本文主要是介绍YOLO_9000目标检测算法深度剖析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、何为YOLO_9000
二、9000种类的思考
三、引入WordTree
四、如何计算分类的损失
五、如何进行预测
六、相较YOLO_v2训练流程的改变
一、何为YOLO_9000
YOLO_9000是在YOLO_v2的基础上进行9000中目标的分类算法,其结构等都与YOLO_v2一致,唯一不同的就是分类地方,不再是原先的20位,而是具有更加多样性的9000种目标的分类,本文就将对YOLO_9000如何在YOLO_v2的基础上进行9000中目标分类的进行详细讲解。有关YOLO_v2内容请移步 YOLO_v2目标检测算法深入剖析。
二、9000种类的思考
众所周知,MNIST手写数字识别,Fashion-MNIST都是10分类的问题,VOC数据集也只有20种类,但是这些种类都有一个共同的特点,那就是各个种类之间是互不相关的,例如:1和4,裤子和鞋子,这些都是相互独立的东西,所以可以通过softmax进行分类,并能达到非常好的效果,但是如果分类的目标是,哈士奇,阿拉斯加,这种非常相近的目标的时候,显然使用softmax是非常不好的,因为哈士奇和阿拉斯加是有一部分共性的,那么这9000种种类中就存在着这样的问题,所以使用维度为9000的one-hot加上softmax是不合理的,那么我们到底该怎么办呢?
三、引入WordTree
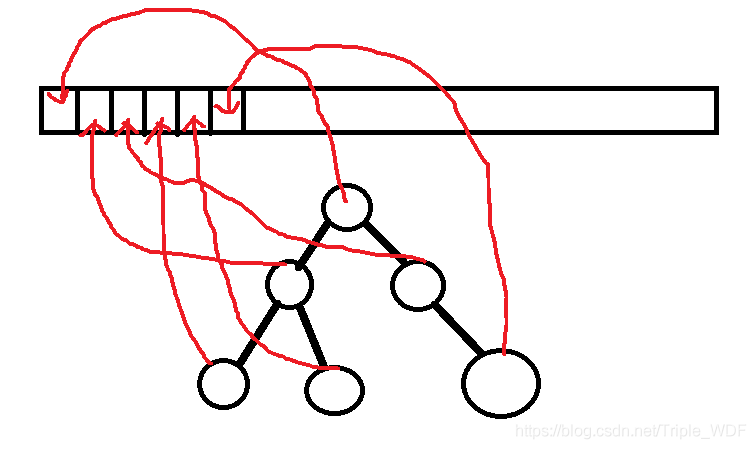
想必很多人都接触过赫夫曼编码,也就是用作压缩用的,需要构建赫夫曼树,其是二进制形式的,例如,一个单词的赫夫曼编码其可能是1011,这个就代表了这个单词。通过这个例子,我想此时就可以引出WordTree的思想了,看下图
图一就是一个Wordtree,根表示是个物体,然后物体可以分为动物和其他一些种类(机器,家具等等),然后动物分成了哺乳动物和其他(比如,卵生动物等等),然后继续细分,直到数据集中的所有物种种类都被包含在其中,现在这个Wordtree构建完了,那么该如何使用呢?
首先,虽然不是使用9000维度的one-hot形式进行softmax,但是分类所需要的维度依然是9000(虽然论文中是9418维度,但是这里去繁从简,定义为9000维度,不管维度是多少思想都是一样的),那么这个Wordtree总是可以按照一定的顺序进行遍历的,不管你是用BFS,还是DFS,到底是DFS中的先序、中序还是后序,只要你记住你是按照什么方式遍历的就可以,假如说你想要去找到dog这个物体,那么就是,physical object=1、animal=1、mammal=1、dog=1,除此以外的所有向量都是0,那么这个[1,1,1,1,0,0,0,...,0]就是dog的标签(这里的遍历顺序是假设的),可能cat就是[1,1,1,0,0,..,1,0,...,0],类似如此。总的来说就是,一个物体的细分路径上的点都要标记为1,如果一个物体由好几个路径可以到达,那么就选取从根节点到该物体最短的路径,以此来对其进行向量的标识。大体步骤参考下图二
四、如何计算分类的损失
通过本文的第三部分,我们知道了如何使用WordTree进行9000种类别的表示,那么一个最为关键的问题也出现了,如何去计算分类的损失呢?
YOLO_9000采用的方法是,对于Wordtree同一层的分类进行softmax,例如,如果对狗进行损失计算,那么需要找到“dog”父亲节点的所有儿子节点,也就是“dog”节点的兄弟姐妹节点,例如图中的cat,然后再对他们进行softmax来计算误差。根据图一,可以清晰的看出该思想,因为和“dog”同层的物体时可以找出的,所以可以通过对同层的物体物体进行softmax。这么做也为之后的预测埋下了伏笔。
五、如何进行预测
此时我们得到了一个9000维度的预测向量,那么我们就从根节点开始遍历,遍历的方向是前点的儿子中,概率最大的那个,然后一直向下,直到某个节点的儿子节点的概率低于设定的阈值,那么此时这个节点就是预测的节点。
六、相较YOLO_v2训练流程的改变
由于ImageNet样本比COCO样本多很多,所以对COCO的采样会多一些,然后两者的比例是4:1,由于最后输出的分类向量的维度很大,考虑到时间复杂度,所以YOLO_9000的每个网格中的预测框数量由YOLO_v2的5个降低为3个。
这篇关于YOLO_9000目标检测算法深度剖析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




