本文主要是介绍每日OJ题_BFS解决拓扑排序①_力扣207. 课程表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
拓扑排序和图的介绍
①力扣207. 课程表
解析代码
拓扑排序和图的介绍
拓扑排序简单来说就是找到做事情的先后顺序(拓扑排序的结果可能不是唯一的)。
学习拓扑排序前先简单学习图的基本概念:
图是由顶点集合及顶点间的关系组成的一种数据结构:G = (V, E),其中:
- 顶点集合V = {x|x属于某个数据对象集}是有穷非空集合;
- E = {(x,y)|x,y属于V}或者E = {<x, y>|x,y属于V && Path(x, y)}是顶点间关系的有穷集合,也叫做边的集合。
- (x, y)表示x到y的一条双向通路,即(x, y)是无方向的;Path(x, y)表示从x到y的一条单向通路,即Path(x, y)是有方向的。
- 顶点和边:图中结点称为顶点,第i个顶点记作vi。两个顶点vi和vj相关联称作顶点vi和顶点vj之间有一条边,图中的第k条边记作ek,ek = (vi,vj)或<vi,vj>。
- 有向图和无向图:在有向图中,顶点对<x, y>是有序的,顶点对<x,y>称为顶点x到顶点y的一条边(弧),<x, y>和<y, x>是两条不同的边,比如下图G3和G4为有向图。在无向图中,顶点对(x, y)是无序的,顶点对(x,y)称为顶点x和顶点y相关联的一条边,这条边没有特定方向,(x, y)和(y,x)是同一条边,比如下图G1和G2为无向图。注意:无向边(x, y)等于有向边<x, y>和<y, x>。

入度和出度
图中的度:所谓顶点的度(degree),就是指和该顶点相关联的边数。在有向图中,度又分为入度和出度。
- 入度 (in-degree) :以某顶点为弧头,终止于该顶点的边的数目称为该顶点的入度。
- 出度 (out-degree) :以某顶点为弧尾,起始于该顶点的弧的数目称为该顶点的出度。
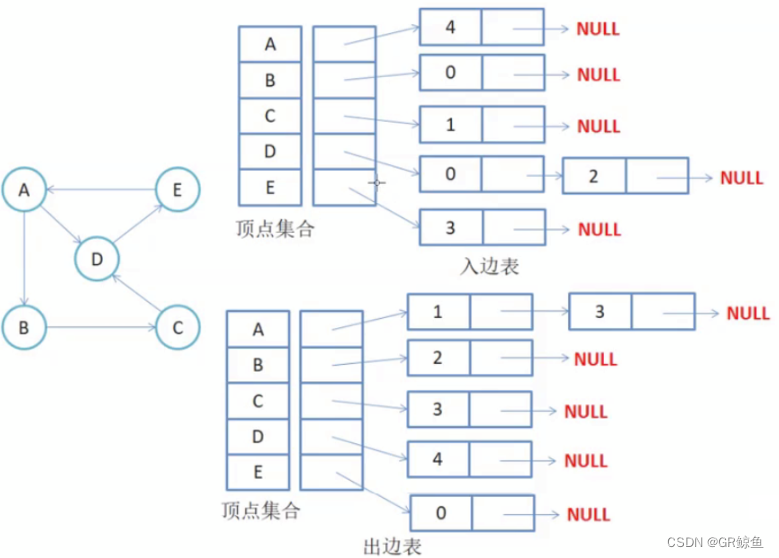
邻接表
邻接表存储方法跟树的孩子链表示法相类似,是一种顺序分配和链式分配相结合的存储结构。如这个表头结点所对应的顶点存在相邻顶点,则把相邻顶点依次存放于表头结点所指向的单向链表中。
- 在有向图中,描述每个点向别的节点连的边(点a->点b这种情况)。
- 在无向图中,描述每个点所有的边(点a-点b这种情况)
有向图邻接表存储
下面是拓扑排序的概念:
一个较大的工程往往被划分成许多子工程,我们把这些子工程称作活动(activity)。在整个工程中,有些子工程(活动)必须在其它有关子工程完成之后才能开始,也就是说,一个子工程的开始是以它的所有前序子工程的结束为先决条件的,但有些子工程没有先决条件,可以安排在任何时间开始。为了形象地反映出整个工程中各个子工程(活动)之间的先后关系,可用一个有向图来表示,图中的顶点代表活动(子工程),图中的有向边代表活动的先后关系,即有向边的起点的活动是终点活动的前序活动,只有当起点活动完成之后,其终点活动才能进行。通常,我们把这种顶点表示活动、边表示活动间先后关系的有向图称做顶点活动网(Activity On Vertex network),简称AOV网。
在AOV网中,若不存在回路,则所有活动可排列成一个线性序列,使得每个活动的所有前驱活动都排在该活动的前面,我们把此序列叫做拓扑序列(Topological order),由AOV网构造拓扑序列的过程叫做拓扑排序(Topological sort)。AOV网的拓扑序列不是唯一的,满足上述定义的任一线性序列都称作它的拓扑序列。
对于有向图的拓扑排序,我们可以使用如下思路输出拓扑序(BFS 方式):
- 起始时,将所有入度为 0 的节点进行入队(入度为 0,说明没有边指向这些节点,将它们放到拓扑排序的首部,不会违反拓扑序定义)。
- 从队列中进行节点出队操作,出队序列就是对应我们输出的拓扑序。对于当前弹出的节点 x,遍历x 的所有出度y,即遍历所有由 x直接指向的节点y,对y做入度减一操作(因为x节点已经从队列中弹出,被添加到拓扑序中,等价于x节点从有向图中被移除,相应的由x发出的边也应当被删除,带来的影响是与 x相连的节点y的入度减一)。
- 对y进行入度减一之后,检查 y的入度是否为0,如果为0则将y入队(当y的入度为0,说明有向图中在y前面的所有的节点均被添加到拓扑序中,此时 可以作为拓扑序的某个片段的首部被添加,而不是违反拓扑序的定义)。
- 循环流程 2、3 直到队列为空。
①力扣207. 课程表
207. 课程表
难度 中等
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
- 例如,先修课程对
[0, 1]表示:想要学习课程0,你需要先完成课程1。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]] 输出:true 解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:
输入:numCourses = 2, prerequisites = [[1,0],[0,1]] 输出:false 解释:总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
提示:
1 <= numCourses <= 20000 <= prerequisites.length <= 5000prerequisites[i].length == 20 <= ai, bi < numCoursesprerequisites[i]中的所有课程对 互不相同
class Solution {
public:bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {}
};解析代码
原问题可以转换成一个拓扑排序问题。用BFS 解决拓扑排序即可。
- 将所有入度为 0 的点加入到队列中。
- 当队列不空的时候,一直循环以下三步:
- 取出队头元素。
- 将于队头元素相连的顶点的入度 - 1。
- 然后判断是否减成 0。如果减成 0,就加入到队列中。
class Solution {
public:bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {unordered_map<int, vector<int>> edges; // 领接表vector<int> in(numCourses, 0); // 存储每一个结点的入度for(auto& e : prerequisites) // 1. 建图{int a = e[0], b = e[1];; // b指向aedges[b].push_back(a);in[a]++;}queue<int> q; // 2. BFS解决拓扑排序for(int i = 0; i < numCourses; ++i){if(in[i] == 0)q.push(i);}while(!q.empty()) // 层序遍历{int tmp = q.front();q.pop();for(auto& e : edges[tmp]) // 得到tmp指向的顶点, 删掉一个入度{in[e]--;if(in[e] == 0)q.push(e);}}for(auto& e : in) // 3. 判断是否有环{if(e != 0)return false;}return true;}
};
这篇关于每日OJ题_BFS解决拓扑排序①_力扣207. 课程表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







