力。
这种方法的优点是可以有效处理噪声跨度,并且在实验中表现出与先前最先进模型相当甚至更好的性能。
当涉及到NER(命名实体识别)时,通常的问题之一是嘈杂的跨度,即实体的边界不清晰。这可能是由于文本中的歧义或其他因素导致的。传统的方法可能会将实体识别为包含噪声或不完整的片段,而不是完整的实体。
DIFFUSIONNER 提出了一种新的方法来解决这个问题。它将命名实体识别任务视为一个去噪扩散过程。这个过程可以类比为在文本中“扩散”实体的边界,将不清晰的边界变得更加清晰,并从中生成完整的实体。
在训练过程中,DIFFUSIONNER 逐步向实体的边界添加高斯噪声。这意味着它会在实体的边界周围加入一些随机的噪声。然后,通过一个逆扩散过程,模型会尝试逐步去除这些噪声,以便尽可能地恢复原始的、清晰的实体边界。
举个例子,假设我们有一句话:“John Smith 在 New York 的时候工作。”在这个例子中,“John Smith”和“New York”是两个命名实体。但是,由于文本中的一些歧义或不确定性,实体的边界可能不是非常清晰。DIFFUSIONNER 的训练过程会逐步在实体边界周围添加一些噪声,比如说“Joh…mith”或“Ne…k”。然后,模型会尝试通过学习的逆扩散过程去除这些噪声,以尽可能准确地恢复原始的实体边界,即“John Smith”和“New York”。
在推断阶段,模型可以从一个先验的高斯分布中抽样一些噪声跨度,并利用学到的逆扩散过程来生成完整的实体边界。
创新点
-
DIFFUSIONNER 是首个将扩散模型应用于命名实体识别 (NER) 的方法:
- 传统上,扩散模型在其他领域(如图像处理)中被广泛应用,但在自然语言理解任务中很少被使用。
- DIFFUSIONNER 是第一个将扩散模型应用于 NER 这种在离散文本序列上的抽取式任务的方法。
-
为自然语言理解任务提供了新的视角:
- 通过将扩散模型引入到 NER 任务中,DIFFUSIONNER 提供了一种全新的思路和视角,拓展了自然语言理解领域中的方法和技术。
-
DIFFUSIONNER 将命名实体识别视为边界去噪扩散过程:
- DIFFUSIONNER 提出了一种全新的方式来解决 NER 中存在的噪声跨度问题。
- 它将 NER 任务建模为一个边界去噪扩散过程,通过逐步的边界优化过程,在嘈杂的跨度上生成实体。
-
DIFFUSIONNER 是一种新颖的生成式 NER 方法:
- DIFFUSIONNER 采用了一种全新的生成方式来生成命名实体,即通过在嘈杂的跨度上进行逐步的边界优化,最终生成清晰的实体。
- 这种方法在 NER 领域中是一种创新的方法,可能带来更好的性能和效果。
总的来说,DIFFUSIONNER 提供了一种全新的思路和方法,将扩散模型引入到 NER 任务中,为自然语言理解领域带来了新的探索方向和可能性。
扩散模型
-
扩散模型的背景:
- 扩散模型是由Sohl-Dickstein等人在2015年提出的一种深度潜在生成模型。
- 最近的研究表明,扩散模型在图像和音频生成领域取得了令人瞩目的成果。
-
扩散模型的组成:
- 扩散模型由前向扩散过程和逆向扩散过程组成。
- 前向扩散过程通过按照固定的方差时间表逐步向数据分布添加噪声,逐渐扰动数据的分布。
- 逆向扩散过程则学习恢复数据的结构。
-
在自然语言理解领域的挑战:
- 尽管扩散模型在连续状态空间(如图像或波形)中取得了成功,但在自然语言处理领域仍存在一些挑战,这是因为文本的离散性质。
-
扩散模型在自然语言处理领域的应用:
- Diffusion-LM通过嵌入和舍入操作将离散文本模型化为连续空间,并提出额外的分类器来对可控文本生成施加约束。
- DiffuSeq和SeqDiffuSeq将基于扩散的文本生成扩展到更广泛的设置中,提出了基于仅编码器和编码器-解码器架构的无分类器序列到序列扩散框架。
-
DIFFUSIONNER的贡献:
- DIFFUSIONNER旨在解决离散文本序列上的抽取式任务,即命名实体识别。
总的来说,这段文字介绍了扩散模型在自然语言理解领域的应用和相关研究,并指出了 DIFFUSIONNER 的创新之处及其在离散文本序列任务中的应用。
这篇关于《DiffusionNER: Boundary Diffusion for Named Entity Recognition》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








