本文主要是介绍Atlas Vector Search:借助语义搜索和 AI 针对任何类型的数据构建智能应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

Atlas Vector Search已正式上线!
Vector Search(向量搜索)现在支持生产工作负载,开发者可以继续构建由语义搜索和生成式人工智能驱动的智能应用,同时通过 Search Node(搜索节点)优化资源消耗并提高性能。
这一刻终于到来:人工智能已触手可及。曾经,数据科学与机器学习是高深莫测的领域,仅为企业内部的专业人士所掌握;然而如今,这些技术的神秘面纱已被揭开,现已向世界各地的创造者敞开了大门。
但若想深入挖掘这些新兴工具的巨大潜能,开发者需要一个可信赖、可灵活组合、精巧高效的数据平台作为基础。同时,这些新能力的效果好坏,取决于它们能够获取的数据或“基本事实”的质量。
因此,我们为 MongoDB Atlas 开发者数据平台增加了一项新的功能,让开发者的数据释放出无限可能,助力 AI 应用的发展——MongoDB 隆重推出全新的 Vector Search 功能,它能够适应各种形式的数据需求,让我们的合作伙伴享受这些惊人新功能带来的好处。
向量搜索的原理和优势
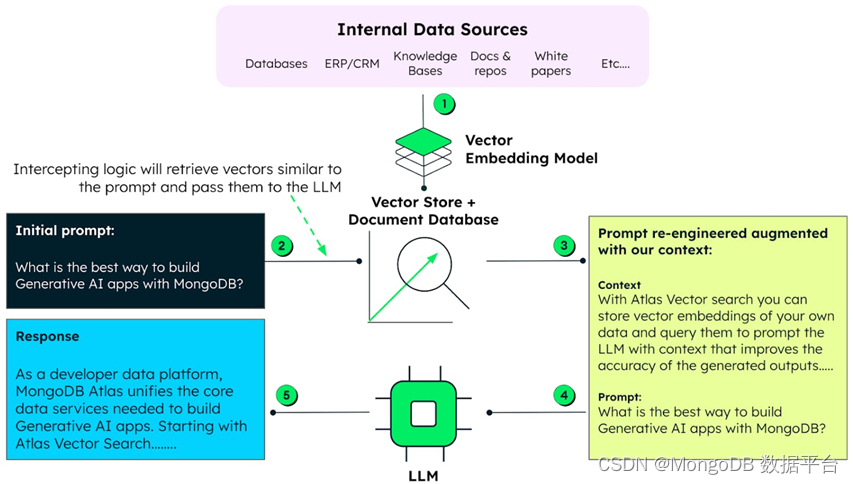
Vector Search 是一种基于语义或数据含义,而不是基于数据本身来查询数据的功能。这种功能的实现原理是,把任何形式的数据转换成数字向量,再用高级算法进行相互比较。
第一步是获取源数据,可以是文本、音频、图像或视频数据源,并使用“编码模型”将其转换为“向量”或“嵌入”。得益于人工智能的最新进展,这些向量现在能够将低维数据投影到包含更多数据上下文的高维空间,从而更准确地理解数据的含义。
一旦数据转换成数字表示,就可以使用“近似最近邻”算法查找相似的值,这种算法可以让查询非常快速地找到具有相似向量的数据。用户可以使用自然语言进行查询,例如:“推荐一些悲伤的电影”,或“找一些类似……的图片”。这项功能解锁了全新的可能性。
点击观看这两支视频,帮助你更好地了解Vector Search:
向量搜索:数据查询的未来|语义搜索
3分钟了解MongoDB Atlas向量搜索
MongoDB Atlas平台已原生内置向量搜索!
MongoDB Atlas 已原生内置此功能,开发者无需复制和转换数据、无需学习新的技术栈和语法,也无需管理一整套新的基础设施。借助 MongoDB 的 Atlas Vector Search,开发者可以在一个经过实战考验的出色平台中利用这些强大的新功能,以前所未有的速度构建应用。
有效使用 AI 和 Vector Search 所面临的许多挑战,都源于保证应用数据安全所涉及到的复杂性。这些繁琐的任务会降低开发效率,并让应用的构建、调试和维护变得更加困难。MongoDB 消除了所有这些挑战,同时将 Vector Search 的强大能力整合到平台中,无论面对什么样的工作负载,该平台都能灵活地纵向和横向扩展,轻松应对。
最后,如果没有安全性和可用性的保证,这一切都毫无意义。MongoDB 致力于提供安全的数据管理解决方案,通过冗余和自动故障转移保证高可用性,让应用始终稳定运行。
MongoDB.local 伦敦见面会发布的新功能
在 .Local 伦敦见面会上,我们很高兴地宣布推出专门的Vector Search 聚合阶段,它可以通过 $vectorSearch 调用。这个新的聚合阶段引入了一些新概念,增加了新的能力,使得 Vector Search 比以往任何时候都更容易使用。
借助 $vectorSearch,开发者还可以通过 MQL 语法使用预过滤器(如 g t e 、 gte、 gte、eq 等),以在遍历索引时过滤掉一些文档,从而获得一致的结果和更高性能。任何了解 MongoDB 的开发者都能够轻松使用此过滤功能!
最后,我们还介绍了在聚合阶段内部调整结果的两种方法,即“numCandidates”和“limit”参数。通过这些参数,开发者可以调整应该成为近似最近邻搜索候选者的文档数量,然后通过“limit”限制结果数量。
它如何与生态系统交互?
人工智能的发展日新月异,让人叹为观止,而开源社区的突飞猛进也令人赞叹不已。开源语言模型以及将它们集成到应用中的各种方法取得了巨大的进步。人工智能展现出了强大力量,因此,建立一个能够让开发者自由发挥的坚实抽象也变得前所未有地重要。基于这样的考虑,我们非常激动地告诉大家,LangChain 和 LlamaIndex 支持我们的多种功能,包括 Vector Search、聊天日志 (Chat Logging) 和文档索引等。我们正在快速推进,并将继续为主要提供商发布新功能。

总结
一切才刚刚开始,MongoDB 致力于提供优秀的开发者数据平台,助力开发者打造新一代 AI 赋能的应用。我们还会不断研究和支持更多的框架和插件架构。但始终不变的是,这一切的核心都是开发者。我们将与社区交流,找到最合适的服务方式,让开发者在每一步都感到满意。放手去创造吧!
MongoDB Atlas
MongoDB Atlas 是 MongoDB 公司提供的 MongoDB 云服务,由 MongoDB 数据库的开发团队构建和运维,可以在AWS、Microsoft Azure、Google Cloud Platform 云平台上轻松部署、运营和扩展。MongoDB Atlas 内建了 MongoDB 安全和运维最佳实践,可自动完成基础设施的部署、数据库的构建、高可用部署、数据的全球分发、备份等即费时又需要大量经验运维工作。让您通过简单的界面和 API 就可以完成这些工作,由此您可以将更多宝贵的时间花在构建您的应用上。
👉点击访问 MongoDB中文官网
👉立即免费试用 MongoDB Atlas
☎️需要支持?欢迎联系我们:400-8662988
✅欢迎关注MongoDB微信订阅号(MongoDB-China),及时获取最新资讯。
这篇关于Atlas Vector Search:借助语义搜索和 AI 针对任何类型的数据构建智能应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






