本文主要是介绍【网络原理】UDP协议的报文结构 及 校验和字段的错误检测机制(CRC算法、MD5算法),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
UDP协议
UDP协议的报文结构及注意事项
UDP报文结构中的校验和字段
1. 校验和主要校验的内容
2. UDP校验和的实现方式
3. CRC(循环冗余校验)算法
4. MD5(Message Digest Algorithm 5)
UDP协议
上一篇文章提过,UDP(User Datagram Protocol,用户数据报协议)是一种无连接的、不可靠传输、面向数据报、全双工的传输层协议,用于在网络上发送数据。
UDP的各个特点已经介绍过了,接下来,基于UDP协议的报文结构,了解该协议的各个特性。
UDP协议的报文结构及注意事项
UDP 报文结构指的就是 UDP 数据报的结构。
UDP数据报 = 报头(重点) + 载荷(实际要传输的数据部分),如下图:
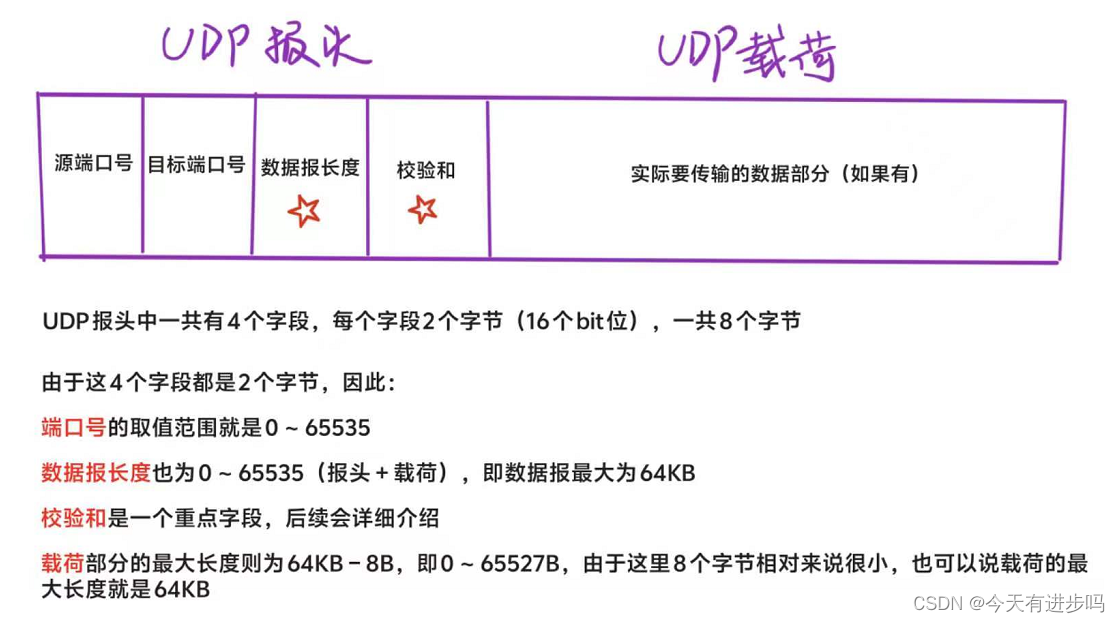
由于UDP的一个数据报的最大长度就是64KB,而64KB在当今的互联网环境下,是一个非常小的数字。
注意事项 如果我们需要传输的 UDP数据报 超过64KB,有以下解决方案:
- 将数据分割成多个 UDP数据报 进行发送传输,并在接收端进行重新组装。这种方式称为数据分段(Data Segmentation)或数据分片(Data Fragmentation)。
- 考虑使用其他的传输层协议,如 TCP 协议。如果需要传输大量数据或者超过 UDP 最大报文长度的数据,TCP 是更好的选择,这里暂时不详细展开。
UDP报文结构中的校验和字段
校验和,顾名思义,用于验证数据在传输过程中是否传输正确(是否发生了错误或损坏)
或者说,用于数据完整性检查,以确保数据在传输过程中没有被篡改或损坏。
1. 校验和主要校验的内容
-
数据内容: 校验和对数据报中的每个比特位进行求和计算,以确保数据内容在传输过程中没有被篡改或损坏。
-
传输过程中的错误: 校验和可以检测到数据在传输过程中是否发生了错误,例如比特翻转或数据丢失。
-
数据包的完整性: 通过与发送端发送的校验和进行比较,接收端可以验证数据包在传输过程中是否保持完整,即数据在发送端和接收端之间没有发生改变。
如果发现数据损坏或者被篡改,就丢弃这个数据。
2. UDP校验和的实现方式
UDP校验和使用的是一种简单的错误检测机制,它的实现方式如下:
-
计算校验和: 发送端在发送UDP数据包之前,会对UDP数据报文的内容进行校验和的计算。计算过程通常包括以下步骤:
- 将UDP数据报文划分为以16比特为单位的字(对于字节不足16比特的部分,可以补零)。
- 将这些16比特字相加,得到一个32比特的中间结果。
- 如果中间结果的高16比特不为0,则将其与低16比特相加,直到高16比特为0为止。
- 最终的校验和就是将最后的结果按位取反得到的值。
-
校验和字段: 发送端将计算得到的校验和值放置在UDP数据报的校验和字段中。
-
接收端验证: 接收端在接收到UDP数据包后,会进行校验和的验证。验证的步骤与计算过程类似:
- 接收端同样将UDP数据报文划分为16比特的字,并对其进行求和计算。
- 接收端将计算得到的校验和与UDP数据包中的校验和字段进行比较。
- 如果两者相等,则认为数据包未损坏;如果不相等,则认为数据包可能已经损坏。
这里使用一个生活场景帮助理解上述实现过程:
当你寄送一封信件给朋友时,你可能会希望确保信件在邮递过程中没有损坏或篡改。你可以在信封上添加一个简单的校验和来实现这一点。
- 想象你写了一封信给朋友,然后把它放进信封里。在你封上信封之前,你可以将信中每个字母的ASCII码值相加,然后取结果的模256(即求和结果除以256的余数),并将这个余数写在信封的背面。这个余数就是你的“校验和”。
- 当你的朋友收到这封信时,他可以打开信封并读取信的内容。然后,他也可以将信中每个字母的ASCII码值相加,然后取结果的模256。如果这个计算得到的余数与信封背面的校验和相同,那么他可以合理地假设信件在邮递过程中没有被篡改或损坏。
- 这个例子简化了UDP校验和的概念,帮助理解UDP校验和的基本原理:在发送数据之前计算一个简单的校验值,并在接收数据时验证这个校验值,以确保数据的完整性和准确性。
需要注意的是,UDP校验和并不提供数据的可靠性传输,它只能检测到一部分错误,并不能保证数据的完整性或可靠性。
- 就拿寄信的例子来解释,假设接收端接收到的信中的内容出现变化,如其中一个a->b,另一个b->a,但此时每个字母的ASCII码值相加再取模,得到的校验和仍然是相同的。
- 同理,UDP校验和仅仅对UDP数据报中的数据进行简单的加法和取反操作来计算校验和值。因此,接收内容不同但计算出的校验和值是相同的情况仍然是会出现的。
综上,UDP校验和虽然可以帮助检测部分错误,但它并不足以确保数据的完整性和可靠性。因此,在需要可靠传输的场景下,通常会选择使用TCP等其他协议。
除此之外,要想提高UDP的数据的完整性检查,还可以让UDP结合一些其他错误检测和纠正的机制进行校验,如CRC(循环冗余校验)算法、MD5算法、SHA-3算法、SHA-256算法等。这里简单介绍一下CRC算法和MD5算法。
3. CRC(循环冗余校验)算法
在某些情况下,为了检测数据传输过程中是否出现错误或数据损坏,可以使用CRC算法来生成校验码,并将其附加到UDP数据报中一起传输。具体如下:
- 发送端在发送UDP数据报之前,可以对数据进行CRC校验,生成校验码并将其添加到UDP数据报的尾部。
- 接收端在接收到UDP数据报后,可以执行相同的CRC算法来计算接收到的数据的校验码,并将其与接收到的校验码进行比较。
- 如果两者一致,则说明数据在传输过程中没有出现错误;如果不一致,则说明数据可能已经损坏或被篡改。
可以看到,此处我们也就是将UDP原有的校验码生成方式改为了使用CRC(循环冗余校验)的方式来生成校验码。具体CRC的工作原理,建议寻找其他资料进行了解。
4. MD5(Message Digest Algorithm 5)
首先,先重点认识一下MD5的特点:
-
固定长度输出: MD5生成的哈希值是固定长度的,为128位(16字节),无论输入消息的长度如何。
-
雪崩效应: 即使输入消息的微小改变也会导致输出哈希值发生巨大变化,这种性质被称为雪崩效应,增加了数据的安全性和完整性。
-
不可逆性: MD5是单向哈希函数,意味着从哈希值反推原始消息是困难的,几乎不可能通过哈希值还原出原始消息。
在某些情况下,MD5可以与UDP一起使用以提高数据的完整性检查。例如,在某些应用中,可以在UDP数据报中包含MD5哈希值作为校验字段,以便在接收端验证数据的完整性。这样,接收方可以计算接收到的数据的MD5哈希值,并将其与发送端附加在UDP数据报中的MD5哈希值进行比较,以确保数据在传输过程中没有被篡改或损坏。
我们随便使用一个搜索引擎,搜索MD5,就会有对应的MD5在线工具。
输入需要加密的内容,就可以得到MD5加密后的结果,这里中间有选项:32位大小写、16位大小写,这里的32位指的是32个字符,因为十六进制的形式表示一个字节需要两个字符。如果以二进制形式表示,则只需要16个字符。
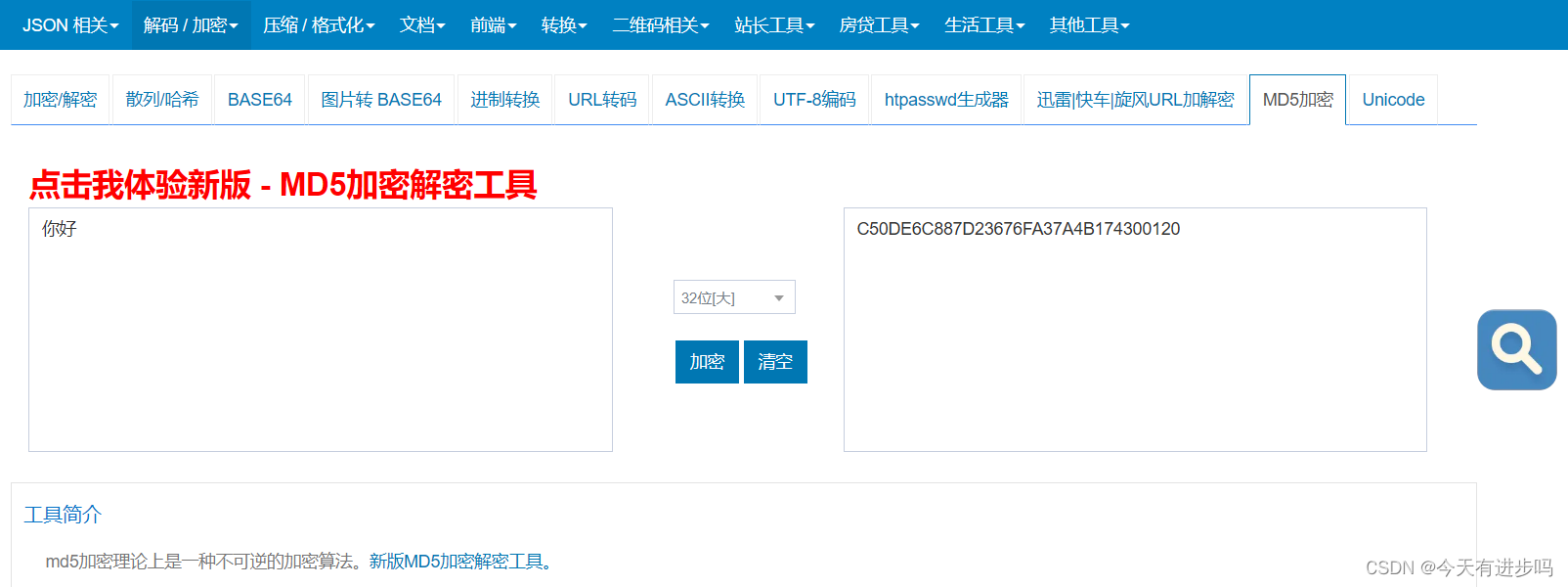
MD5理论上是不可逆的,而这里的在线解密,本质上都是通过“打表”的方式来完成,也就是我们调侃的面向结果编程。在线解密工具的服务器通过保存各种见过的字符串的MD5值到数据库中,当我们输入MD5值,就去数据库查,达成这种“解密”的效果。
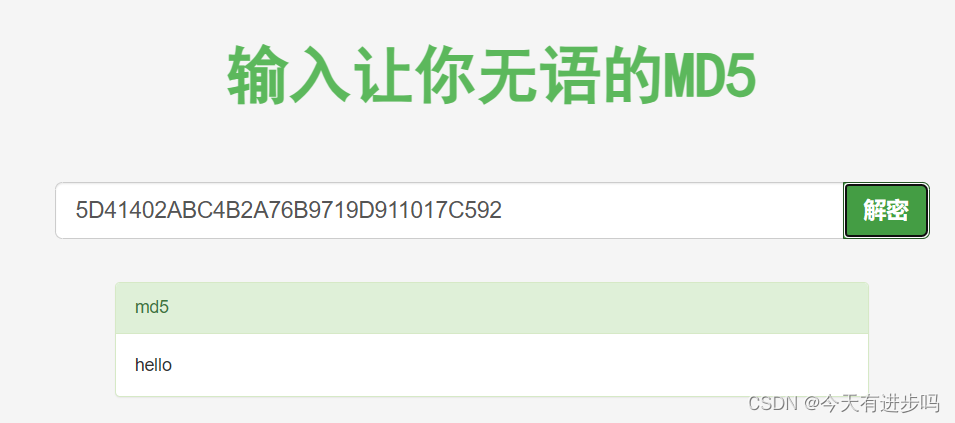
这种方式一般也只能破解出一些常见的字符串的MD5的值。https://www.somd5.com/ 这就是一个MD5在线解密的网站,我们观察一下面对常见字符串和较复杂字符串,它是否能成功解密。
解密 hello :
解密复杂字符串(今天天气不错):
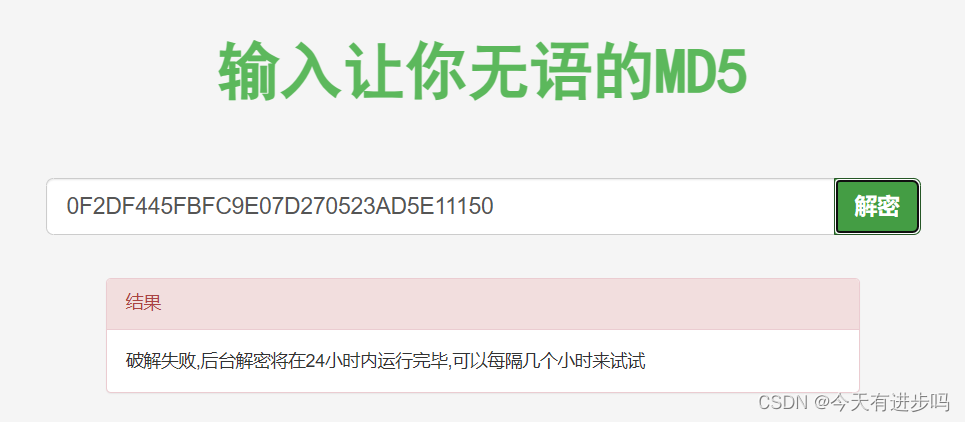
可以看到,只要稍微复杂点的字符串,这里的在线解密工具就无法解密了。
要注意的是,尽管MD5曾经被广泛使用于数据完整性验证、密码存储等领域,但由于其存在安全性漏洞和易受到碰撞攻击的特性,现在已经不再被推荐或使用在安全性要求较高的场景中。
MD5的安全性漏洞包括碰撞攻击(Collision Attack)和预影响攻击(Preimage Attack),这些攻击方式使得黑客能够生成具有相同MD5哈希值的不同输入,从而破坏了MD5的数据完整性验证功能。
因此,在现代应用中,更安全的哈希算法如SHA-256、SHA-3等已经取代了MD5的位置。这些算法具有更高的安全性和抗碰撞能力,被广泛用于密码存储、数字签名、消息认证等安全领域。所以,尽管MD5仍然存在,并且有些旧系统可能仍在使用它,但在新的安全应用中,推荐使用更强大和更安全的哈希算法。
这篇关于【网络原理】UDP协议的报文结构 及 校验和字段的错误检测机制(CRC算法、MD5算法)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!