本文主要是介绍SPSS之方差分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SPSS中单因素方差分析功能通过【分析】--【比较平均值】--【单因素ANOVA】实现(注意SPSS单因素方差分析的数据格式为两列:其中一列为所有的实验数据(观测变量),另一列为实验水平的标记(控制变量))。
方差齐性检验。控制变量不同水平下观测变量总体方差无显著差异是方差分析的前提要求之一,因此,在作方差分析前,应先对数据进行方差齐性检验。SPSS单因素方差分析中,方差齐性检验采用了方差同质性检验的方法,其零假设是“各水平下观测变量总体的方差无显著差异”,因此P>α时接受零假设,即方差齐性;反之,方差不齐,说明不能进行方差分析。方差齐性检验通过【分析】--【比较平均值】--【单因素ANOVA】--【选项】--【方差同质性检验】来实现。
多重比较检验。如果控制变量确实对观测变量产生了显著影响,进一步还应确定控制变量的不同水平对观测变量的影响程度如何,其中哪个水平的作用明显区别于其它水平等等,此时就应进行多重比较检验。本次实验主要练习采用LSD方法进行多重比较检验。通过【分析】--【比较平均值】--【单因素ANOVA】--【事后多重比较】--【LSD】来实现。
SPSS中多因素方差分析功能在【分析】--【一般线性模型】--【单变量】中进行单因素方差分析(注意SPSS多因素方差分析的数据格式为多列:其中一列为所有的实验数据(观测变量),其余的列分别为实验水平的标记(控制变量))。
SPSS多因素方差分析中,如果某控制变量的不同水平对观测变量产生显著影响,需进一步对该控制变量各水平间进行多重比较。通过【分析】--【一般线性模型】--【单变量】--【事后多重比较】--【LSD】来实现。
接下来我们将进行实战演练!
单因素方差分析:
利用文件标准木测树数据.sav,选择树高和胸径两变量进行方差分析,分析不同样地间的差异是否显著,如差异显著,进行多从比较。
首先,我们先来看一下标准木测树数据的变量视图(Variable View),变量视图中可以看到数据集中所有字段的Name、Type、Width和Decimals,也可以设置字段的Label、Align、Measure等等。

可以看到,该数据共有7个字段,分别是:[‘编号’,‘样地号’,‘胸径’,‘树高’,‘东西冠幅’,‘南北冠幅’,‘年龄’],所有字段的类型全都属于‘Numeric’数字类型。再来看看数据视图(Data View):该数据集共有95个数据样本。


下面我们对树高和胸径两变量进行方差分析,
单因素方差分析操作流程:[Analyze]→[Compare Means]→[One-Way ANOVA],在Dependent List中添加‘胸径’、‘树高’两个变量,在Factor中添加‘样地号’。
基本统计描述和方差齐性检验在[Options]对话框中勾选[Desciptive]和[Homogenity of variance test],并确定[Continue];
多重比较在[Post Hoc Multiple Comparisons]对话框中勾选[LSD]并确定[Continue]。
最终在[One-Way ANOVA]对话框中选择【OK】按钮,即可输出结果:
基本统计描述:
N:个案数
Mean:平均值
Std.Deviation:标准差
Std.Error:标准误差
95% Confidence Interval for Mean(平均值的95%置信区间)
Lower Bound:下限;Upper Bound:上限
Minimum:最小值
Maximum:最大值

方差齐性检验:
Levene Statistic:Levene统计
df1:自由度1
df2:自由度2
Sig.:显著性

看得出:胸径的p=0.275,p>α,所以接受零假设,认为方差齐性;
树高的p=0.007,p<α,所以拒绝零假设,认为方差不齐。
单因素方差分析表:
Between Groups:组间
Within Groups:组内
Total:总计
Sum of Squares:平方和
df:自由度
Mean Square:均方
F:F统计量
Sig.:显著性

由方差分析表,可以知道胸径的组间离差平方和SSA=81.157,自由度df=2,均方MSA=40.579,F值=2.474;组内离差平方和SSE=1509.064,自由度df=92,均方MSE=16.403;总和离差平方和SST=1590.221,自由度df=94。
树高的组间离差平方和SSA=141.987,自由度df=2,均方MSA=70.993,F值=8.298;组内离差平方和SSE=787.098,自由度df=92,均方MSE=8.555;总和离差平方和SST=929.084,自由度df=94。
多重比较(LSD)法:
Dependent Variable:因变量
Mean Difference:平均值差值
Std.Error:标准误差
Sig.显著性
95% Confidence Interval :95%置信区间

对树的胸径来说,样地1和样地2的胸径有显著差异(p=0.033);
对数的树高来书,样地1和样地2的树高有显著差异(p=0.001);样地1和样地3的树高有显著差异(p=0.000)。
多因素方差分析:
在某化工生产中,为了提高收效率,选了三种不同浓度,四种不同温度做试验。在同一浓度与温度组合下各做两次试验,其收效率数据列于下表。试检验不同浓度不同温度以及它们间的交互作用对收效率有无显著影响。
| 温度 | B1 | B2 | B3 | B4 |
| 浓度 | ||||
| A1 | 14 | 11 | 13 | 10 |
| 10 | 11 | 9 | 12 | |
| A2 | 9 | 10 | 7 | 6 |
| 7 | 8 | 11 | 10 | |
| A3 | 5 | 13 | 12 | 14 |
| 11 | 14 | 13 | 10 |
可以看到,这是一个有重复双因素方差分析问题。因此在SPSS中录入数据时需要进行编号。
具体如下图:
先看一下变量视图:我们录入了‘编号’、‘浓度’、‘温度’、以及‘收效率’四个字段。并将浓度和温度字段的类型设置为字符串类型。

我们再来看看数据视图:有三种不同浓度,四种不同温度,两两一组各进行2次试验,共计24次试验结果。


多因素方差分析功能:[Analyze]→[General Linear Model]→[Univariate];
在[Univariate]对话框中将‘收效率’添加到[Dependent Variable]中,将‘浓度’和‘温度’添加到[Fixed Factor]中,并确定【ok】按钮即输出结果:
主体间效应检验:

浓度引起的条件变差SSA=44.333,自由度df=2,均方MSA=22.167,F值=4.092,显著性概率p=0.044;
温度引起的条件变差SSA=11.500,自由度df=3,均方MSA=3.833,F值=0.708,显著性概率p=0.566;
交互作用引起的条件变差SSA=27.000,自由度df=6,均方MSA=4.500,F值=0.831,显著性概率p=0.568.
结论:
对于浓度,p =0.044,p<α,所以拒绝H0,,即不同的浓度对收效率有显著差异;
对于温度,p =0.566,p>α,所以接受H0,,即不同的温度对收效率没有显著差异;
对于交互作用浓度*温度,p =0.568,p>α,所以接受H0,即不同浓度不同温度对收效率没有显著差异。
多重比较:
在[Univariate]对话框中选择[Post Hoc Multiple Comparisons],在[Post Hoc Multiple Comparisons]对话框中将‘浓度’和‘温度’因子添加到‘Post Hoc Tests for:’中,并勾选上‘LSD’,并确定[Continue],返回到[Univariate]对话框中确定【ok】按钮即输出结果:
对于‘浓度’因子的多重比较:
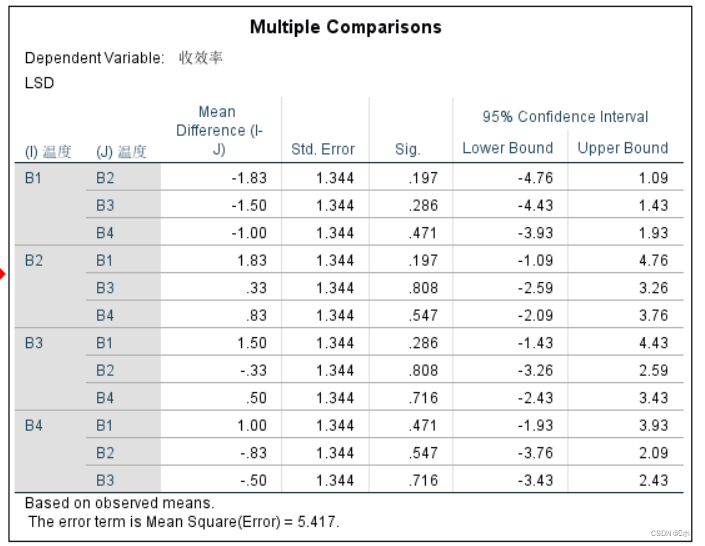
浓度A1和A2对收效率有显著差异(p=0.036);浓度A2和A3对收效率有显著差异(p=0.024)。

对于‘温度’因子的多重比较:温度对收效率没有显著差异。
需要练习原数据的同学,点赞+关注后台私信获取!!!
需要练习原数据的同学,点赞+关注后台私信获取!!!
需要练习原数据的同学,点赞+关注后台私信获取!!!
这篇关于SPSS之方差分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!