本文主要是介绍去雾笔记-Pixel Shuffle,逆Pixel Shuffle,棋盘效应,转置卷积,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.Pixel Shuffle
- 2.Inverse Pixel Shuffle
- 3.棋盘效应
- 4.转置卷积
- 5.宽激活块
- 6.PSPNet
- 7.反射填充层(Reflective Padding Layer)
- 8.tanh层
1.Pixel Shuffle
Pixel Shuffle是一种用于图像超分辨率的技术,它通过重新排列图像的像素来增加图像的分辨率。具体来说,Pixel Shuffle通常用于将低分辨率图像转换为高分辨率图像。Pixel Shuffle的原理是利用深度学习模型学习低分辨率图像到高分辨率图像的映射。在这种技术中,首先使用一个深度神经网络模型(通常是卷积神经网络)学习低分辨率图像和对应的高分辨率图像之间的映射关系。然后,通过该模型生成的高分辨率图像通常会比原始图像具有更高的分辨率。在生成高分辨率图像时,Pixel Shuffle通过一种特殊的像素重排方法来实现。通常情况下,这种像素重排方法会将原始图像的像素分组,并将每组像素按照一定的顺序重新排列,从而生成具有更高分辨率的图像。Pixel Shuffle技术的优点是可以通过深度学习模型来学习图像的复杂特征,从而生成更加逼真和细节丰富的高分辨率图像。这种技术在图像超分辨率、图像增强和图像生成等任务中有广泛的应用。
2.Inverse Pixel Shuffle
Inverse Pixel Shuffle是Pixel Shuffle的逆过程,它用于将低分辨率图像转换为高分辨率图像的过程中,对高分辨率图像进行还原,以恢复其原始的低分辨率表示。
Pixel Shuffle通常通过重新排列图像的像素来增加图像的分辨率。在这个过程中,像素被分组并按照一定的顺序重新排列,以生成高分辨率图像。Inverse Pixel Shuffle则是对这个过程的逆操作,它可以根据生成的高分辨率图像,恢复出原始的低分辨率图像。
Inverse Pixel Shuffle的目标是根据高分辨率图像,推断出在低分辨率图像中被合并或重排的像素。这个过程通常需要使用逆映射函数或反向操作来实现,以便恢复出原始的低分辨率图像表示。逆映射函数可以根据像素重排的顺序和分组方式,将高分辨率图像的像素还原到原始的低分辨率图像中。
Inverse Pixel Shuffle技术在图像超分辨率和图像重建等任务中有广泛的应用。它允许在高分辨率图像生成后,通过逆操作还原出原始的低分辨率表示,从而实现对图像分辨率的改变和重构。
3.棋盘效应
棋盘效应(checkerboard artifact)是指在图像生成或者图像转换任务中,由于使用不当的上采样方法(如转置卷积)而导致生成的图像出现棋盘状的方块状结构或者锯齿状边缘的现象。
棋盘效应通常发生在使用转置卷积(deconvolution)等上采样方法时。转置卷积是一种常用的上采样技术,它通过学习卷积核的参数来进行上采样操作。然而,当转置卷积的步长较大时,或者输入特征图的尺寸不是转置卷积步长的整数倍时,就容易出现棋盘效应。
这种效应的原因在于,转置卷积中的重叠区域(overlap region)由于重复上采样的操作而导致特征之间的冗余信息叠加,从而在生成图像中产生方块状结构或者锯齿状边缘。这会影响生成图像的视觉质量和真实感,并且降低了生成图像在视觉上的连续性和一致性。
为了避免棋盘效应,一些方法采用像PixelShuffle这样的特定上采样层,这些层具有更好的性质,能够在进行上采样时保持图像的平滑性和连续性,从而生成更高质量的图像。
4.转置卷积
转置卷积(transposed convolution),也称为反卷积(deconvolution),是一种常用的卷积神经网络中的操作,用于实现上采样或者反卷积操作。转置卷积的主要作用是将输入特征图进行放大,并将其转换为更高分辨率的输出特征图。
转置卷积的原理是在原始的卷积操作的基础上进行的。在卷积操作中,通过卷积核与输入特征图的滑动操作,生成输出特征图。而在转置卷积中,卷积核的权重被反转,并且输入和输出交换,这样可以实现输入特征图的放大操作。
转置卷积的步骤如下:
1.将输入特征图的每个像素值扩展为一个小矩阵,其中矩阵的大小与卷积核的大小相同。
2.对扩展后的输入特征图进行卷积操作,使用反转后的卷积核进行滑动。
3.将所有卷积操作的结果相加,得到输出特征图。
通过转置卷积操作,可以实现对输入特征图的放大和上采样。转置卷积常用于图像生成、图像超分辨率、语义分割等任务中,用于将低分辨率的输入特征图转换为高分辨率的输出特征图。然而,转置卷积操作可能会引入棋盘效应等问题,因此在一些情况下,人们会选择使用其他上采样方法,如双线性插值或PixelShuffle等。
5.宽激活块
“宽激活块”(Wide Activation Block)是一种深度神经网络中常用的模块或结构,用于构建具有较宽激活函数的神经网络。它的设计旨在增加神经网络的表示能力和学习能力,以提高模型在复杂任务上的性能。
宽激活块的主要特点是在卷积层后面添加了一个激活函数,通常是一个具有较大输出范围的激活函数,如ReLU(修正线性单元)的变种。相比于普通的激活函数,宽激活块中的激活函数具有更宽的范围,能够产生更大的激活值,从而增强了神经网络的非线性表达能力。
宽激活块的结构可以根据具体的任务和需求进行设计和调整,但通常包含以下几个组成部分:
- 卷积层(Convolutional Layer):负责从输入特征图中提取特征。
- 批量归一化层(Batch Normalization Layer):用于加速训练过程并提高模型的鲁棒性
- 激活函数(Activation Function):通常是一个具有较宽输出范围的激活函数,如Leaky ReLU、PReLU等
宽激活块的设计灵感来自于研究者对于激活函数对神经网络性能影响的探索。通过增加激活函数的输出范围,宽激活块能够提供更大的非线性性,从而帮助神经网络更好地拟合复杂的数据分布和学习任务。
总的来说,宽激活块是一种用于构建深度神经网络的常用组件,它能够增强神经网络的非线性表达能力,提高模型的学习能力和性能。
6.PSPNet
PSPNet(Pyramid Scene Parsing Network)是一种用于场景解析(Scene Parsing)的深度学习模型,旨在实现对图像中各个像素的语义分割。它是由香港中文大学的研究团队提出的,在2017年的CVPR会议上首次发布。
PSPNet的核心思想是通过金字塔池化(Pyramid Pooling)机制来捕获图像不同尺度上的语义信息,从而提高模型对于场景中不同对象和区域的识别能力。其主要特点包括:
- 金字塔池化(Pyramid Pooling):PSPNet在最后的特征提取层引入了金字塔池化模块,通过将输入特征图分为不同尺度的区域,并在每个区域上进行池化操作,从而捕获了图像在不同尺度上的语义信息
- 空洞卷积(Dilated Convolution):为了扩大感受野并保持分辨率,PSPNet使用了空洞卷积(也称为扩张卷积),这样可以在不增加参数数量的情况下提高模型的感知范围。
- 全局信息融合:金字塔池化模块将各个尺度上的特征进行拼接,并通过一个全局池化操作,将全局信息融合到最终的特征表示中,从而使模型能够更好地理解整个图像的语义信息。
PSPNet在图像语义分割任务上取得了很好的效果,并在多个基准数据集上达到了领先水平。由于其强大的语义分割能力和较高的性能,PSPNet在图像分割、场景理解和自动驾驶等领域得到了广泛的应用。
7.反射填充层(Reflective Padding Layer)
反射填充层(Reflective Padding Layer)是一种常用的神经网络层,用于在卷积操作中进行零填充(Zero Padding)。与普通的零填充不同,反射填充是通过反射图像边界的方式进行填充,以保持图像边缘的特征并减少卷积操作对图像边缘像素的影响。
反射填充层的原理是在图像边界的外部创建一个镜像的边界,并将其与原始图像进行连接。这样做的目的是为了使卷积核在图像边缘处能够接触到相对真实的像素值,而不会出现边界像素值被不合理地处理的问题。
反射填充层通常应用于卷积神经网络中的边缘检测、图像处理和图像分割等任务中,以避免边缘像素的信息丢失和卷积操作的边界效应。与普通的零填充相比,反射填充能够更好地保持图像边缘的特征,从而提高模型在边缘区域的表现和性能。
反射填充层在卷积神经网络的设计中发挥着重要作用,它能够有效地改善模型对图像边缘像素的处理,从而提高模型的准确性和鲁棒性
8.tanh层
tanh层是神经网络中的一种激活函数层,它的作用是将神经网络的输出值进行非线性映射,将其压缩到[-1, 1]的区间内。tanh函数的数学定义为:
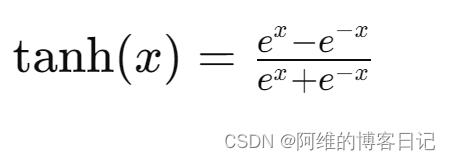
tanh函数在输入接近正无穷大时趋近于1,在输入接近负无穷大时趋近于-1,在接近0的位置时趋近于0。因此,tanh函数具有中心对称的S形曲线。
tanh函数的性质使得它在神经网络中被广泛应用。它比sigmoid函数更为常用,因为tanh函数的输出范围是[-1, 1],比sigmoid函数的输出范围[0, 1]更广,这有助于减轻梯度消失问题,并且可以使得输出的均值接近于0。
在神经网络的层次结构中,tanh层通常作为激活函数层出现在全连接层或者卷积层之后,用于增加网络的非线性表达能力。它能够提供神经网络更强的表示能力,从而增强模型的拟合能力和泛化能力。
这篇关于去雾笔记-Pixel Shuffle,逆Pixel Shuffle,棋盘效应,转置卷积的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









