本文主要是介绍打破数据分析壁垒:SPSS复习必备(六),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、数据的报表呈现
1.报表概述
(1).SPSS中的报表功能
1)Base 模块
2)Custom Tables 模块
3) Original Tables 模块
(2).报表的基本绘制步骤
步骤一:确定基本结构
步骤二:使用对话框绘制表格的基本结构
步骤三:完善细节
步骤四:添加其余变量和统计量
步骤五:对表格中的文本进行修饰
步骤六:审核
步骤七:保存为模板
下面就按此步骤进行学习报表功能
2.表格入门
(1) 表格的基本框架
表格的元素构成: 行(Row) 列(Column) 层(Layer) 单元格(Cell)
(2) 绘制表格基本框架
1.界面说明
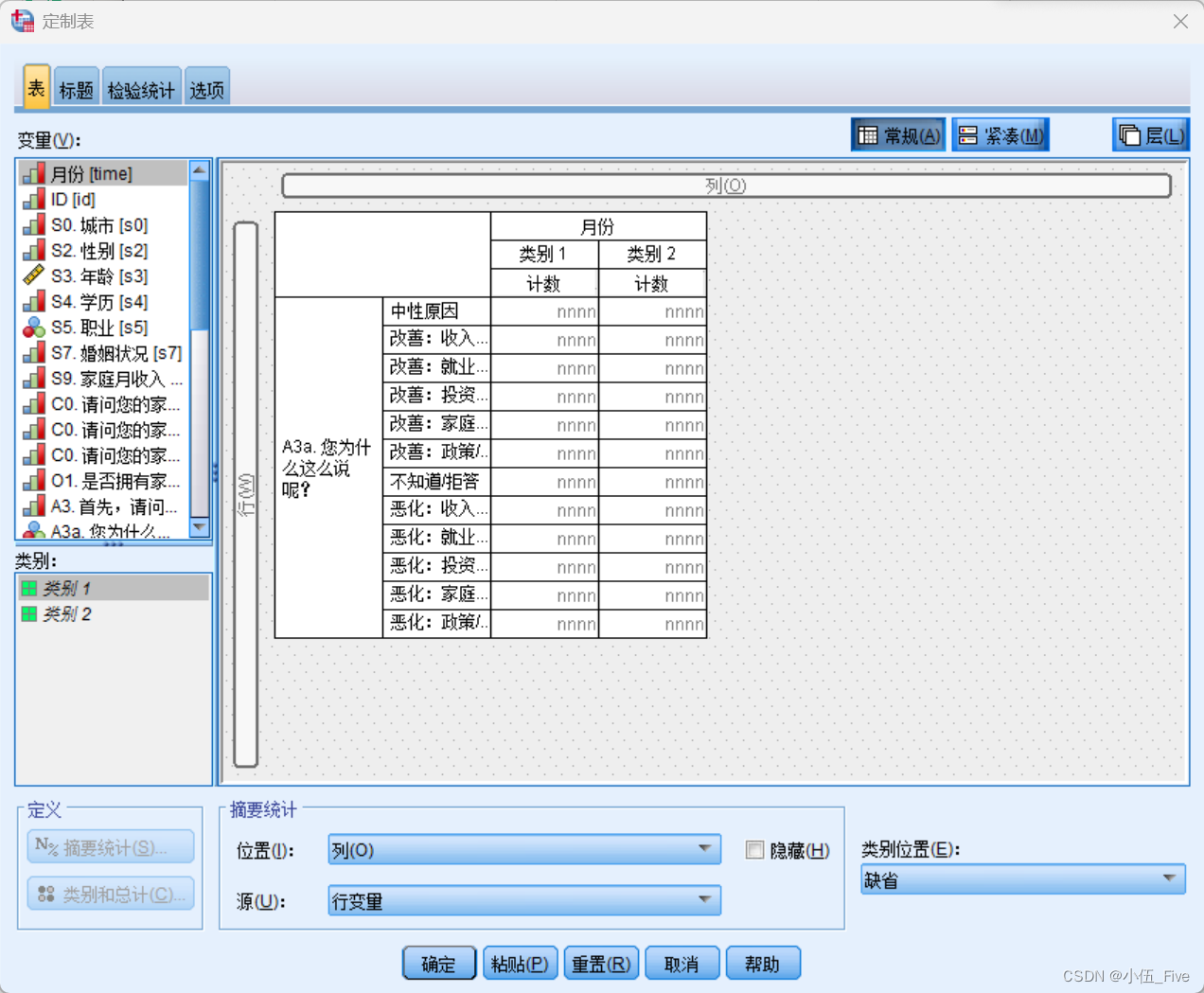
2.设置摘要统计量及格式
1) 对分类变量的摘要统计量进行设定
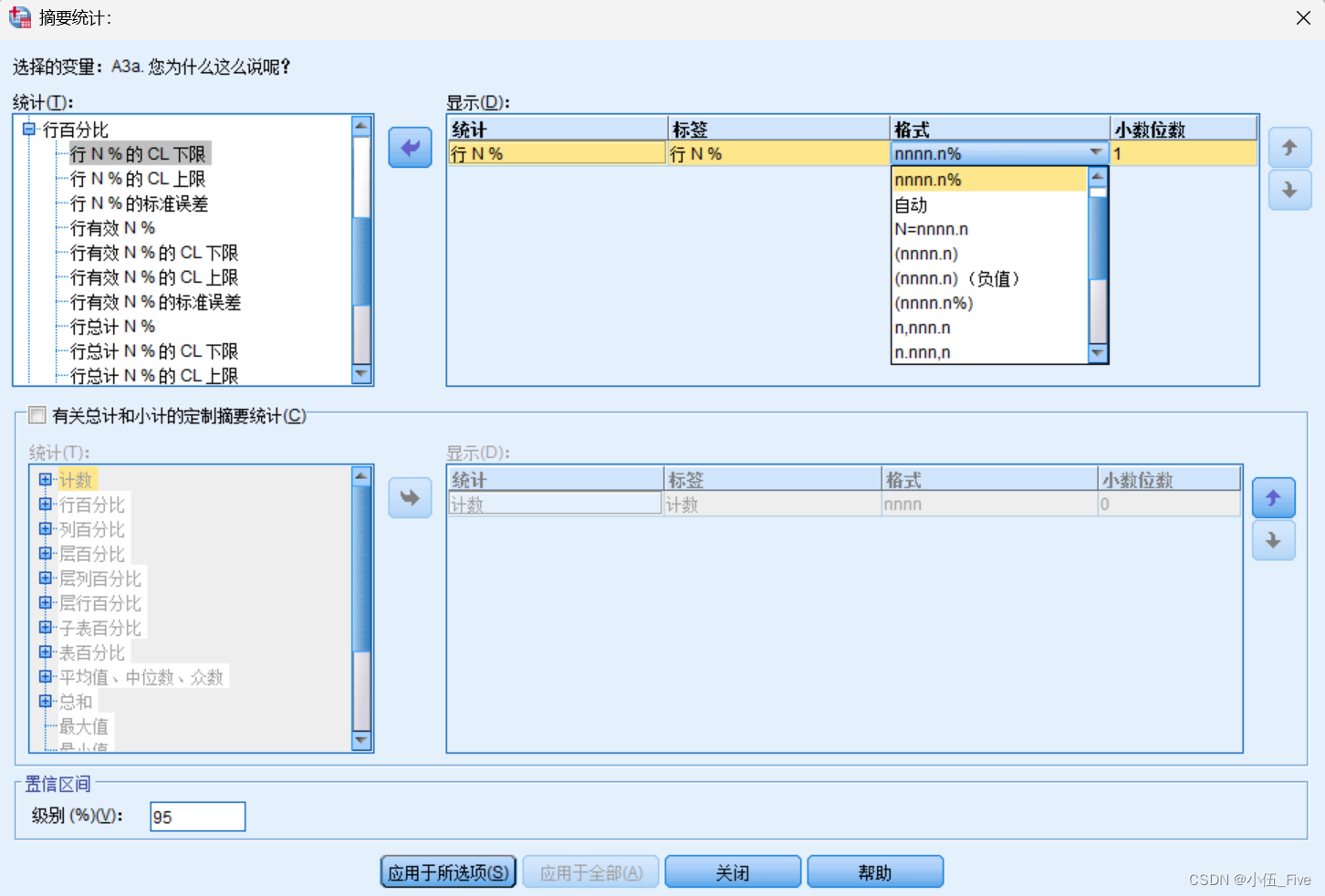
2) 对连续变量的摘要统计量进行设定
3.调整各种显示细节
1)隐藏变量名标签
取消选中其最下方的”显示变量标签"直选框
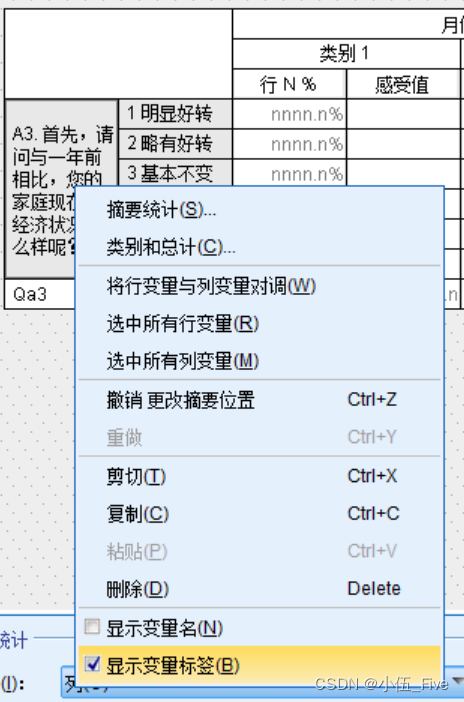
2)使百分比和均数同列显示
3)隐藏统计量标签在"行N%”
最后举个例题:

(1)多选题----设定多重响应集
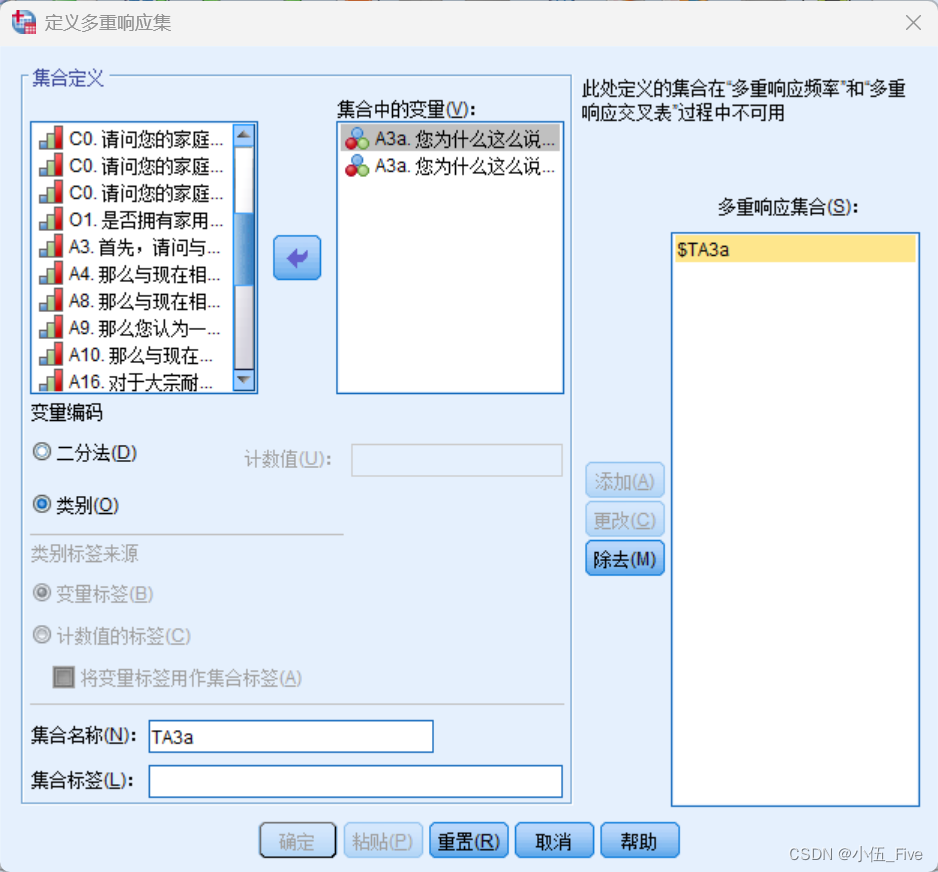
(2)绘制表格基本框架
(1)将变量time拖放至列框内。
(2)将变量集TA3a拖放至行框内。
(3)通过快捷菜单设定time和TA3a的变量名标签为隐藏。
(4)在“摘要统计量”框组中,将“位置”下拉列表框中的选项更改为“行”,选中右侧的“隐藏”复选框以隐藏统计量标签输出。
(3)设定摘要统计量
在画布上选中变量集TA3a后,单击右下方的“摘要统计量”按钮,在打开的子对话框中进行
如下操作。
(1)变量统计量,在右侧的“显示”列表中删除“计数”选项,选入“列响应%”选项,并将其
格式改为“nnnn.n”,1位小数。
(2)选中右侧的“设定关于总计和小计的摘要统计量”复选框,清除下方显示列表中已有的
选择,选人“列N%”选项,同样将其格式改为“nnnn.n”,1位小数。
(3)单击“应用选择”按钮退出子对话框。
(4)设定分类变量小结和汇总项
具体操作:
(1)将“中性原因”、“不知道/拒答”两个选项移入“排除”列表框中。
(2)在右下角的“显示总计和小计”框组中,选中“位于它们所应用于的类别上方”单选按钮。
将小计、汇总在相应类别的左/上侧显示出来。
(3)在“值”框组中选中10(改善:收入相关),然后单击下方的“添加小计”按钮,在打开的
“定义小计”子对话框中将小计名称改为“导致家庭经济状况改善的原因”。
(4)按照和上述方式类似的操作,在110(恶化:收入相关)上方插入名称为“导致家庭经济
状况恶化的原因”的小计。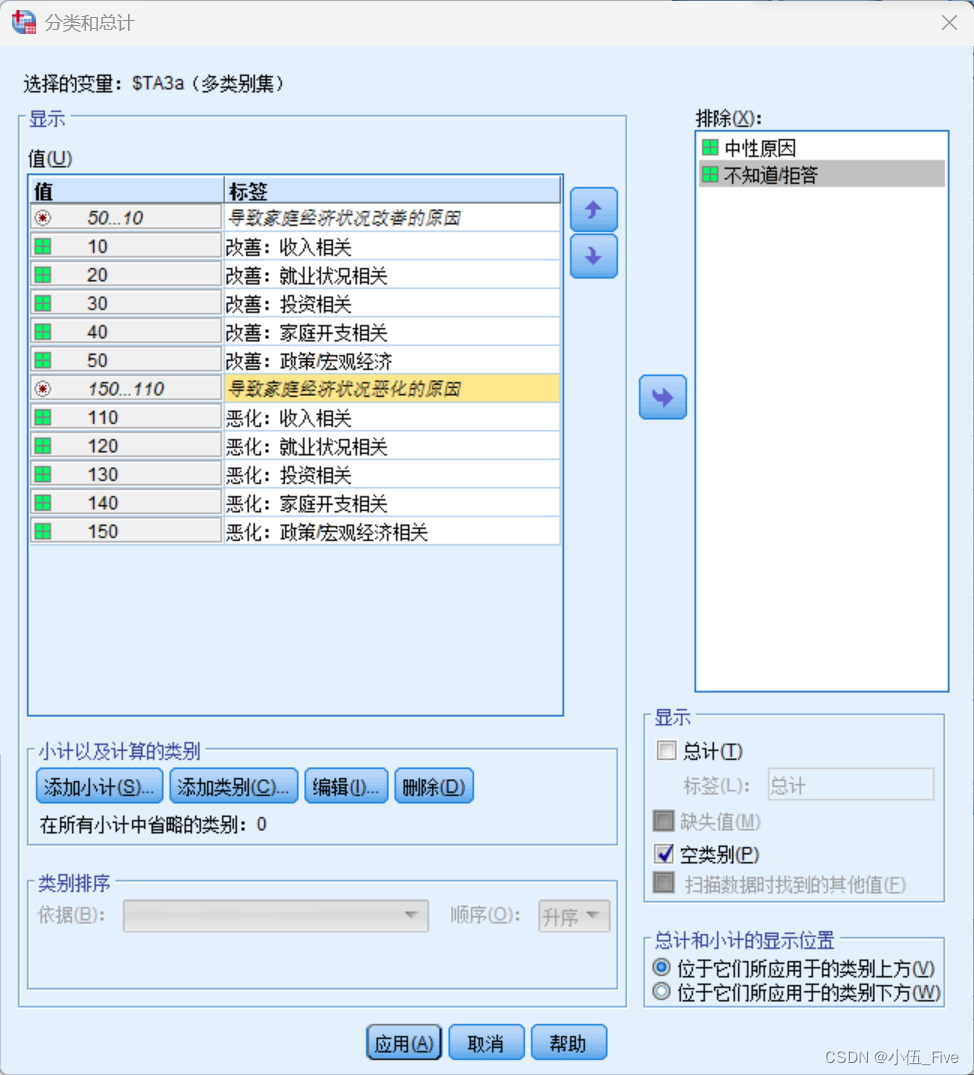
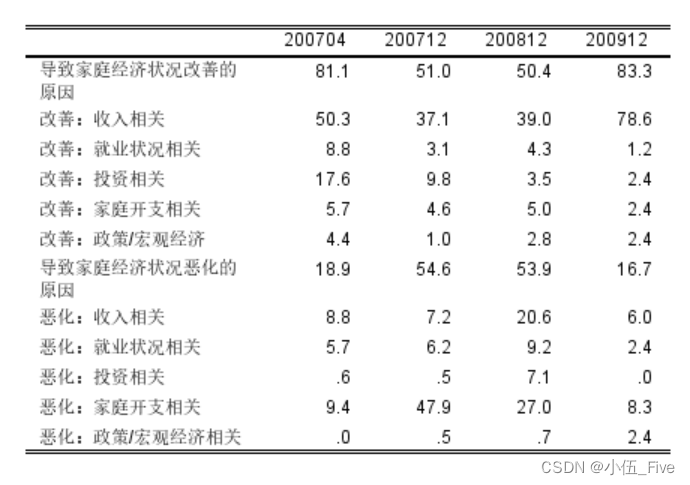
应用后出结果
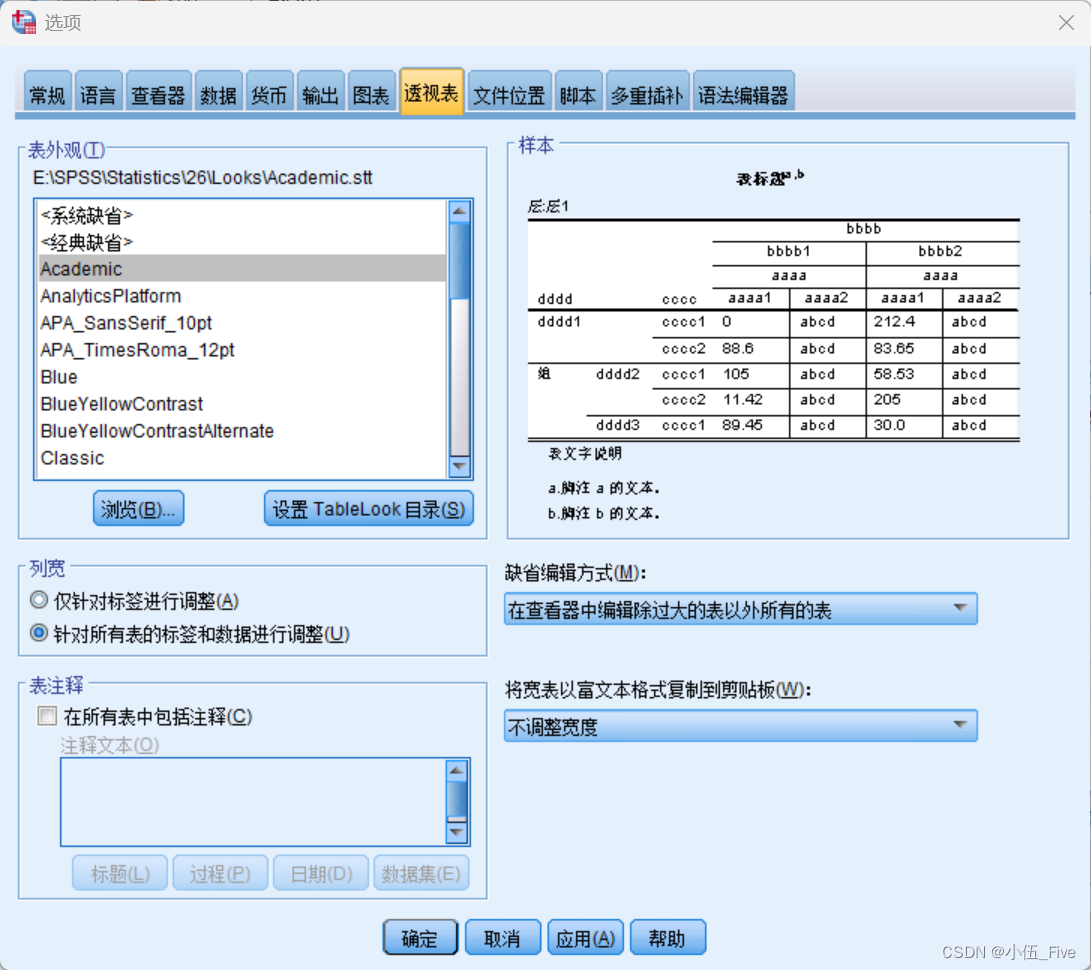
注:设置表格模板
“编辑”---“选项”--“透视表”中选择应用
一般选用Academic三线表格式
总结
本章主要针对数据的报表呈现
主要解决问题:
1)报表概述,即报表功能及报表的基本绘制步骤
2)表格入门即基本框架等相关操作
这篇关于打破数据分析壁垒:SPSS复习必备(六)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!