本文主要是介绍政安晨:【深度学习神经网络基础】(十三)—— 卷积神经网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
概述
LeNet-5
卷积层
最大池层
稠密层
针对MNIST数据集的卷积神经网络
总之
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: 政安晨的机器学习笔记
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
CNN是一种神经网络技术,它已深刻地影响了计算机视觉领域。
Fukushima(1980)引入了卷积神经网络的原始概念,LeCun、Bottou、Bengio和Haffner(1998)大大改进了这个概念。通过这项研究,Yann LeCun引入了著名的LeNet-5神经网络架构。本章介绍具有LeNet-5风格的卷积神经网络。
尽管主要是在计算机视觉领域使用CNN,但该技术在这个领域之外也有一些应用。你需要认识到,如果要在非可视数据上使用CNN,则必须找到一种对数据进行编码的方法,让它可以模拟可视数据的属性。
概述
卷积神经网络(Convolutional Neural Network,CNN)是一种常用于处理具有网格结构数据的神经网络模型。它在人工智能机器学习中被广泛应用于计算机视觉和图像识别任务。
CNN的核心思想是通过卷积层和池化层来提取图像特征,然后通过全连接层和输出层进行分类或回归。具体而言,CNN通过使用多个卷积核来对输入图像进行卷积操作,这样可以从原始图像中提取出不同的特征。卷积操作可以捕捉到图像中的空间局部关系,例如边缘、纹理等信息。
在卷积层之后,通常会使用池化层来降低特征图的空间尺寸,同时保留关键的特征。池化操作可以有选择地减少特征图的大小,从而减少计算量,并提取图像的局部不变特征。
在全连接层中,特征图通过展平操作,然后与权重矩阵相乘,最后通过激活函数进行非线性变换。最后,输出层根据具体任务选择相应的激活函数来进行分类或回归。
CNN的训练过程主要通过反向传播算法进行优化,目标是最小化损失函数。通常使用梯度下降方法来更新网络的权重和偏置,以使网络能够学习到更好的特征表达和分类能力。
总之,卷积神经网络是一种在人工智能机器学习中广泛应用于计算机视觉和图像识别任务的算法,它通过卷积层和池化层来提取图像特征,然后通过全连接层和输出层进行分类或回归。它的优势在于能够自动学习图像中的特征,并能够处理具有网格结构的数据。
CNN有点类似于我们以前提到的“自组织映射”中讨论的SOM。向量元素的顺序对训练至关重要。相比之下,大多数不是CNN或SOM的神经网络都将其输入数据看成值的长向量,在这个向量中传入特征的排列顺序是无关紧要的。对于这些类型的神经网络,训练神经网络后就无法更改传入特征的排列顺序。换言之,CNN和SOM不遵循输入向量的标准处理。
SOM将输入排列成网格。这种安排对图像效果很好,因为互相邻近的像素对彼此很重要。显然,图像中像素的顺序很重要。人体就是这类顺序的一个相关例子——对于脸部的设计,我们习惯于眼睛彼此靠近。同样地,类似SOM的神经网络坚持这样的像素顺序。因此,它们在计算机视觉领域中有许多应用。
尽管SOM和CNN相似,都采用了将输入映射到2D网格,甚至更高维度的对象(如3D盒子)的方式,但CNN将图像识别提升到了更高的水平。CNN的这一进步缘于对生物眼睛的多年研究。换言之,CNN利用重叠的输入视野(field)来模拟生物眼睛的特征。在这项突破之前,人工智能一直无法复制生物视觉的功能。
过去,缩放、旋转和噪声为AI计算机视觉研究带来了挑战。
在下面的例子中,你可以看到生物眼睛的复杂性。一个朋友举起一张纸,上面写着一个很大的数字。当你的朋友离你越来越近时,这个数字仍然可以被识别。当你的朋友旋转纸张时,你仍然可以识别该数字。最后,你的朋友通过在纸上画上线条,产生噪声,你仍然可以识别该数字。如你所见,这些例子演示了生物眼睛的高级功能,让你可以更好地了解CNN的研究突破。也就是说,在计算机视觉领域,该神经网络能处理缩放、旋转和噪声。
LeNet-5
我们可以将LeNet-5架构用于图形、图像的分类。采用这种架构的神经网络类似于我们在前几章中讨论的前馈神经网络。数据从输入流向输出。但是,LeNet-5神经网络包含几种不同的层类型,如下图所示:
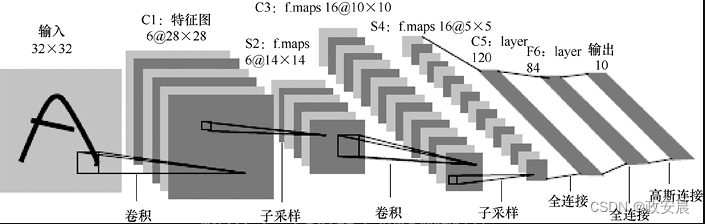
前馈神经网络和LeNet-5神经网络之间存在几个重要区别:
● 前馈神经网络传递向量,LeNet-5神经网络传递3D立方体数据集。
● LeNet-5神经网络包含多种层类型。
● 计算机视觉是LeNet-5的主要应用。
我们也探讨了这些网络之间的许多相似之处。最重要的相似之处在于,我们可以使用相同的基于反向传播的技术来训练LeNet-5。
所有优化算法都可以训练前馈或LeNet-5神经网络的权重。具体来说,你可以使用模拟退火、遗传算法和粒子群优化进行训练。LeNet-5经常使用反向传播训练。
以下三种类型的层构成了最初的LeNet-5神经网络:
● 卷积层;
● 最大池层;
● 稠密层。
其他神经网络框架会添加与计算机视觉有关的其他层类型。但是,我们不会探讨超出LeNet-5以外的内容。添加新的层类型是扩大现有神经网络研究的一种常用方法。以后咱们将会基于“Dropout和正则化”的主题介绍一种附加的层类型,该类型旨在通过添加一个Dropout层来减少过拟合。
现在,我们将讨论集中在与CNN相关的层类型上。我们从卷积层开始。
卷积层
我们要探讨的第一层是卷积层。我们从一些超参数开始,它们是在支持CNN的大多数神经网络框架中必须为卷积层指定的:
● 滤波器(filter)数量;
● 滤波器大小;
● 卷积步长(stride);
● 填充(padding);
● 激活函数/非线性。
卷积层的主要目的是检测特征,如边缘、线条、颜色斑点和其他视觉元素。
滤波器可以检测到这些特征。我们为卷积层提供的滤波器越多,它可以检测到的特征就越多。
滤波器是扫描图像的方形对象。较小的网格可以代表网格的各个像素。
你可以将卷积层视为一个较小的网格,它在图像的每一行上从左向右扫描。还有一个超参数可以指定方形滤波器的宽度和高度。
上图展示了这个配置,其中你可以看到6个卷积滤波器扫描图像网格。
卷积层与它的上一层(即图像网格)之间具有权重。每个卷积层上的每个像素都是一个权重。因此,卷积层与其上一层(即图像视野)之间的权重数如下:
[Filter Size] * [Filter Size] * [Number of Filters]
如果10个滤波器的尺寸都为5(即代表5×5),则共有250个权重。
你需要理解卷积滤波器如何扫描上一层的输出或图像网格。下图展示了一个卷积滤波器。
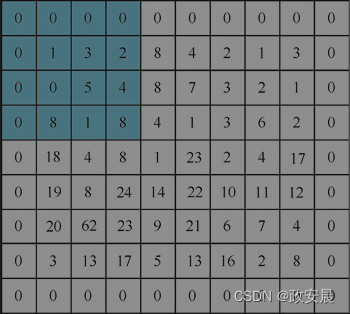
上图展示的卷积滤波器,大小为4,填充大小为1。填充大小决定了滤波器扫描区域中的零边界。
即使图像实际大小为8×7,额外的填充也为滤波器扫描提供了9×8的虚拟图像大小。步长指定卷积滤波器每次扫描将停在什么位置。卷积滤波器向右移动,按步长中指定的单元格数前进。一旦到达最右边,卷积滤波器将移回最左边,然后向下移动一个步长,然后再次向右移动。
上述过程存在与步长大小相关的一些限制。显然,步长不能为0。如果将步长设置为0,则卷积滤波器将永远不会移动。此外,步长和卷积滤波器的大小都不能大于前面的网格。对于宽度为w的图像,步长g、填充[插图]和滤波器宽度p还有其他限制。具体来说,卷积滤波器必须能从最左上的边界开始,移动一定步长,然后到达最右下的边界。下面公式展示了卷积滤波器穿过图像必须走的步数:
![]()
步数必须是整数。换言之,它不能有小数位。调整填充(p)的目的是使上面公式得到整数结果。
当卷积滤波器扫描图像时,我们可以使用相同的权重集。这个过程允许卷积层共享权重,并大大减少所需的处理量。这样,你就可以在一系列移动的位置上识别图像,因为相同的卷积滤波器会扫描整个图像。
卷积层的输入和输出都是3D盒子。对于卷积层的输入,盒子的宽度和高度等于输入图像的宽度和高度,盒子的深度等于图像的颜色深度。对于RGB图像,深度为3,即红色、绿色和蓝色的分量。如果卷积层的输入是另一层,那么它也是3D盒子,但是,该3D盒子的大小将取决于该层的超参数。
和神经网络中的所有其他层一样,卷积层输出的3D盒子的大小由该层的超参数决定。盒子的宽度和高度均等于滤波器大小,深度等于滤波器的数量。
最大池层
最大池层将3D盒子缩小采样(downsample)为更小的新盒子。通常,总是可以在卷积层之后立即放置一个最大池层。上面的那一副图展示了紧接在C1和C3层之后的最大池层。这些最大池层逐渐缩小了穿过它们的3D盒子的大小。这种技术可以避免过拟合。
池化层具有以下超参数:
● 空间范围(f);
● 步长(s)。
与卷积层不同,最大池层不使用填充。此外,最大池层没有权重,因此训练不会影响它们。这些层仅对3D盒子输入进行缩小采样。
最大池层生成的3D盒子的宽度的计算如下公式所示:
![]()
最大池层生成的3D盒子的高度的计算与下面公式类似:
![]()
最大池层生成的3D盒子的深度,等于输入接收的3D盒子的深度。
最大池层超参数最常见的设置是f = 2和是s = 2。空间范围(f)指定将2×2的盒子缩小为单个像素。在这4个像素中,具有最大值的像素将在新网格中代表2×2的单个像素。由于大小为4的正方形被大小为1的正方形替代,因此丢失了75%的像素信息。下图展示了这种转换,6×6的网格变为3×3的网格。
(最大池化(f = 2、s = 2))
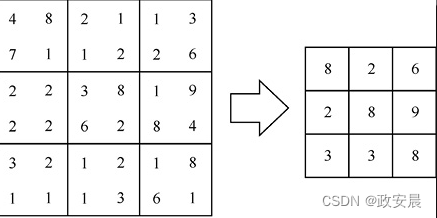
当然,上图将每个像素显示为单个数字。灰度图像具有这种特征。对于RGB图像,我们通常取3个数字的平均值,以确定哪个像素具有最大值。
稠密层
LeNet-5神经网络中的最后一个层是稠密层(dense layer)。
该层类型与我们在前馈神经网络中看到的层类型完全相同。稠密层将上一层输出的3D盒子中的每个元素(神经元)连接到稠密层中的每个神经元,对生成的向量使用激活函数。LeNet-5神经网络通常使用ReLU激活函数。我们也可以用S型激活函数,尽管这种技术不太常见。
稠密层通常包含以下超参数:
● 神经元计数;
● 激活函数。
神经元计数指定组成该层的神经元数。激活函数指示要使用的激活函数的类型。
稠密层可以采用许多不同种类的激活函数,如ReLU、S型或双曲正切激活函数。
LeNet-5神经网络通常会包含几个稠密层作为其最终层。
LeNet-5中的最后一个稠密层实际上执行了分类。每个类别或图像类型应有一个输出神经元进行分类。如果神经网络用于区分狗、猫和鸟,就会有3个输出神经元。你可以将一个最终的Softmax函数应用于最终层,将输出神经元视为概率。Softmax允许每个神经元提供图像代表每个类别的概率。由于现在输出的神经元是概率,因此Softmax确保它们的总和为1(100%)。
针对MNIST数据集的卷积神经网络
在以前“反向传播训练”中,我们使用MNIST手写数字作为使用反向传播的示例。在本文中,我们将举一个改进MNIST手写数字识别的例子,建立一个深度卷积神经网络。
卷积神经网络是一种深度神经网络,其层数比咱们以前提到的前馈神经网络要多。
该神经网络的超参数如下:
● 输入:接受[1,96,96]的盒子。
● 卷积层:滤波器= 32,滤波器大小= [3,3]。
● 最大池层:[2,2]。
● 卷积层:滤波器= 64,滤波器大小= [2,2]。
● 最大池层:[2,2]。
● 卷积层:滤波器= 128,滤波器大小= [2,2]。
● 最大池层:[2,2]。
● 稠密层:500个神经元。
● 输出层:30个神经元。
该神经网络使用非常常见的模式,每个卷积层之后跟一个最大池层。
另外,滤波器的数量从输入层到输出层逐渐递增,从而允许在输入视野附近检测到较少数量的基本特征,如边缘、线条和小形状等。连续的卷积层将这些基本特征汇总为更大、更复杂的特征。
最终,稠密层可以将这些高级特征映射到实际15位特征的每个x坐标和y坐标。
训练卷积神经网络需要花费大量时间,尤其当你不使用GPU处理时。
在这个示例中,我们结合使用了Theano与Lasagne。
本文的示例下载可能还会有针对该示例的其他语言版本,具体取决于这些语言的可用框架。在GPU上训练基于Theano的卷积神经网络来进行数字特征识别,所需的时间少于在CPU上训练的时间,因为GPU对卷积神经网络帮助极大。
具体的性能提升根据硬件和平台而有所不同。卷积神经网络和常规ReLU神经网络之间的精确性比较如下:
ReLU:
Best valid loss was 0.068229 at epoch 17.
Incorrect 170/10000 (1.7000000000000002%)
ReLU+Conv:
Best valid loss was 0.065753 at epoch 3.
Incorrect 150/10000 (1.5%)如果将卷积神经网络的结果与咱们以前提到的标准前馈神经网络进行比较,你会发现卷积神经网络的表现更好。卷积神经网络能够识别数字中的子特征,从而让它的表现超过标准前馈神经网络。当然,这些结果会有所不同,具体取决于所使用的平台。
总之
卷积神经网络是在计算机视觉中应用非常广泛的技术。它们让神经网络能够检测要素的层次结构,如由线条和小形状等简单的特征形成的层次结构,从而教会神经网络识别由更简单的特征组成的复杂模式。深度卷积神经网络会占用相当大的处理能力。一些框架允许使用GPU处理来增强性能。
Yann LeCun推出了最常见的卷积神经网络LeNet-5。这种神经网络由稠密层、卷积层和最大池层组成。稠密层的工作方式与传统前馈神经网络完全相同,最大池层可以对图像进行缩小采样并去除细节,卷积层检测图像视野中任何部分的特征。
为神经网络确定最佳架构的方法有很多。以后咱们还会有更多实践。
这篇关于政安晨:【深度学习神经网络基础】(十三)—— 卷积神经网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









